自用文本分类 -> 特征提取方法
Posted 王六六的IT日常
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自用文本分类 -> 特征提取方法相关的知识,希望对你有一定的参考价值。
根据我们组大神发给我的学习资料做成的一个笔记,方便自己进行复习~~~~~~~
前言
参考 :知乎 — 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
如果我们想让计算机学习到我们的语言,至少需要先教会它们词汇和语法,也就是 提取词汇和语法所蕴含的特征,再使它们理解每句话的含义。
就目前而言词汇可以转变为向量,即 词向量,让计算机学习。而用何种算法转化为向量仍是一个值得讨论的问题。
当前已经有了诸多的转化方法,主要分为 静态词向量(上下文无关) 和 动态词向量(上下文相关) 两大类。
当计算机得到词向量后,才算作学会了词汇和语法,此时才可以按我们的意愿,使计算机对不同的文本进行不同的操作。
接下来的内容,分为 预备知识 、 词嵌入模型 和 预训练语言模型 。对于 预备知识 而言,将会介绍静态词向量。而 词向量模型 将会介绍能更好生成静态词向量的若干个经典模型。对于 预训练语言模型 来说,将会用来解决词向量模型生成的向量不能随着上下文而改变的问题,即多义词(动态词向量)的问题及其它问题。
--------- 预备知识 ---------
1.词嵌入(Word Embedding)
2.2.1 Word Embedding 介绍
参考: word2vec详解(一)
首先,在使用one-hot的时候,可能会导致维度爆炸。其次,使用one-hot的时候,所有的词之间的距离相同,实际上,相似的词更有可能出现在相同的上下文中。如使用one-hot表示时,人和猫、狗之间的距离相等,这个在实际上是不符合要求的,而word embedding可以解释上面的问题。
什么是word embedding呢?如果将word看作文本的最小单元,可以将Word Embedding理解为一种映射,其过程是:将文本空间中的某个word,通过一定的方法,映射或者说嵌入(embedding)到另一个数值向量空间。
更易理解的方式是采用更加紧凑的方式来避免维度爆炸,如下面一张图:
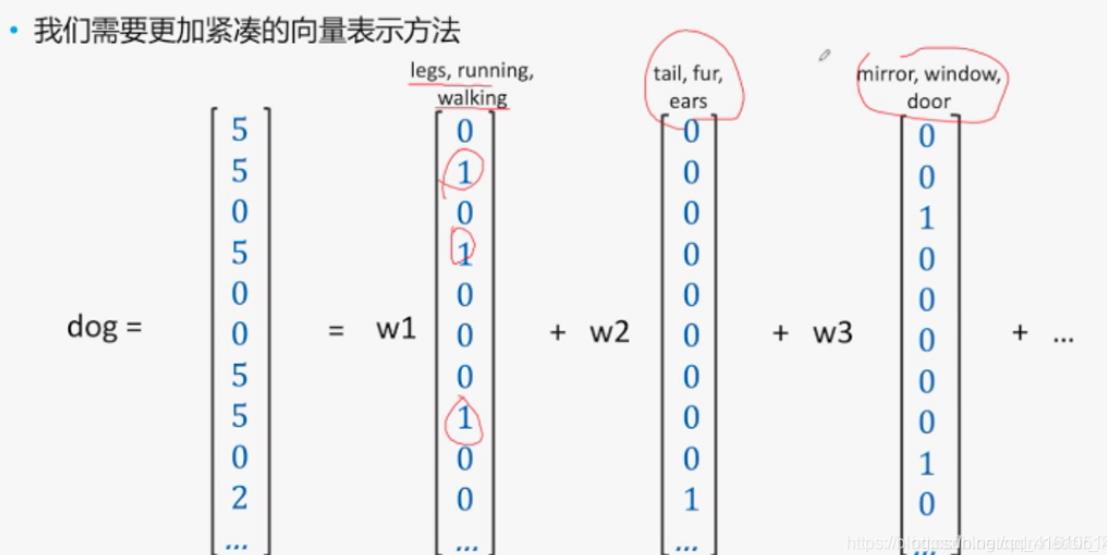
经过这样的表示后,我们的dog就可以表示为dog=[w1,w2,w3…],其中基向量[w1,w2,w3…]可以采用PCA之类的方式获取。
Word Embedding主流有以下两种:
基于频率的Word Embedding(Frequency based embedding)
基于预测的Word Embedding(Prediction based embedding)
将词向量表示为对单词的一种映射,而将词嵌入当作实现词向量的一种或多种方法。
2.2.2 基于频率的Word Embedding
(1) 词袋模型(Bow)
比如有一句话:today is a good day, tomorrow is a bad day.就可以基于这句话构建一个词袋:“today”、“is”、“a”、“good”、“day”、“tomorrow”、“bad”。然后就可以根据词袋中的元素在句子中出现的次数,用矩阵去表示这句话:[1 2 2 1 2 1 1]
统计词频有时候对情感的表达是有用的,比如一个句子里面出现了很多次good,如果不考虑它出现次数而只是用1表示它出现过,就无法准确表达句子的情感,会对文本分类等问题造成偏差。
另外,这种无序表示方法有点像小时候学习语文做的练习题,给出一堆无序的词语,比如"去哪里"、“明天”、“你”,然后做排序,就可以得到"你明天去哪里"。这时候,其实不论是有序还是无序,都能猜出句子的意思,所以像这种通过矩阵表示一个句子的方式是可行的。
