入职字节跳动那一天,我哭了(蘑菇街被裁,奋战2个月拿下offer)
Posted java路人甲乙丙丁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了入职字节跳动那一天,我哭了(蘑菇街被裁,奋战2个月拿下offer)相关的知识,希望对你有一定的参考价值。
前言
先说一下自己的个人情况,19届应届生,通过校招进入到了蘑菇街,然后一待就待了差不多2年多的时间,可惜的是今年4月份受疫情影响遇到了大裁员,而我也是其中一员。好在早有预感,提前做了准备,之前一直想去字节跳动,年前就已经在做准备了,这场持久战拉得很长,也最终以2个月的时间取得胜利。在踏入字节跳动,办理入职手续的那一天,作为一个男子汉,确实是落泪了。特分享一波我的真实经历,共勉。
小tip:
其实一个公司要进行裁员通常都会出现一些前期征兆:业务发展遇到较大瓶颈,并且难以突破、频繁调整战略目标、高管开始陆续离职、开始严抓考勤、开始部分同事劝退,如果你现在的公司也开始出现这些症状,别想了,是时候开始做准备了。
以下内容涉及4大环节:
- 环节一:制定计划,做足准备
- 环节二:实施计划,准备实战
- 环节三:制定简历,投递简历
- 环节四:字节跳动面试经历,真实记录还原
四个环节中,内容中包含了很多文档资料,由于文章篇幅有限,全整理在文档内,包括Java学习资料、学习笔记、算法宝典、面试题合集、思维导图(Xmind)等,需要这些资料的朋友文末获取下载方式~

环节一:制定计划,做足准备
1.梳理知识体系
现在大部分的程序员的现状都特别奇怪,自己所掌握的知识是比较零散的,或者对某个知识点只知其表不知其里,其实这都是对自己掌握的技术内容没有进行一个系统的梳理,所以制定计划的第一步就是要梳理好自己的知识体系。关于梳理知识体系,要做到以下2点:
- 你是否了解这个知识点的why、where、how
