面试必看-基于JDK1.8的HashMap
Posted LuckyWangxs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试必看-基于JDK1.8的HashMap相关的知识,希望对你有一定的参考价值。
HashMap
一、HashMap基本知识
1. 简述
HashMap基于Map接口实现,元素以键值对的方式存储,key、value均允许存null,但key不允许重复,如果后者key与前者一样,前者的值将被后者覆盖;HashMap为无序集合,不能保证元素存储顺序,线程也不安全。
2. 继承关系
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
3. 基本属性
// 初始容量, 1左移4位相当于1*2^4=16, 该容量为Node<K,V>[]数组的长度
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 默认负载因子, 扩容使用
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 初始数组, 用来存放元素, 每一对键值对会被封装成一个Node对象放在该数组中
transient Node<K,V>[] table;
Node: 集合在扩容时非常消耗性能(因为元素放在数组当中,数组一旦创建,长度是不可变的,扩容只能遍历旧数组, 将旧数组的元素放到新数组,包括在旧数组位置上的链表或是红黑树的元素(1.8新特性,以前只是链表)
4. 遍历
forEach
Map<String, String> map = new HashMap<>();
map.put("name", "张三");
map.forEach((String k, String v) -> System.out.println(k + "-" + v));
增强for循环
Set<String> keys = map.keySet();
for (String key : keys)
System.out.println(map.get(key));
---------------------------或---------------------------
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry : entries)
System.out.println(map.get(entry.getKey()));
迭代器
Iterator<String> setIterator = map.keySet().iterator();
while (setIterator.hasNext())
System.out.println(map.get(setIterator.next()));
---------------------------或---------------------------
Set<Map.Entry<String, String>> entries = map.entrySet();
Iterator<Map.Entry<String, String>> iterator = entries.iterator();
while (iterator.hasNext())
System.out.println(map.get(iterator.next().getKey()));
values()
for (String value : map.values())
System.out.println(value);
二、HashMap与HashTabl的区别
1. 继承结构
HashMap继承自AbstractMap,实现Map接口;HashTable继承Dictionary,实现Map接口
2. 对待null
HashMap的key、value都可为null,HashTable的key、value都不可为null,原因如下代码
·HashMap的put方法
public V put(K key, V value) {
// 存值的时候调用hash方法对key进行hash计算
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
// 如果key为null, 则hash值返回0
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
· Hashtable的put方法
public synchronized V put(K key, V value) {
// 如果值为null, 则抛出空指针异常
if (value == null)
throw new NullPointerException();
Entry<?,?> tab[] = table;
// 没有对key进行限制, 直接调用了key的hashcode的方法, 如果key为null则也为空指针异常
// 从JDK文档中, 我们可以看出作者的想法, 他希望每个key都会实现hashcode和equals方法
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
// ...
}
3. 线程安全性
HashMap线程不安全,HashTable线程安全
Hashtable的线程安全是通过synchronized关键字实现的,且同步粒度比较大,为方法级的,在高并发环境下非常容易发生竞争,并发效率就会降低。所以相对而言,HashMap性能要更高一些的。如果需要并发环境,我们可以通过Collections.synchronizedMap()方法来获取一个线程安全的集合
笔记: Collections.synchronizedMap(Map<K,V> m)获取一个线程安全的集合,看源码,不难理解,本质上还是对传入map的操作,在Collections中定义了SynchronizedMap内部类,该内部类,使用synchronized关键字使线程安全
4. 初始容量与扩容
· HashMap
初始容量:16;负载因子:0.75
扩容机制:数组元素超过 数组容量 * 0.75取整,则容量翻倍,即capacity << 1
·Hashtable
初始容量:11;负载因子0.75
