精通springcloud:消息驱动的微服务,发布/订阅模型
Posted jinggege795
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了精通springcloud:消息驱动的微服务,发布/订阅模型相关的知识,希望对你有一定的参考价值。
发布/订阅模型
事实上,创建Spring Cloud Stream项目的主要动机是支持持久的发布/订阅模型。在前面的小节中,我们讨论了微服务之间的点对点通信,这只是一个附加功能。但是,无论我们是否决定使用点对点通信或发布/订阅模型,编程模型仍然是相同的。
在发布/订阅通信中,数据通过共享主题广播。它降低了生产者(Producer) 和使用者(Consumer)的复杂性,并允许将新应用程序轻松添加到现有拓扑中,而无须对流程进行任何更改。这可以在最后提供的系统示例中清楚地看到,在该系统中,我们决定添加第二个应用程序,它将使用源微服务生成的事件。与初始架构相比,开发人员必须定义专用于每个目标应用程序的自定义消息通道。通过队列直接通信,消息只能由一个应用程序实例使用,因此,解决方案是必要的。发布/订阅模型的使用简化了该架构。
运行示例系统
要开发采用发布/订阅模型的示例应用程序,比开发采用点对点通信的示例应用程序更简单。开发人员不必覆盖任何默认消息通道以启用与多个接收器的交互。与演示向单个目标应用程序(account-service 服务)传递消息的初始示例相比,这里只需要稍微修改一下配置设置。 由于Spring Cloud Stream 默认绑定到主题,因而不必为输.入消息通道覆盖exchangeType。正如以下配置片段所示,我们仍然在将响应发送到order-service 服务时使用点对点通信。如果认真思考一下就会发现,这自有其道理。order-service 微服务发送的消息必须由account-service服务和product-service 服务接收,而来自它们的响应仅针对order-service服务。
spring:
application:
name: product-service
rabbi tmq:
host: 192.168.99.100
port: 5672
cloud:
stream:
bindings:
output:
destination: orders-in
input:
destination: orders -out
rabbit:
bindings:
output
producer :
exchangeType: direct
routingKeyExpression: ‘ “#” ’
product-service服务的主要处理方法的逻辑非常简单。它只需要从收到的订单中找到所有的productld,更改每个产品的库存数量,然后将响应发送到order-service服务。
@Autowired
ProductRepository productRepository;
@Autowired
orderSender orde rSender ;
public void process(final Order order) throws JsonProcessingException {
LOGGER. info ("Order processed: { }",mapper . writeValueAsString (order)) ;
for (Long productId : order . getProductIds()) {
Product product = productRepository. findById (productId);
if (product.getCount() == 0) (
order。setStatus (OrderStatus . REJECTED) ;
break;
product. setCount (product .getCount()一1) ;
productRepository.update (product) ;
LOGGER. info ("Product updated: { }",
mapper。wri tevalueAsString (product) ) ;
if (order.getstatus() != OrderStatus . REJECTED) {
order .setStatus (orderStatus. ACCEPTED) :
}
LOGGER. info("Order response sent: {}”,
mapper.writeValueAsString (Collections .singletonMap ("status",
order .getStatus( ) ) ));
orderSender。send (order) ;
}
要访问当前示例,只需切换到publish_ subscribe 分支,这可从
htps:/itub.con/piomin/sample-spring-cloud- mssasg/reepulish. subscribe 获取。然后,开发人员应该构建父项目并运行与上一个示例相同的所有服务。如果想要让测试一切正常,直到只有一个正在运行的account-service服务和product-service服务实例,那么现在就可以来讨论这个问题。