- 你能否能将这些概念和知识能简单通俗易懂的讲给另一个完全不理解的人听懂
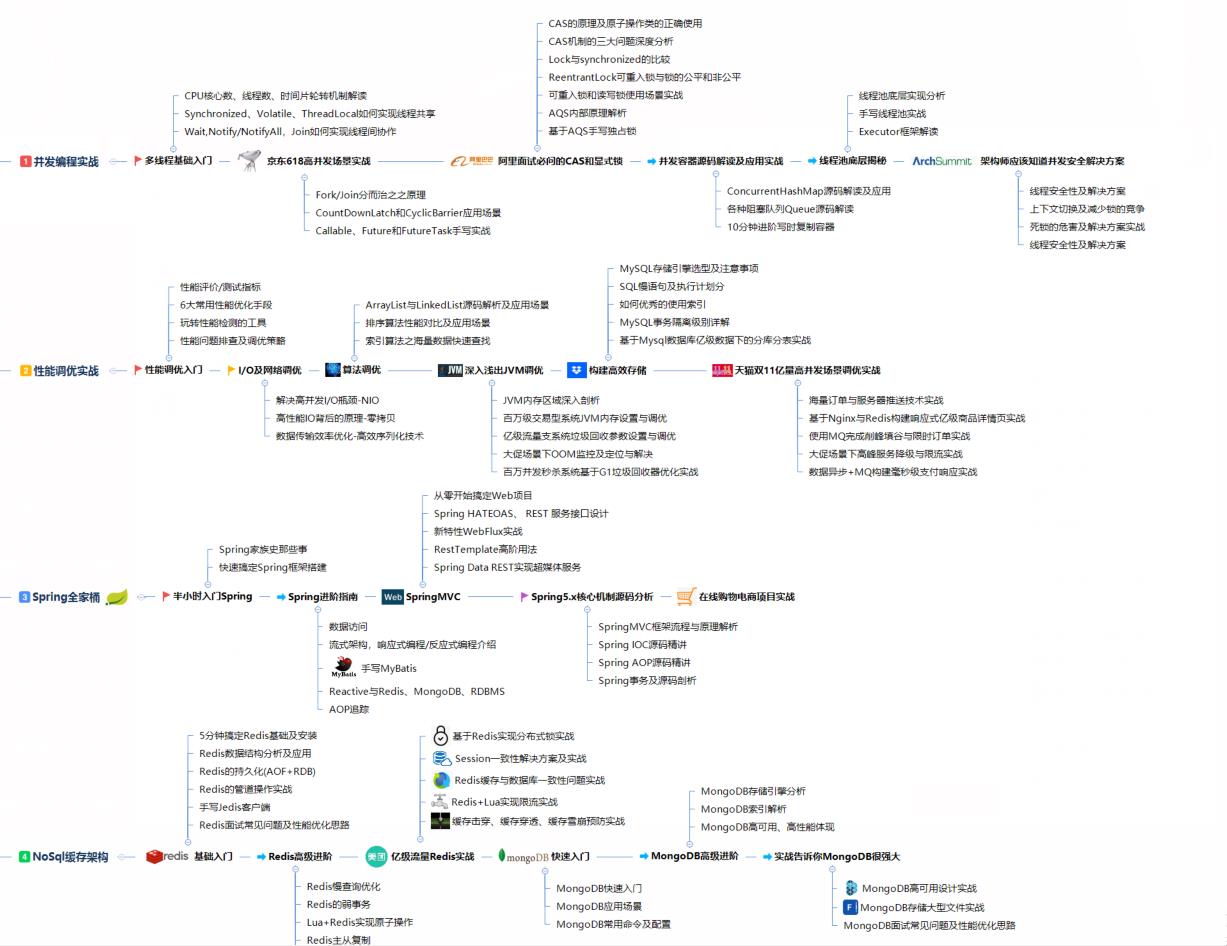
系统知识图
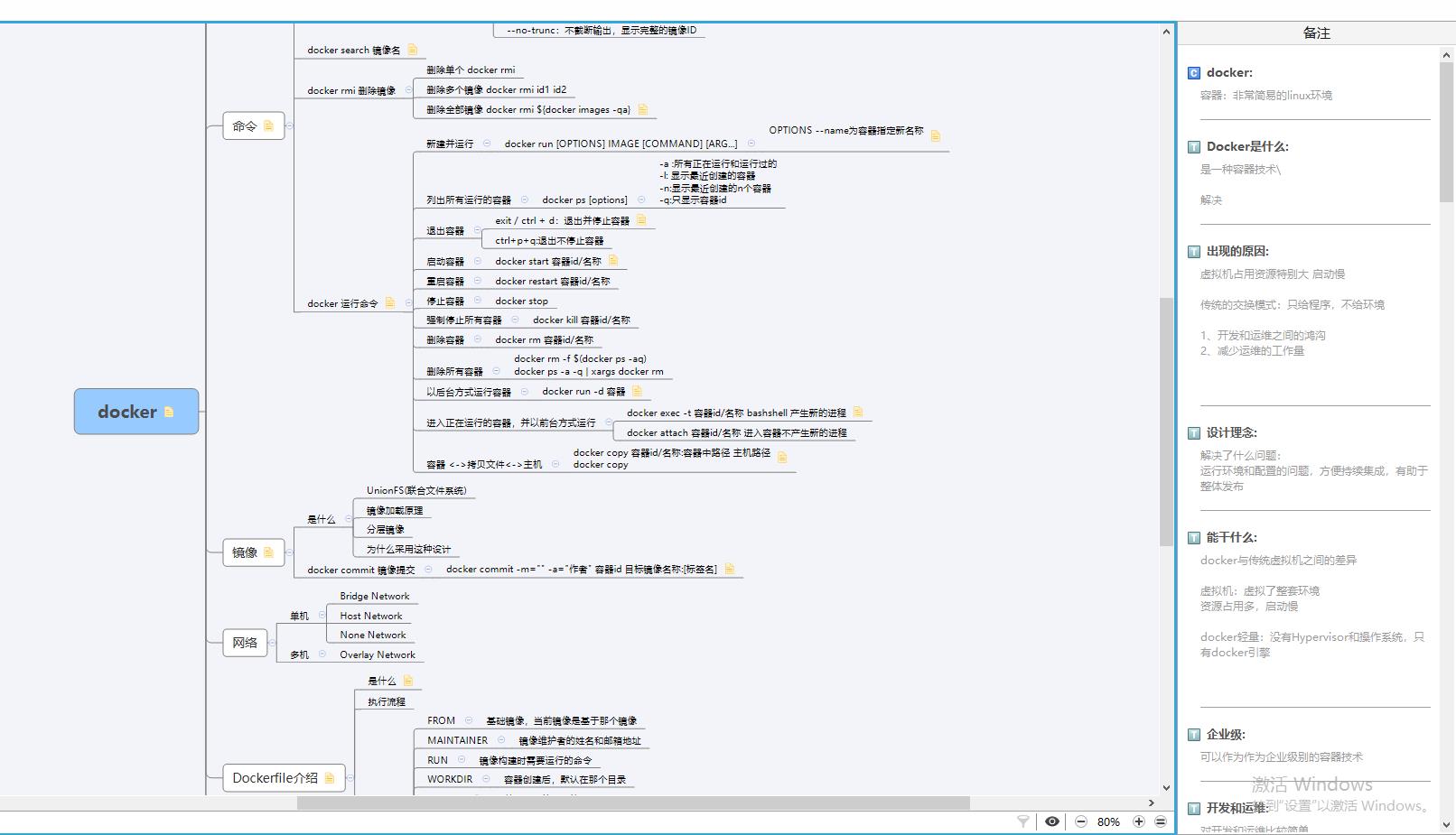
Docker思维图(xmid)
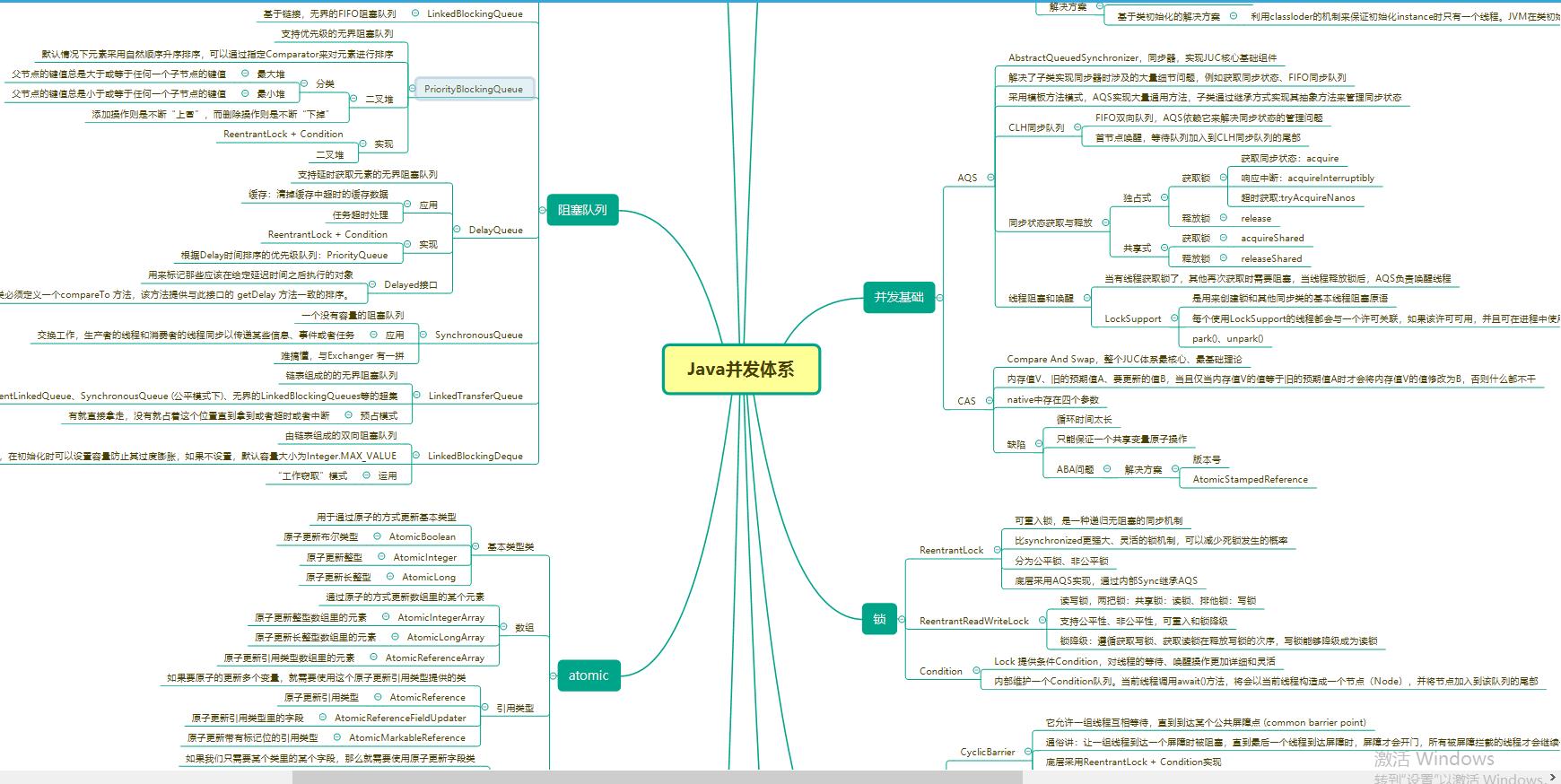
Java并发体系图(xmind)
2.准备算法
- 该如何学习算法?
- 程序员必须掌握的算法有哪些?
- Leetcode刷题,到底稳吗?
关于算法部分,其实要准备的细节内容非常多,所以我也花了不少心思整理了一份关于算法方面的宝典,这份资料我对算法的认识以及我的学习方法,除了Leetcode以外,字节跳动喜欢问的核心算法题也进行一道一道的深度解析。


3.收集整理面试题