扩容机制:数组元素超过 数组容量 * 0.75,则容量翻倍并+1,即capacity << 1 + 1
扩容有两件事要做,第一件事就是创建新的Node<K, V>[ ]数组,长度为原始长度的2倍,第二件事需要对key再次计算元素存放于数组的位置,公式为 e.hash & (newCap - 1) ,称之为rehash,整个扩容过程对性能的开销也比较大。在JDK1.7采用头插法迁移数据,并发环境下,这块极容易出现环形链表的情况导致取值死循环;在JDK1.8采用尾插法迁移数据,只是单纯避免并发环境下扩容造成的环形链表从而引发死循环问题,但HashMap本身就是非同步的,这个优化倒也没那么重要,我们避免在多线程下使用就好。
5. 计算hash的方法
· HashMap
// 我们可以看到HashMap并没有直接用hashcode方法获取的哈希值, 而是又将哈希值无符号右移16位并和原来
// 的哈希值进行异或运算, 其目的是为了更好的散列
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// 计算数组位置
i = (n - 1) & hash
// 如果让我们计算, 可能会用 hash % n, 就像Hashtable那样计算, 其实这两者结果相同, 位运算效率更高
· Hashtable
// 直接调用hashcode()方法, 然后对数组长度取余算出元素存放位置
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
三、HashMap数据存储结构
1. JDK1.8之前
HashMap的数据结构是数组+链表的方式存储数据结构,首先有一个Entry<K, V>[ ]数组,Entry<K, V>则是一个链表,元素在放入HashMap时都会被封装成一个Entry对象放到数组里,如果哈希冲突,那么在数组同一位置,用链表存放。
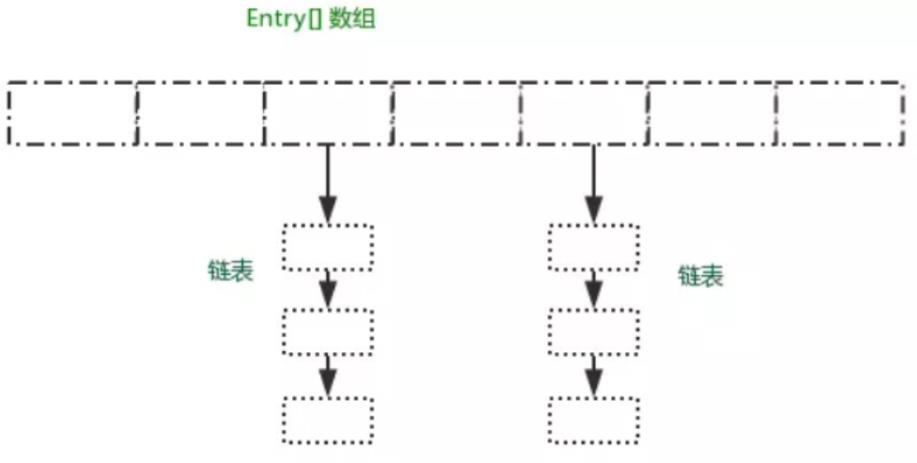
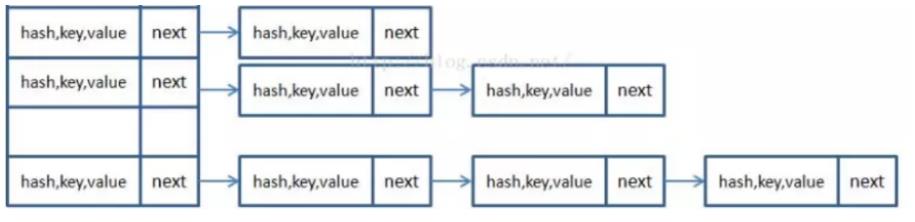
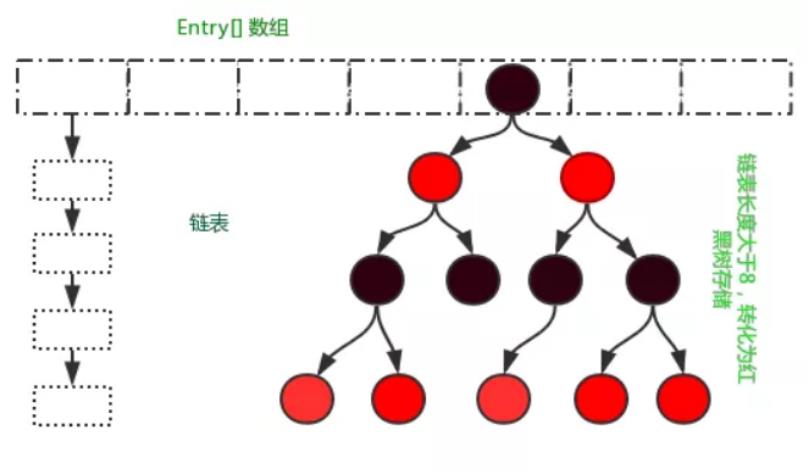
2. JDK1.8时
HashMap的数据结构为数组+链表+红黑树,首先是一个Node<K, V>[ ]数组,Node<K, V>是一个链表,还有一个TreeNode<K, V>,它是Node<K, V>的子类。元素放入HashMap时会被封装成一个Node对象,如果哈希冲突,会以链表的方式存放在数组同一位置,与JDK1.7及以前一样,如果链表长度超过阈值8时,则会将链表替换为红黑树,在性能上得到进一步提升。
3. put方法剖析
public V put(K key, V value) {
//调用putVal()方法, hash(key) 计算哈希值, 上述提到过
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断初始数组是否进行过初始化, 如果没有则初始化,
//resize即为初始化方法, 也为扩容方法
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//计算存储的索引位置, 如果没有元素, 直接赋值
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//节点若已经存在,执行赋值操作
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//判断当前节点是否是红黑树
else if (p instanceof TreeNode)
//若为红黑树, 则执行红黑树对象放入元素方法
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//若为链表, 则遍历链表, 放在链表末端, 若长度大于阈值, 将链表改为红黑树结构
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//链表长度8,将链表转化为红黑树存储
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//key存在,直接覆盖
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//记录修改次数
++modCount;
//判断是否需要扩容
if (++size > threshold)
resize();
//空操作
afterNodeInsertion(evict);
return null;
}
四、拓展
1. Hash冲突?
Hash值相同,即为hash冲突,在HashMap中,我们知道,put一个元素,要先算出hash值,然后根据hash值与数组长度得到存放位置,如果put一个元素,所得到的hash与集合中原有的hash相等,那么则hash冲突。
如果hash冲突,HashMap回去判断key与冲突的那个元素的key是否==,或者是否equals,如果相等,则覆盖原来的值,如果不相等,则以链地址法解决hash冲突。也就是数据结构里的链表。
2. Hash冲突的解决办法
1. 链地址法
即用一个链表存放Hash冲突的元素
2. 再哈希法
顾名思义,当hash冲突是,在原有的hash值上二次hash,如果还冲突,继续hash,直到不冲突为止
3. 开放定址法
4. 建立公共溢出区
五、结语
集合是比较重要的一块知识点,面试中会经常问到,平时工作中也经常会用到,希望大家可以多学习,多剖析,多比较各种集合的性能以及实现差异。此外,Java集合体系是Java类与类之间关系的完美体现,例如继承is-a,强调从属关系,实现like-a,强调功能,举例:HashMap,继承了AbstractMap,说明它是一个map集合,实现了Map、Cloneable、Serializable三个接口,强调了它有Map接口的功能,能够被克隆,能够序列化,大家不妨也研究研究。
本文多有参考一篇基于1.7的博客,后又更新过一次:https://blog.csdn.net/qq_41345773/article/details/92066554
以上是关于面试必看-基于JDK1.8的HashMap的主要内容,如果未能解决你的问题,请参考以下文章