Kafka
Posted 亿钱君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka相关的知识,希望对你有一定的参考价值。
Kafka
第 1 章 Kafka 概述
1.1 定义

1.2 消息队列
1.2.1 传统消息队列的应用场景
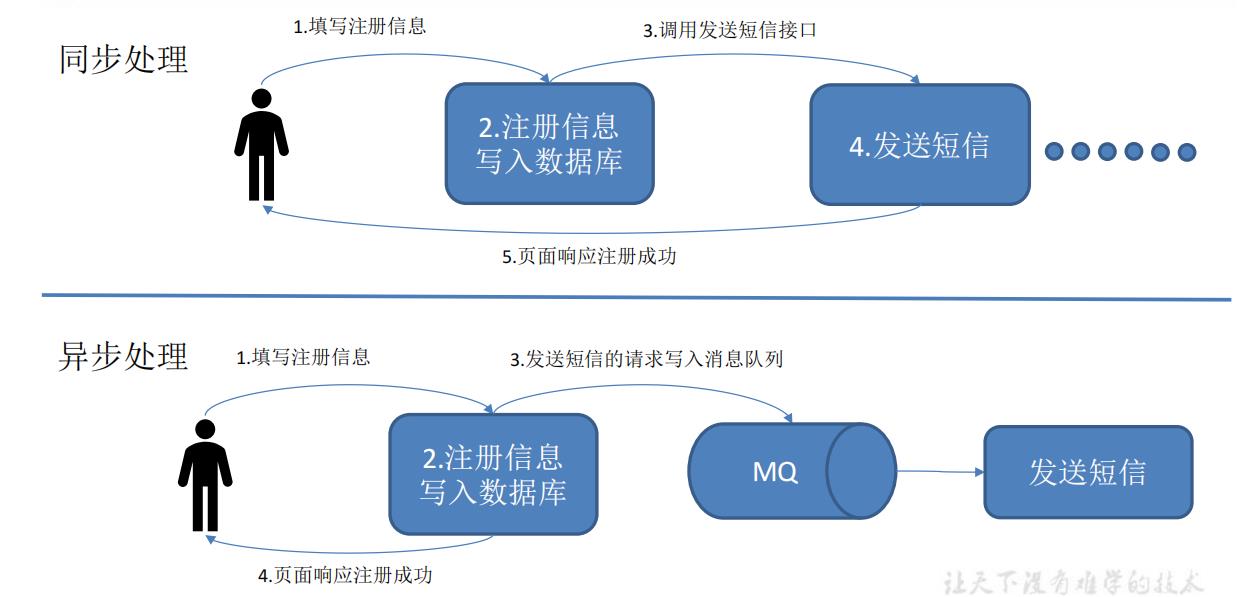
使用消息队列的好处
- 1)解耦(主要)
- 2)可恢复性
- 3)缓冲
- 4)灵活性 & 峰值处理能力(主要)
- 5)异步通信
1.2.2 消息队列的两种模式
-
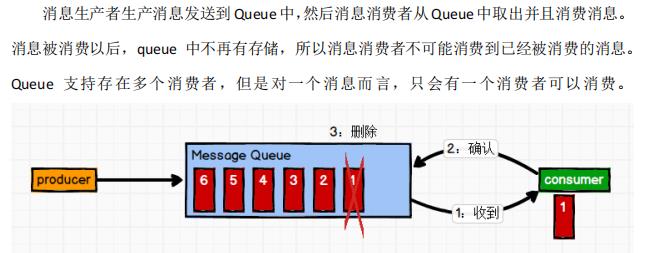
(1)点对点模式(一对一,生产者发送消息到Queue中,消费者主动从中拉取数据,消息收到后消息清除)
-
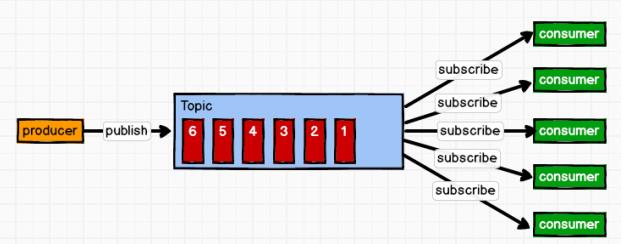
(2)发布/订阅模式(一对多,生产者将消息发布到 topic 中,消费者消费数据之后不会清除消息,发布到 topic 的消息会被所有订阅者消费)队列主动推数据
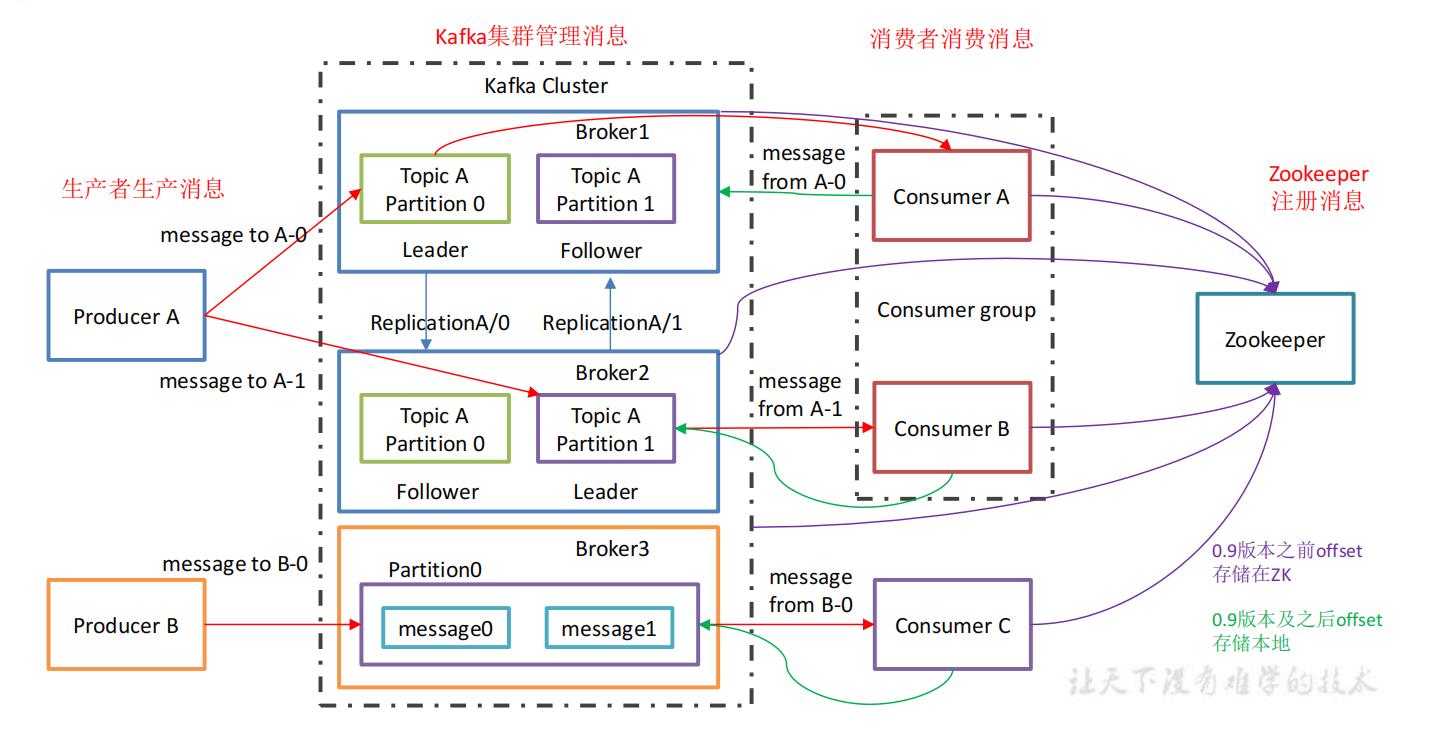
1.3 Kafka 基础架构