除了算法部分以外,要想在实际面试中做到心中有数,大厂的常问的一些面试题或知识点也很有必要看一看。我特意搜集整理了近3年来一线互联网公司的面试题(技术部分),会发现这些面试题实际问的大同小异,但考察你的内容和技术都是有不同的目的性的,对这一部分的分析,我也有写在答案里(详细见文档)。
环节二:实施计划,准备实战
前期准备的这些需要一步一步行动起来了,但除了以上肯定是远远不够的,面试官除了技术相关的问题,必问的就是项目相关的内容,那项目相关内容需要怎么来准备呢?除了自己的实战经验的积累以外,其实我们还是可以阅读一些技术大牛写出来的实战经验及笔记。如:Redis笔记、SpringBoot技术笔记等。
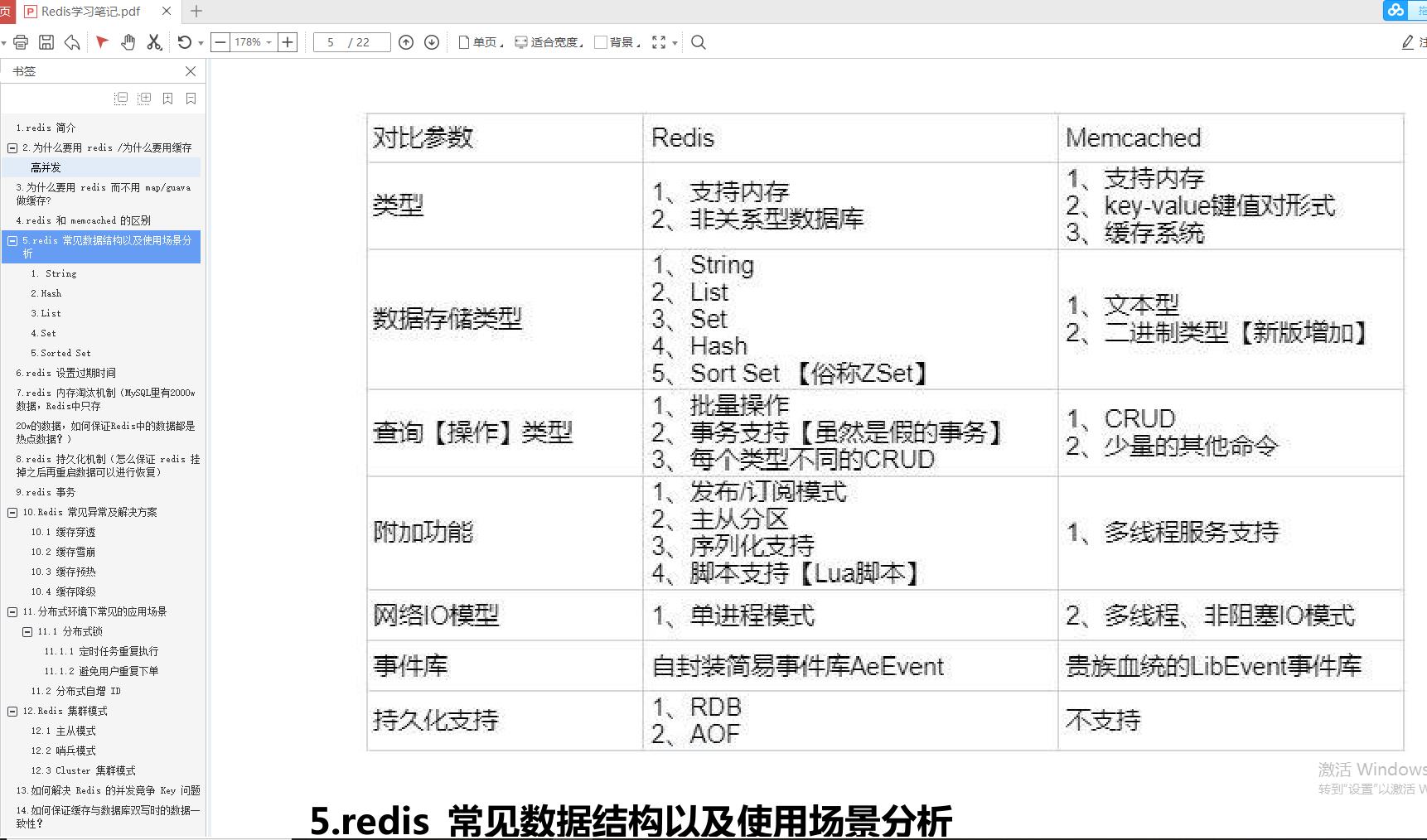
Redis笔记

SpringBoot技术笔记
环节三:制定简历,投递简历
简历对于程序员来说是非常重要的一个环节,一份优秀的简历往往能够帮助我们敲开一线互联网大厂的大门,简历部分我就不做过多的赘述。可以参考《程序员找工作指南》,另外我可以提供18种优秀的简历模板。
下载好之后,根据模板来制定自己的简历,接下来就可以顺利投递啦!投递简历一定要参考好匹配值,建议最好找熟人内推。

简历范本

环节四:字节跳动面试经历,真实记录还原
字节跳动一面:
第一面我觉得应该是基础面,重点考察的是自己技术的广度 和一些技术的掌握情况,一面小哥哥也没有深究于某个特定的点,面试时间大约1个小时。
- 自我介绍
- 怎么打算投递后台岗位的,没有考虑契合自己研究方向的工作?
- 有了解过OAuth2.0么,说说你对OAuth2.0的理解
- 蘑菇博客开发过程中,有了解或学习其它的开源框架吗?
- 蘑菇博客文章发布的流程是怎么样的,是多人博客系统吗?
- 对其它的一些博客框架有了解吗?比如hexo
- hexo和蘑菇博客相比有什么区别呢?蘑菇博客多了哪些功能和优势?