扩展和分组
在谈论基于微服务的架构时,可伸缩性(Scalability) 始终是其主要优势之一。 通过创建给定应用程序的多个实例来扩展系统的能力非常重要。执行此操作时,应用程序的不同实例将放置在竞争的使用者关系中,其中只有一个实例需要处理给定的消息。对于点对点通信来说,这不是问题,但在发布-订阅模型中,消息会被所有接收者使用,这可能是一个挑战。
1.运行多个实例
扩展微服务实例数量的可用性是Spring Cloud Stream 的主要概念之一。然而,这个想法背后没有神奇的地方。使用Spring Cloud Stream可以非常轻松地运行应用程序的多个实例。其中一个原因是来自消息代理的原生支持,它旨在处理许多使用者和大量流量。
在这种情形下,所有消息传递微服务也将公开RESTful HTTP API,因此,首先必须为每个实例定制服务器端口。我们之前已经进行了此类操作。还可以考虑设置两个SpringCloud Stream 属性spring
cloud.stream.instanceCount和spring. cloud.stream.instanceIndex.多亏了它们,微服务的每个实例都能够接收有关同-.应用程序的其他几个示例的启动信息以及它自己的实例索引。仅当要启用分区功能时,才需要正确配置这些属性。下文很快将谈论这个机制。现在,让我们来看一看扩展应用程序的配置设置。account-service 服务和product-service服务都定义了两个配置文件,用于运行应用程序的多个实例。我们已经自定义了服务器的HTTP端口、实例的数量和索引。
spring:
profiles: instancel
cloud:
stream:
instanceCount: 2
instanceIndex: 0
server:
port: ${PORT:8091}
spring:
profiles: instance2
cloud:
stream:
instanceCount:
instanceIndex: 1
server:
port: ${PORT:90911 }
构建父项目后,开发人员可以运行该应用程序的两个实例。它们中的每一个都使用分配给在启动期间传递的正确配置文件的属性进行初始化,如java -jar
-springprofiles.active-instancel target/account-service-1.0-SNAPSHOT.jar. 如果向order-service 服务端点POST 1发送测试请求,则新订单将转发到RabbitMQ主题交换信息,以便由连接到该交换的account-service服务和product-service 服务接收。现在的问题是每个服务的所有实例都收到消息,这并不是我们想要实现的。要解决这个问题,分组机制可以带来帮助。
2.使用者分组
我们的目的很明确。现在有许多微服务使用来自同一主题的消息。应用程序的不同实例被置于竞争的使用者关系中,但只有其中一个应该处理给定的消息。Spring Cloud Stream引入了模拟此行为的使用者分组(Consumer Group) 的概念。要激活此类行为,我们应该使用组名设置为
spring.cloud.stream.binding.<channelName>.group的属性。设置之后,订阅给定目标的所有分组都会接收到已发布数据的副本,但每个组中只有一个成员接收并处理来自该目标的消息。在我们的示例中,有两个分组。第一个是具有名称账户的所有account-service服务实例的分组;第二个则是具有名称产品的product- service服务实例的分组。
以下是account-service服务的当前绑定配置。orders-in 目的地是为与order-service服务直接通信而创建的队列,因而只有orders-out按服务名称分组。为product-service服务也准备了类似的配置。
spring:
cloud:
stream:
bindings:
output :
destination: orders-in
input:
destination: orders-out
group: account
第一个区别在为RabbitMQ交换信息自动创建的队列名称中可见。现在,它不是随机生成的名称,如orders-in.anonymous. qNxjzDq5Qra-yqHLUv50PQ,而是由目标和分组名称组成的确定字符串。如图11.6所示的屏幕截图显示了RabbitMQ上当前存在的所有队列。

开发人员可以自己执行重新测试,以验证该消息是否仅由同一组中的一个应用程序接收。但是,开发人员无法确定哪个实例将处理传入的消息。为了确定这一点,可以考虑使用分区机制。
3.分区机制
Spring Cloud Stream支持在多个应用程序实例之间对数据进行分区( Partitioning)。在典型的用例中,目标可被划分为不同的分区。每个生产者在发送由多个使用者实例接收的消息时,将确保由配置的字段标识数据以强制由同一使用者实例处理。要为应用程序启用分区功能,必须在生产者配置设置中定义partitionKeyExpression或
partitionKeyExtractorClass属性以及partitionCount.以下是可能为应用程序提供的示例配置。