第 2 章 Kafka 快速入门
2.1 安装部署
2.1.1 集群规划

2.1.3 集群部署
1)解压安装包
[atguigu@hadoop102 software]$ tar -zxvf kafka_2.11-0.11.0.0.tgz -C
/opt/module/



8)kafka 群起脚本:kk.sh(脚本在 /home/atguigu/bin目录下)
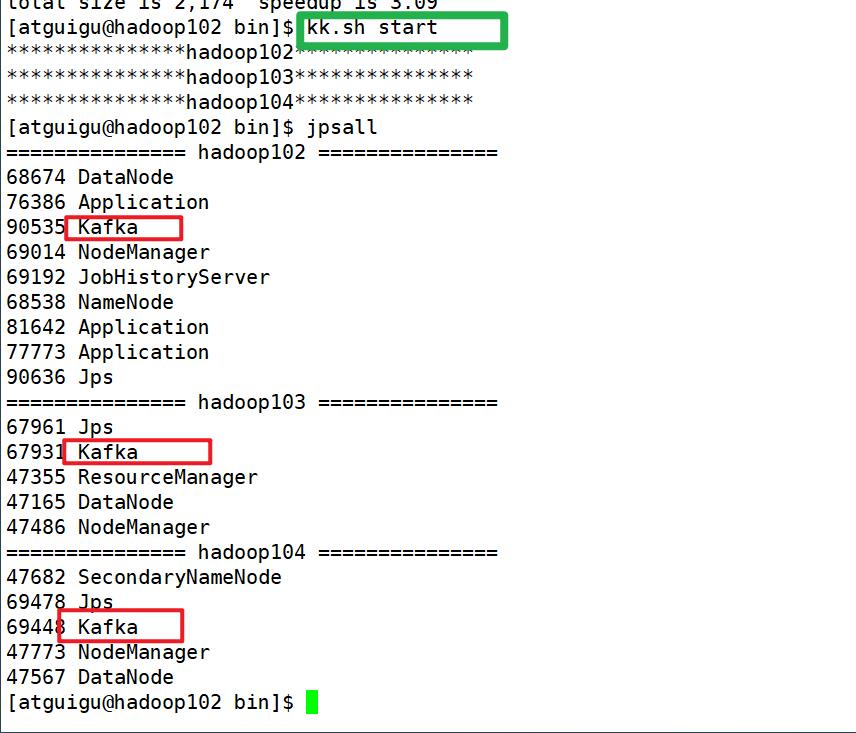
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo "***************$i***************"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo "***************$i***************"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh /opt/module/kafka/config/server.properties"
done
}
esac
2.2 Kafka 命令行操作
注意:操作kafka前,需要启动zookeeper:
[atguigu@hadoop102 zookeeper-3.4.10]$ bin/zkServer.sh status
1)查看当前服务器中的所有 topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --list --zookeeper hadoop102:2181

2)创建 topic
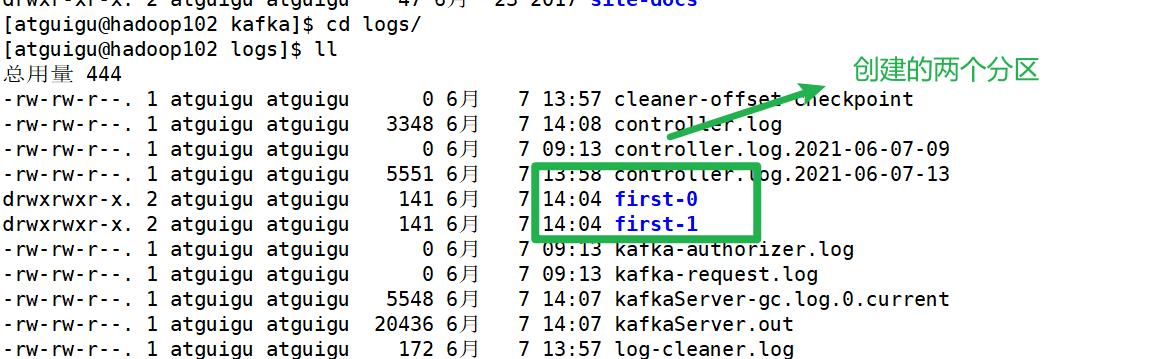
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --create --zookeeper hadoop102:2181 --topic first --partitions 2 --replication-factor 2
Created topic "first".