- 看你蘑菇博客用到了RabbitMQ,那谈谈为什么引入RabbitMQ?
- RabbitMQ和其它消息队列,比如ActiveMQ,RocketMQ,Kafka有什么区别?
- Redis在你博客项目中的使用,为什么引入Redis?
- Redis中存储的是热门文章,是通过什么来得到的?这样做会有什么问题么?
- 有听过长尾效应么?你通过推荐字段设置的推荐等级,这样会让这些文章一直保持在较高的点击量,而且热度和点击量也不会随着时间而降低,有什么解决方案么?
- 我看到你有用到JustAuth这个登录授权?说说它会存在账号泄漏的问题么?
- 下面谈谈Redis,它会存在线程切换的问题么?
- 谈谈Redis单线程模型和IO多路复用
- Redis的大Key的问题,如果有个Value的大小是2M,会有什么问题么?最大支持的Value大小是多少?
- 谈谈Redis集群 Redis Cluster,以及主从复制原理?
- 说说Redis中的哨兵,即Redis Sentinel
- 下面来聊聊Linux,你知道Linux怎么查看当前的负载情况么?
- 你还知道其它的一些Linux命令么?
- cat、tail、vi、vim命令的区别,分别说一说?
- 如果Linux下需要打开或者查看大文件,你会怎么做?
- 下面聊聊Http Code,你知道 3XX 状态码 对应的是什么?
- 谈谈你知道的其它一些状态码,4XX 和 5XX?
- 算法题:
(1)# 给定一些数组,例如下面的格式,他们都表示一个区间,然后你需要将区间进行合并
[1,2],[2,4],[3,7],[8,11]
# 如上所示, [1,2] 和 [2,4] = [1,4]
# 然后 [1,4] 和 [3,7] = [1,7]
# 最后 [1,7] 和 [8,11] 无法合并,所以最后结果应该返回 [1,7],[8,11]
(2)# 给定一个数组,例如 [1,1,2,2,2,3,3,3,3]这样的,里面的数组不一定连续并且有序,假设我输入 2,这个2表示出现次数最高的两个
# 那么你需要给我返回 2,3
字节跳动二面:
- 自我介绍
- 博客已经开源了么,用的什么开源协议,博客的用户多么?
- 看你博客中用到了Solr和ElasticSearch,谈谈它们的原理,以及倒排索引?
- 对于Solr或者ES里面用到的一些中文分词器有了解过么?
- 谈谈那些技术栈,你比较熟悉的是那些,mysql 和redis?
- 聊聊MySQL的底层索引结构,InnoDB里面的B+Tree?
- B Tree 和 B+ Tree的区别
- 聊聊MySQL索引的发展过程?是一来就是B+Tree的么?从 没有索引、hash、二叉排序树、AVL树、B树、B+树 聊。
- 谈谈MySQL里面的事务,说说什么是事务?
- MySQL里面有哪些事务级别,并且不同的事务级别会出现什么问题?
- 谈谈可重复读和幻读的区别?
- MySQL中如果使用like进行模糊匹配的时候,是否会使用索引?一定不会用么?
- 谈谈Redis吧,在你项目中的具体使用?
- 谈谈Redis如何实现分布式锁?
- 蘑菇博客是否存在缓存不一致的情况,你是如何解决的?
- 谈谈Redis中缓存穿透的问题,以及解决的方法?
- 还有其它解决缓存穿透的方法么?布隆过滤器有了解过么?
- Redis中大面积的缓存失效,然后请求全部打到数据库,有什么解决方法?
- 如果出现一些热点数据,比如明星之间的新闻,造成大量的吃瓜用户涌入后台,但是服务器还没有缓存对应的数据,这样可能造成数据库宕机,如何避免这样的情况?
- 聊聊 JVM的组成结构?
- 谈谈垃圾收集原理?以及垃圾收集算法
- 复制算法 和 标记整理算法?
- 为什么不在新生代使用标记整理算法?或者在老年代使用复制算法?