但是词袋的缺点也很明显,当词汇量增大时,对于每句话用到的词最多还是十来个,于是就导致了每句话的矩阵都是稀疏的,严重影响了内存和计算资源。
除此之外,因为词袋是基于一个个独立的单词的,在一个句子中没有考虑到词与词之间的顺序和联系,所以在部分情况下可能会导致句义表达不准确,比如"你打了我"和"我打了你",虽然意思相反但是通过词袋模型表达都是一样的。
词袋模型的局限性
虽然词袋模型简单易用并且在实际应用中取得了很大的成功,但是词袋模型本身也具有局限性:
- 词汇表的构建:词汇表的建立和维护都值得考量,不合理的词汇表将导致文档表示向量的稀疏问题显著。
- 稀疏问题:词袋模型有一个原生问题就是向量的稀疏,这将对计算资源和推理带来巨大的挑战
- 语义:因为词袋模型没有考虑到语序,但是往往语序又蕴含着不同的语义信息。
(2) 词袋模型的改进(N-gram 模型)
在介绍N-gram之前,让我们回想一下“联想”的过程是怎样发生的。如果你是一个玩LOL的人,那么当我说“正方形打野”、“你是真的皮”,“你皮任你皮”这些词或词组时,你应该能想到的下一个词可能是“大司马”,而不是“五五开”。如果你不是LOL玩家,没关系,当我说“上火”、“金罐”这两个词,你能想到的下一个词应该更可能“加多宝”,而不是“可口可乐”。
N-gram正是基于这样的想法,它的第一个特点是某个词的出现依赖于其他若干个词,第二个特点是我们获得的信息越多,预测越准确。
我们每个人的大脑中都有一个N-gram模型,而且是在不断完善和训练的。我们的见识与经历,都在丰富着我们的阅历,增强着我们的联想能力。
N-gram模型是一种语言模型(Language Model,LM),语言模型是一个基于概率的判别模型,它输入的是一句话(单词的顺序序列),输出的是这句话的概率,即这些单词的联合概率(joint probability)。
(3) TF-IDF 算法
参考: TF-IDF算法介绍及实现
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF是词频(Term Frequency)
词频(TF)表示词条(关键字)在文本中出现的频率。 这个数字通常会被归一化(一般是词频➗文章总词数), 以防止它偏向长的文件。
同义公式如下:
IDF是逆向文件频率(Inverse Document Frequency)
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目➗包含该词语的文件的数目,再将得到的商取对数得到。
如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
同义公式如下:
TF-IDF实际上是:TF * IDF
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。
因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
同义公式如下: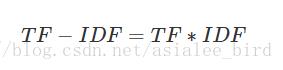
TF-IDF的局限性
TF-IDF算法实现简单快速,但是仍有许多不足之处:
(1)没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的。
(2)按照传统TF-IDF,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键词。
(3)传统TF-IDF中的IDF部分只考虑了特征词与它出现的文本数之间的关系,而忽略了特征项在一个类别中不同的类别间的分布情况。
(4)对于文档中出现次数较少的重要人名、地名信息提取效果不佳。
(4) TF-IDF 算法的改进(TF-IWF 算法)