3)删除 topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --delete --zookeeper hadoop102:2181 --topic first

需要 server.properties 中设置 delete.topic.enable=true 否则只是标记删除
4)查看某个 Topic 的详情
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --describe --topic first --zookeeper hadoop102:2181

注意:副本创建数本能超过集群机器数

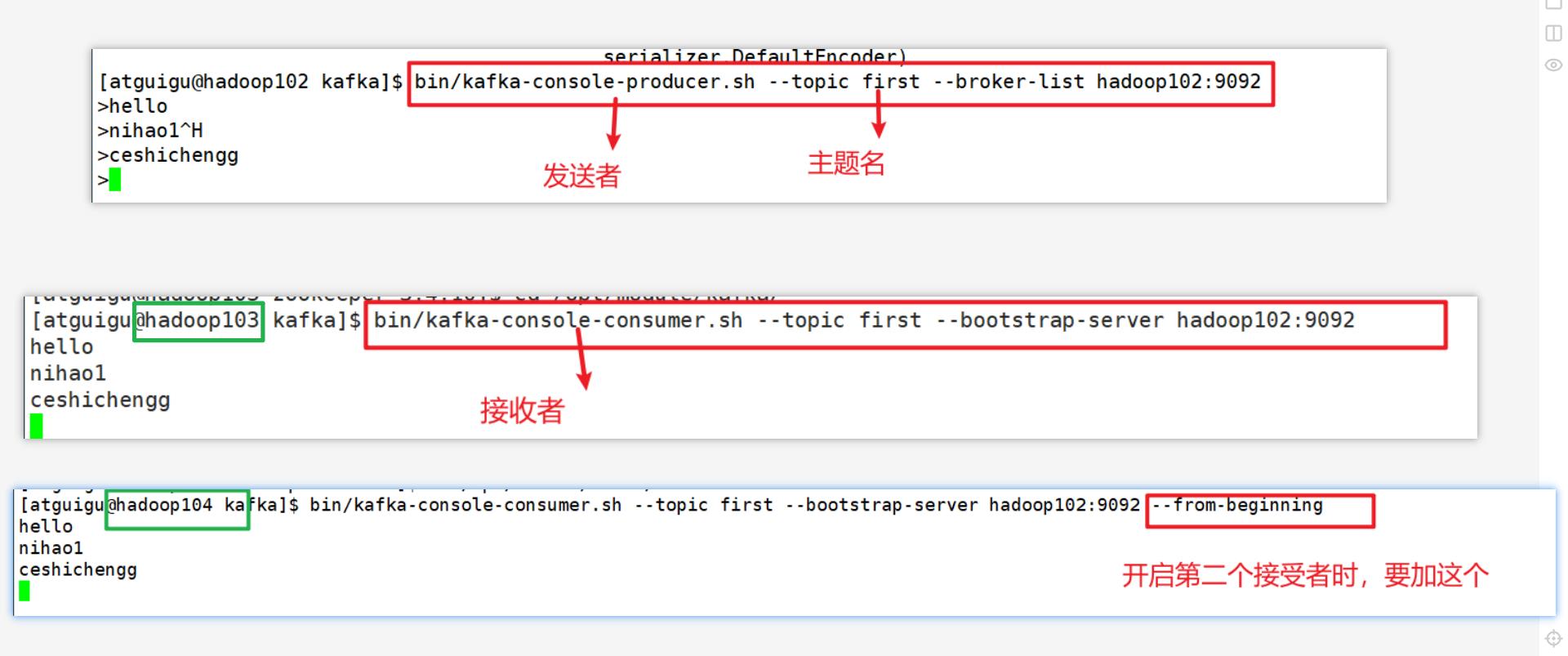
5)发送消息
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh --topic first --broker-list hadoop102:9092
>hello
>nihao1^H
>ceshichengg
>
6)消费消息
[atguigu@hadoop103 kafka]$ bin/kafka-console-consumer.sh --topic first --bootstrap-server hadoop102:9092
hello
nihao1
ceshichengg
[atguigu@hadoop104 kafka]$ bin/kafka-console-consumer.sh --topic first --bootstrap-server hadoop102:9092 --from-beginning
hello
nihao1
ceshichengg
**–from-beginning:会把主题中以往所有的数据都读取出来**,不加只会读取最新发送的消息
注:七天内发送的消息都可以被消费者消费出来,七天过后,被删除
第 3 章 Kafka 架构深入
3.1 Kafka 工作流程及文件存储机制
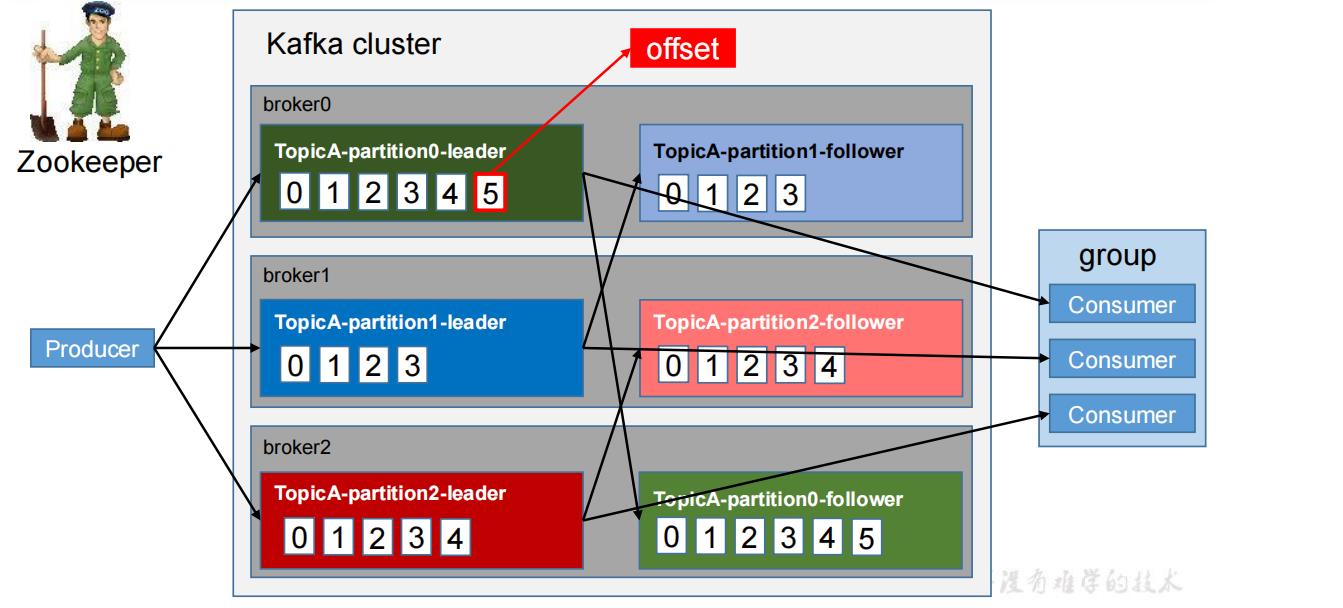
- Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic
的。 - topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文
件,该 log 文件中存储的就是 producer 生产的数据。Producer 生产的数据会被不断追加到该log 文件末端,且每条数据都有自己的 offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。
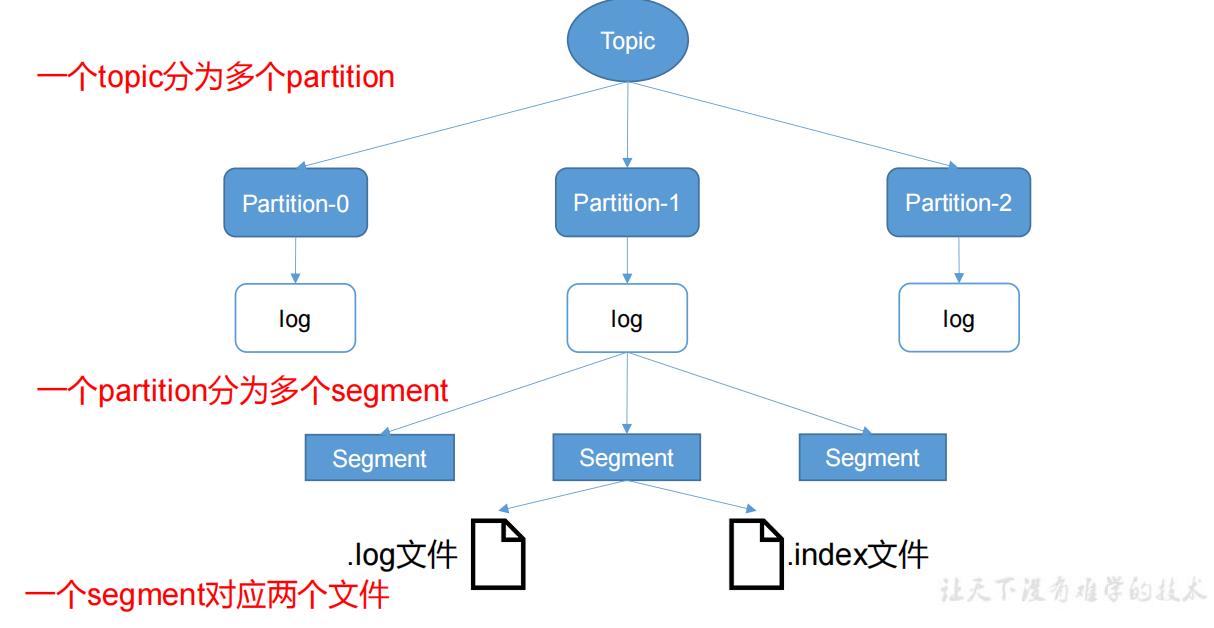
- 由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位效率低下,
- Kafka 采取了分片和索引机制,将每个 partition 分为多个 segment。每个 segment对应两个文件——“.index”文件和“.log”文件。
- 这些文件位于一个文件夹下,该文件夹的命名规则为:topic 名称+分区序号。例如,first 这个 topic 有三个分区,则其对应的文件夹为 first-0,first-1,first-2。