spring.cloud. stream. bindings . output .producer.partitionKeyExpression =
payload. customerId
spring. cloud. stream. bindings。output。producer .partitionCount = 2
分区机制还需要在使用者端设置spring cloud. stream.instanceCount和
spring.cloud.stream.instanceIndex属性。还必须将spring. cloud.stream.bindings. input.consumer. partitioned属性设置为true才能显式启用它。实例索引负责标识特定实例从中接收数据的唯一分区。一般来说, 生产者端的partitionCount 和使用者端的instanceCount 应该相等。
现在来了解一下由Spring Cloud Stream 提供的分区机制。首先,它将根据partitionKeyExpression计算分区键,该分区键是根据出站消息或
PartitionKeyExtractorStrategy接口的实现来计算的,该接口定义了用于提取消息的键的算法。计算完消息的键之后,目标分区将被确定为0和pritinCount-1之间的值。默认计算公式为key.hashCode0%paritinCount.它可以使用partitionSelectorExpression属性进行自定义,也可以创建org, springframework.cloud.stream. binder.PartitionSelectorStrategy接口的实现。计算出的键将与使用者端的instanceIndex匹配。在解释了围绕分区机制的主要概念之后,现在可以来看一看其示例。以下是product-service服务输入通道的当前配置(与为account-service服务设置的账户分组名称相同)。
spring:
cloud :
streamt
bindings:
input:
consumer :
partitioned: true
destination: orders -out
group: product
现在每个微服务都有两个正在运行的实例,它们使用来自主题交换信息的数据。在order-service服务中还为生产者设置了两个分区。消息键是根据Order对象中的customerld字段计算的。索引为0的分区专用于customerld 字段中具有偶数的订单,而索引为1的分区则用于customerld字段中的奇数订单。
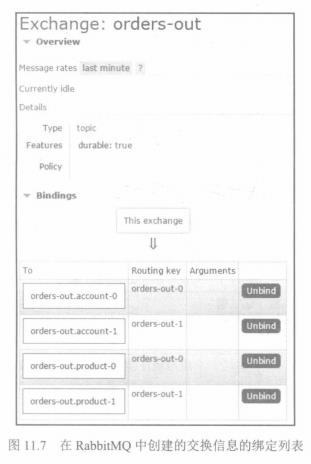
实际上,RabbitMQ 没有对分区的原生支持。有趣的是,Spring Cloud Stream 使用RabbitMQ实现分区处理的方式。在如图11.7所示的屏幕截图中,显示了在RabbitMQ中创建的交换信息的绑定列表。在该图中可见已经为exchange-orders-out-0 和orders-out-1定义了两个路由键。
如果在JSON 消息中发送了一个customerld 等于1的订单,如{"customerld":1,"produtlds":4l,"status"."NEW"},那么它将始终由instanceIndex= 1的实例处理。可以在应用程序日志中或使用RabbitMQ Web控制台来查看它。如图11.8 所示就是一个包含每个队列的消息速率的屏幕截图,可以看到customerld=1的消息已被多次发送。

配置选项
可以使用Spring Boot支持的任何机制(如应用程序参数、环境变量和YAML或属性文件)覆盖SpringCloudStream配置设置。它定义了许多可应用于所有绑定器的通用配置选项。但是,还有一些与应用程序使用的特定消息代理相关的其他属性。
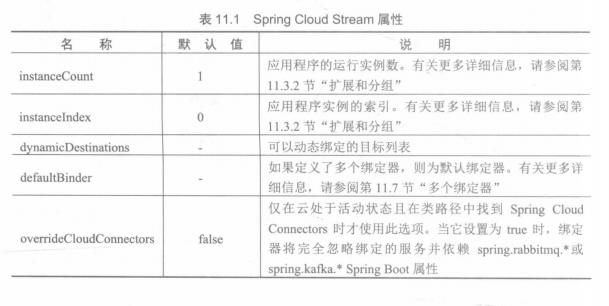
Spring Cloud Stream属性
当前的属性组适用于整个Spring Cloud Stream应用程序。表11.1中的所有属性都以spring.cloud.stream为前缀。
绑定属性
下一组属性与消息通道相关。在Spring Cloud术语中,这些都是绑定属性。它们可以仅分配给使用者、生产者或同时分配给两者。表11.2是绑定属性列表及其默认值和说明。

1.使用者
以下属性列表仅适用于输入绑定,并且必须以spring cloud.stream.bindings.<channelName>.consumer为前缀。其中最重要的一些属性如表11.3所示。

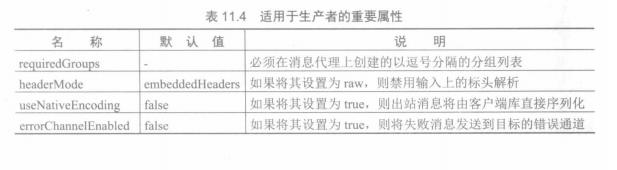
2.生产者
以下绑定属性仅可用于输出绑定,并且必须以spring.cloud.stream. bindings.<chaneIName>. producer为前缀。其中最重要的一些如表11.4 所示。
以上是关于精通springcloud:消息驱动的微服务,发布/订阅模型的主要内容,如果未能解决你的问题,请参考以下文章
第十章 消息驱动的微服务: Spring Cloud Stream
Spring Cloud构建微服务架构 消息驱动的微服务(消费分区)Dalston版