在本质上 IDF 是一种试图抑制噪音的加权,并且单纯地认为文本频率小的单词就越重要,文本频率大的单词就越无用。这对于大部分文本信息,并不是完全正确的。IDF 的简单结构并不能使提取的关键词,十分有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能。尤其是在同类语料库中,这一方法有很大弊端,往往一些同文本的关键词被掩盖。例如:语料库 D 中教育类文章偏多,而文本 j 是一篇属于教育类的文章,那么教育类相关的词语的 IDF 值将会偏小,使提取文本关键词的召回率更低。
TF-IDF算法公式: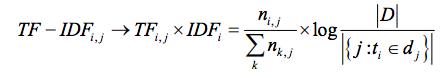
TF-IDF 改进算法 TF-IWF (Term Frequency-Inverse Word Frequency),将文本逆频率更换成词语逆频率,使其权值更能表达每个词语在语料库中的重要程度。
TF-IWF算法公式: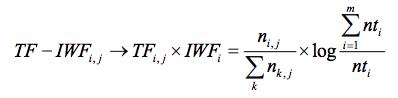
新的 TF-IWF 算法中,将IDF 转换为 IWF,将词频比作为文本候选关键词去噪音的权值,有效的抑制了与测试文本同类语料库对所提取关键词权重的影响,修正了 TF-IDF 算法的偏差。
(5) 共现算法(Co-Occurence)
参考:【简书】Word Embedding的发展和原理简介 、理解GloVe模型(+总结)及评论
自然语言一大特色是语义和上下文。有如下著名的研究结果:相似的单词趋向于有相似的上下文(context)。举例:
那个人是个男孩。
那个人是个女孩。
男孩和女孩从概念上来说相似,他们也具有相似的上下文。根据如上思想,我们可以构建一套算法,来实现基于上下文的特征构建。
这里需要引入两个概念:
Context Window:
上面我们提到了context,但context的长度需要有一个界定,也就是说,对于一个给定的word,需要有一个Context Window大小的概念。
如果指定Context Window大小为2,范围为前后两个word,那么对于such这个词,它的Context Window如上图所示。
Co-Occurence(共现):
有了Context Window的概念,Co-Occurence就好理解了。对于such这个单词来说,在其上下文窗口内,它分别与[she, is, a, beautiful]这四个单词各出现了一次共现。如果我们在语料库中所有such出现的地方,计算其共现的单词,并按次数累加,那么我们就可以利用其上下文范围内的单词来表示such这个词,这就是Co-Occurence Vector的计算方法。
假设有如下语料库:
He is not lazy. He is intelligent. He is smart.
如果Context Window大小为2,那么可以得到如下的共现矩阵: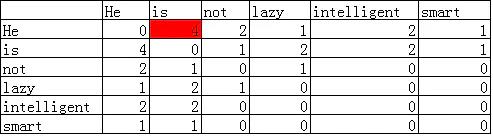
我们可以看看He和is的共现次数4是如何计算出来的:
显然地,直接使用共现矩阵,也会存在维数过大的问题,通常可以采取矩阵分解等手段来进行降维优化,在此不做深入讨论。
共现矩阵最大的优势是这种表示方法保留了语义信息,例如,通过这种表示,就可以知道,man和woman是更加接近的,而man和apple是相对远的。相比前述的两种方法,更具有智能的味道。
在之后的GloVe模型中,仍会提到共现算法。
2.2.3 基于预测的Word Embedding
CBow 模型和skip-gram 模型将在word2vec处介绍
2.2.4 Word Embedding 评价
优点:
(1)相对于one-hot,能够产生稠密的向量,避免维度爆炸;
(2)词之间的距离可以表示出来(词之间的相似度);
(3)可以作为词的特征去帮助解决其他的问题,如文本分类,命名实体识别、语义分析等。
局限性:
(1)向量的可解释性不强,没有one-hot那样明确的表示意义。
以上是关于自用文本分类 -> 特征提取方法的主要内容,如果未能解决你的问题,请参考以下文章