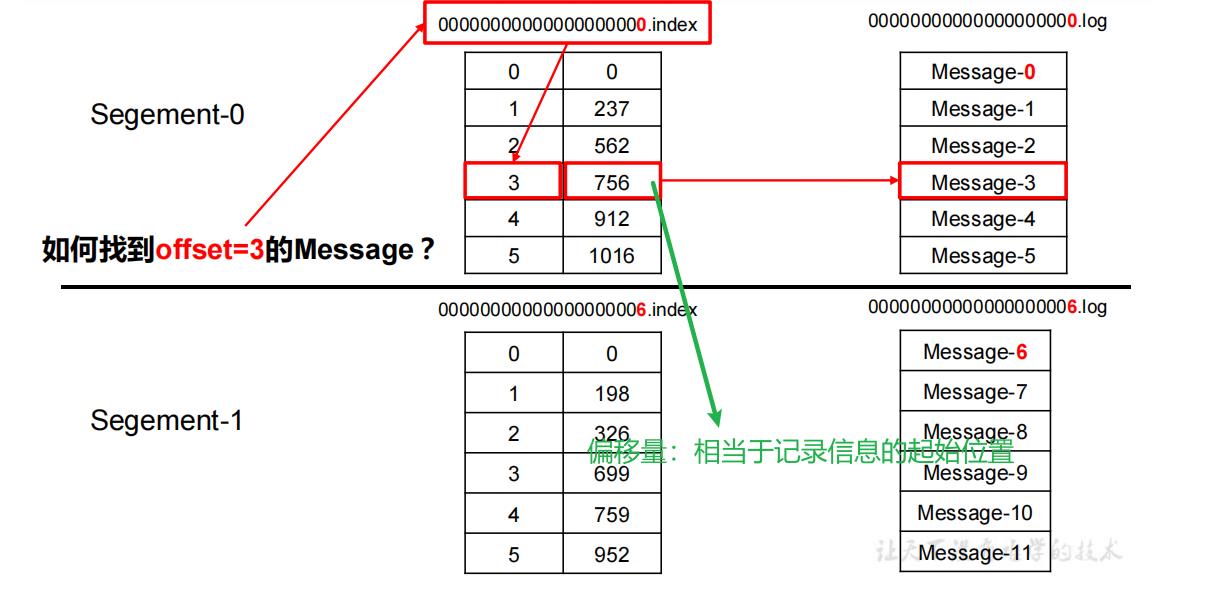
“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中 message 的物理偏移地址。
3.2 Kafka 生产者
3.2.1 分区策略(封装成ProducerRecord 对象)

3.2.2 数据可靠性保证

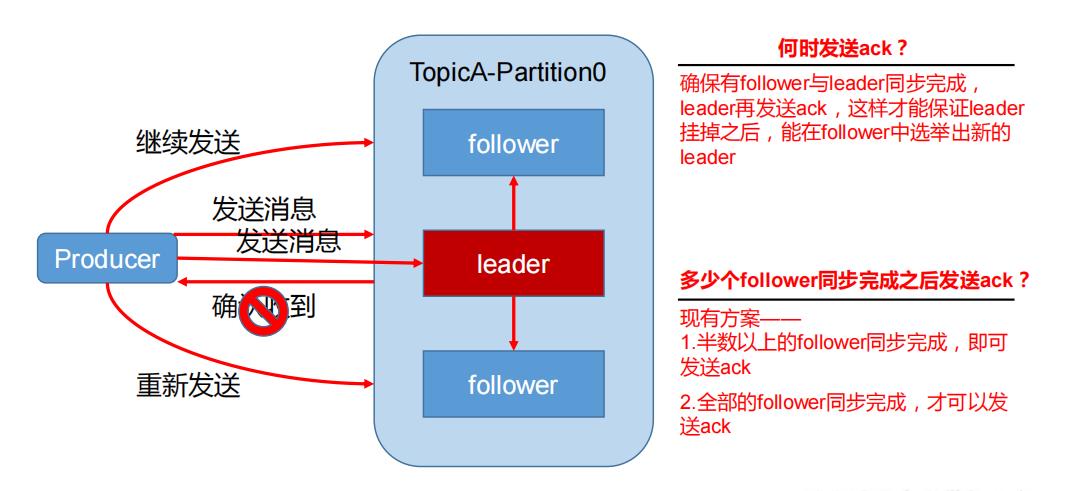



4)故障处理细节
略
3.2.3 Exactly Once 语义
略
3.3 Kafka 消费者
3.3.1 消费方式

3.3.2 分区分配策略
1)RoundRobin:轮循
2)Range:默认分配策略
3.3.3 offset 的维护

1)修改配置文件 consumer.properties

2)读取 offset
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper hadoop102:2181 --formatter "kafka.coordinator.group.GroupMetadataManager\\$OffsetsMessageForm atter" --consumer.config config/consumer.properties --from-beginning
略,
3.3.4 消费者组案例

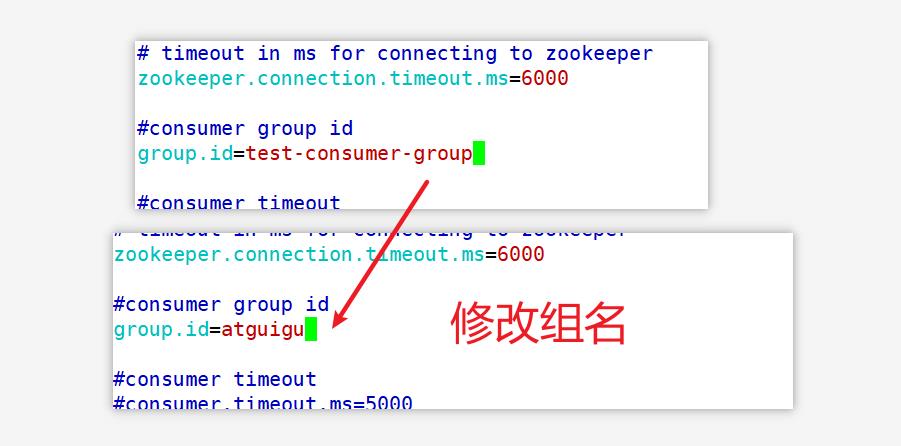
(2)在 hadoop102、hadoop103 上分别启动消费者
(3)在 hadoop104 上启动生产者
(4)查看 hadoop102 和 hadoop103 的接收者。
同一时刻只有一个消费者接收到消息(难测试,因为数据量较小,同一时刻时间很短,看看不出来)。
3.4 Kafka 高效读写数据(了解即可)
1)顺序写磁盘
2)零复制技术
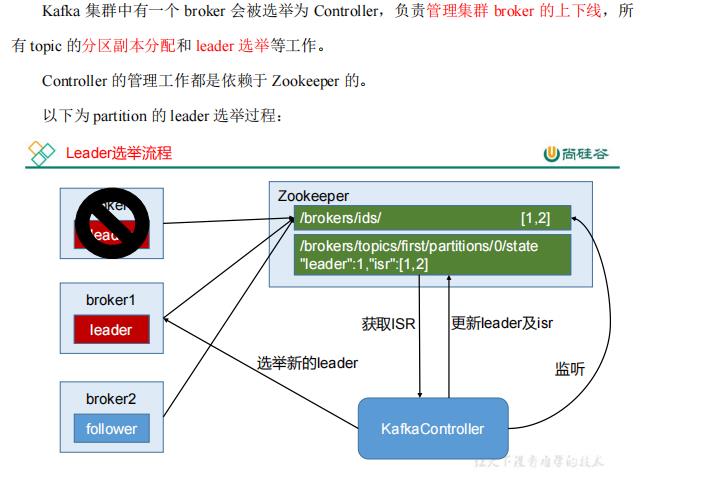
3.5 Zookeeper 在 Kafka 中的作用(了解即可)
3.6 Kafka 事务
略
第 4 章 Kafka API(重点)
4.1 Producer API
4.1.1 消息发送流程

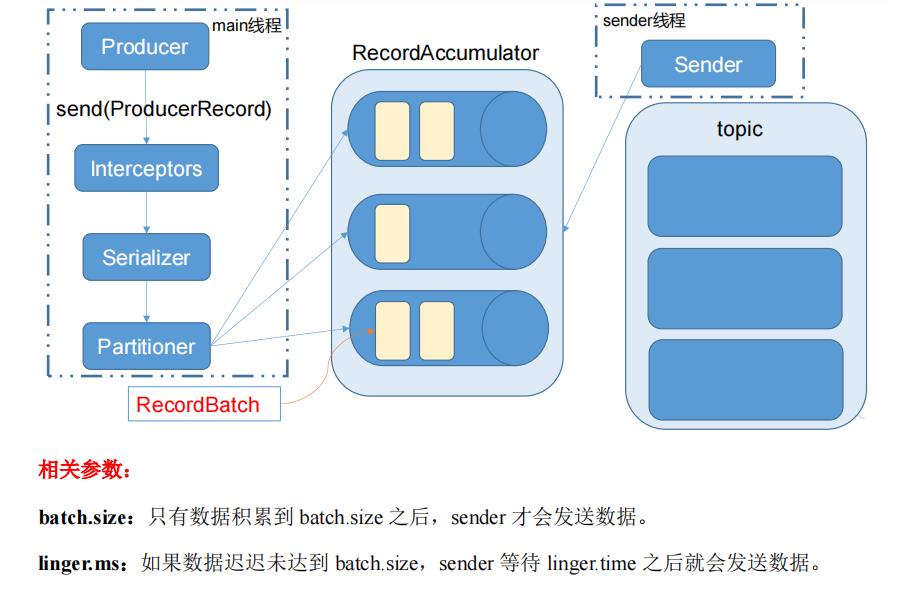
4.1.2 异步发送 API
4.1.3 同步发送 API
4.2 Consumer API
4.2.1 自动提交 offset
4.2.2 手动提交 offset
4.2.3 自定义存储 offset
4.3 自定义 Interceptor
4.3.1 拦截器原理
4.3.2 拦截器案例
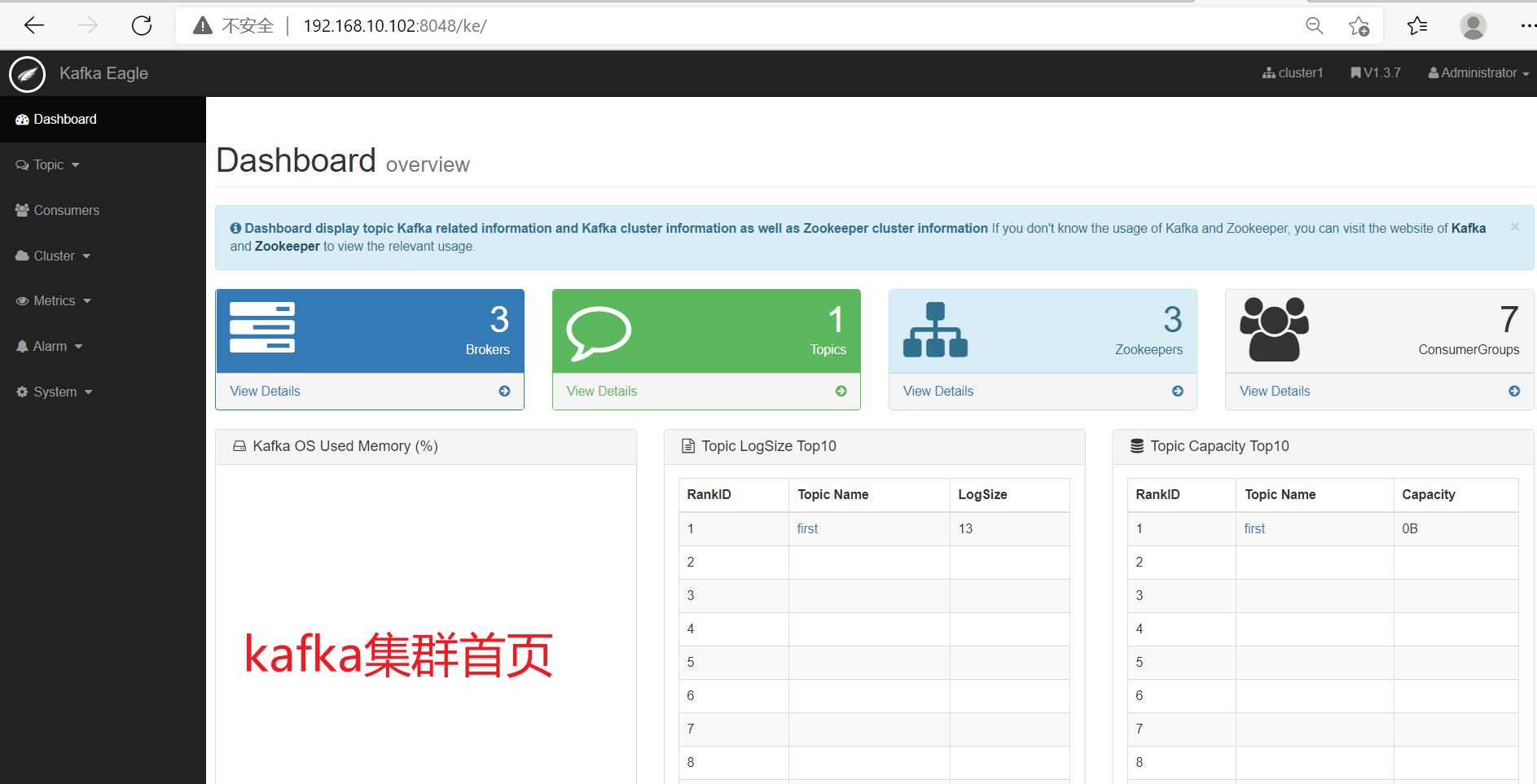
第 5 章 Kafka 监控
解决两个问题:
- 通过命令行做主题的增删改查比较麻烦,该监控工具很容易帮我们解决,呈现在界面上
- kakfa集群生产速度和消费速度能到多少,集群的高峰、低峰
1.修改 kafka 启动命令
修改 kafka-server-start.sh 命令中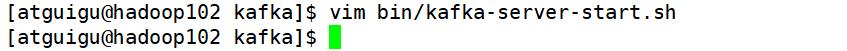

注意:修改之后在启动 Kafka 之前要分发之其他节点
2.上传压缩包 kafka-eagle-bin-1.3.7.tar.gz 到集群/opt/software 目录
3.解压到本地(software目录下)
4.进入刚才解压的目录
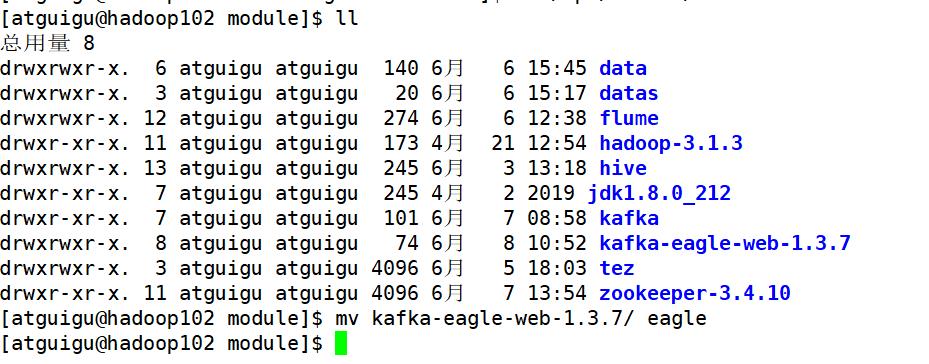
5.将 kafka-eagle-web-1.3.7-bin.tar.gz 解压至/opt/module
6.修改名称

7.配置环境变量



配好后记得ource /etc/profile
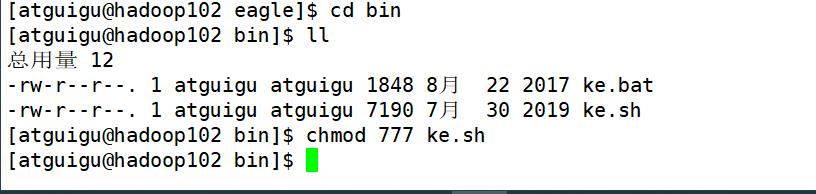
8.给启动文件执行权限
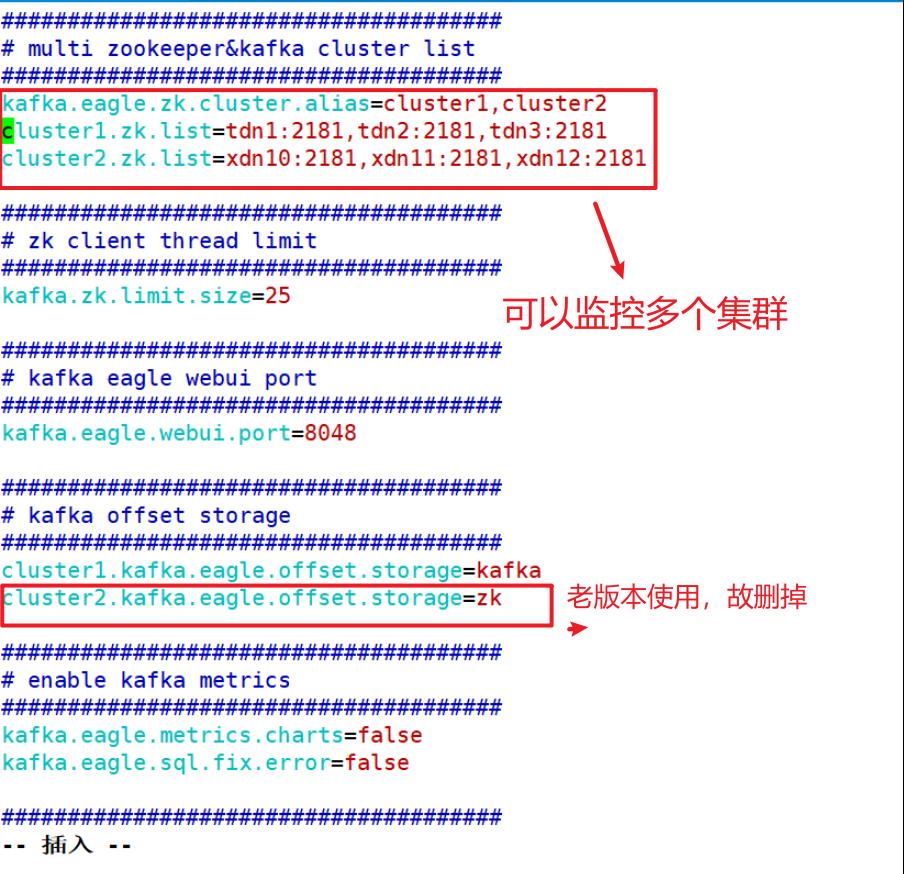
9.修改配置文件

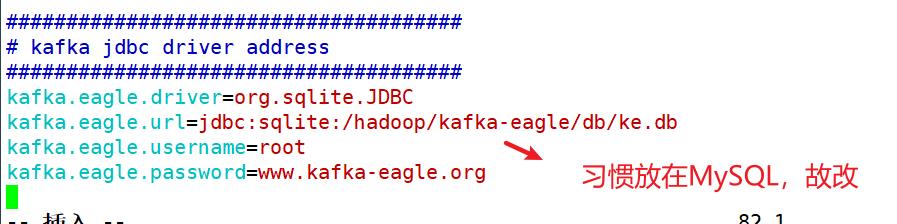
改为:
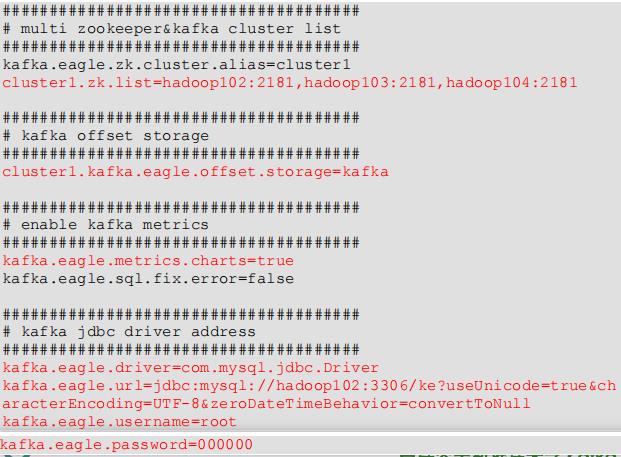
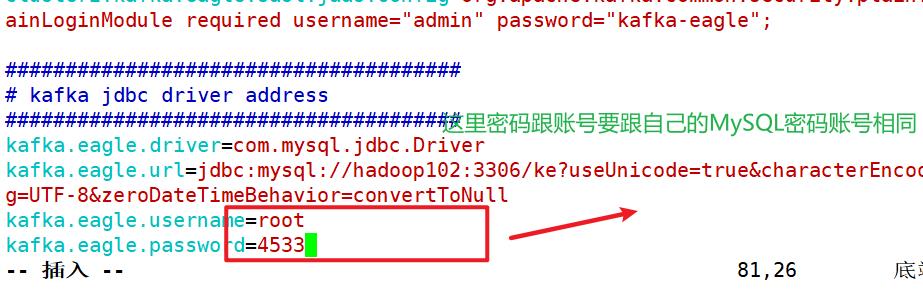
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://hadoop102:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=4533
10.启动
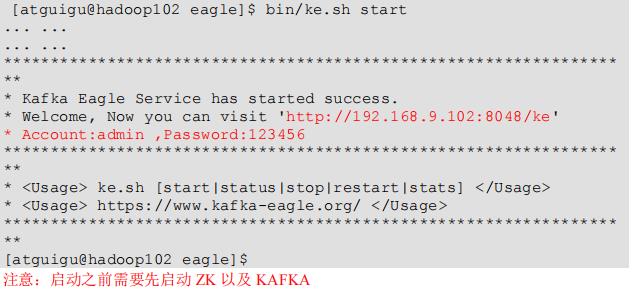
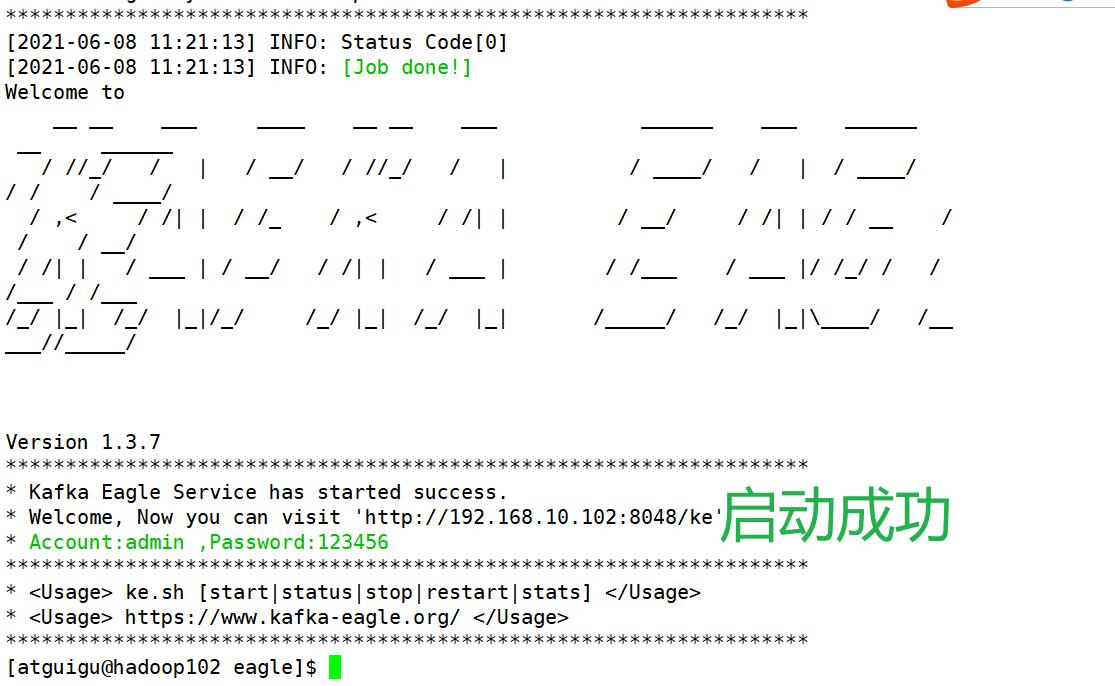
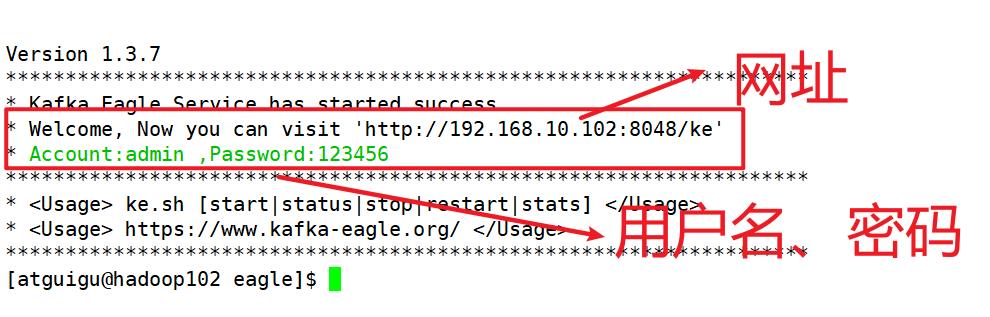
40-监控eage的使用:略,后续再整理
第 6 章 Flume 对接 Kafka(略,后续整理)
为什么对接flume:kafka采集flume的日志文件,给多个人使用
1)配置 flume(flume-kafka.conf)
2) 启动 kafkaIDEA 消费者
3) 进入 flume 根目录下,启动 flume
4) 向 /opt/module/data/flume.log 里追加数据,查看 kafka 消费者消费情况
以上是关于Kafka的主要内容,如果未能解决你的问题,请参考以下文章
Flink实战系列Flink 1.14.0 消费 kafka 数据自定义反序列化器
kafkaThe group member needs to have a valid member id before actually entering a consumer group(代码片段
SpringCloud系列十一:SpringCloudStream(SpringCloudStream 简介创建消息生产者创建消息消费者自定义消息通道分组与持久化设置 RoutingKey)(代码片段
Camel-Kafka java.io.EOFException - NetworkReceive.readFromReadableChannel