- 有了解过Volatile么?谈谈你对Volatile的理解
- Volatile如何保证可见性的?以及如何实现可见性的机制。
- 如果大量的使用Volatile存在什么问题?
- 谈谈操作系统的线程,以及它的状态
- 线程和进程的区别?
- 为什么提出多线程应用,而不是多进程应用呢?
- Linux你平时都有用到什么命令呢?
- 如果我需要查看端口号或者进程号,你会使用什么命令?
- 谈谈你做的另外一个项目吧?稍微介绍一下
- 来吧,写个题目试试
# 链表的两两翻转 # 给定链表: 1->2->3->4->5->6->7 # 返回结果: 2->1->4->3->6->5->7
字节跳动第三面:
- 自我介绍
- 好奇一下,用码/云的人应该不多吧,为什么没有用Github?
- 你英文水平怎么样?
- 聊聊开源项目吧?我看这项目已经有800多赞了,你在这开源项目主要做了什么工作?
- 我们找些点来聊聊吧?先从ES和Solr开始,你们这两个都有在用么?
- SQL的方式实现搜索,你是怎么做的呢?
- 使用like匹配的时候,会不会查询非常慢呢?
- ES和Solr的底层都用了lunce,谈谈你对lunce的理解?
- lunce里面也有用到分词器,比如一些新的词 “新冠肺炎” ,它能不能做到很好的划分呢?
- 除了人为的维护词库,来解决最新词语的分割,你还有知道其它什么更好的方法么?
- 你有了解过其它什么开源的分词库么?
- 谈谈字典树?
- Solr 和 ES底层都用了Lunce,那他们两者有什么区别呢?
- Solr所谓的集群环境 和 ES所谓的分布式环境,它们之间有什么区别呢?
- 上面你有提到微服务,你有了解过微服务是个什么样的理念么?
- 你现在的微服务,也是打包成多个jar包,部署在一个服务器上,如果服务器出现问题了,也会造成服务不可用,有没有好的解决方法呢?
- 聊聊服务的注册与发现?
- 服务的注册和发现,其实依赖于一个注册中心的概念,会不会出现注册中心挂掉,而导致整个服务不可用,有没有什么好的解决方法呢?
- 有了解过Zookeeper整个的选举过程么?
- 谈谈Zookeeper的分布式一致性协议?
- 聊聊索引,我给你写个表,看看下面的查询语句,走了那些索引?
create table 'tb' (
id int,
name varchar(64),
status int,
createtime timestamp,
PRIMARY KEY (`id`)
)
-- 创建了三个普通索引
create index index_name on table('name')
create index index_status on table('status')
create index index_createtime on table('createtime')
-- 给定SQL语句,判断下面查询会用到几个索引
select * from tb where status = 1 and name = "zhangsan"
- 上述SQL用到了几个索引?分别是那几个?
- 有了解过InnoDB底层的索引结构么?
- 通过两个索引查询出来的结果,会进行什么样的操作?交集,并集?
- 如果你在MySQL中遇到一些慢查询,有什么解决方法么?
- 谈谈explain?执行的explain后,出现的那些字段,能够帮助我们呢?
- 我看你的博客里面,关于Redis还有好几篇文章,我们可以聊一聊你对Redis的理解?
- 为什么Redis能够保持这么高的并发响应?
- 有了解过IO多路复用技术是个什么样的原理
- 通过一个线程,同时连接多个线程不会存在多个线程切换么?(感觉进坑了。。)
- 当你通过jedis进行连接redis的时候,已经和一个进程连接了 ,redis还能够和其它的进程进行通信么?
- Redis每秒能够处理处理十万请求,如果按照你上面说的,那说明它每次交互只在 1/十万 秒内完成?
- 有了解过Redis的源码么?
- MySQL用了B+Tree,Redis中的SortSet内部用了跳跃表,他们之间有什么差别?为什么MySQL不用跳跃表,或者是Redis不用B+Tree呢?
- 感觉自己编码功底怎么样?那我们先聊聊操作系统的知识再给你一道题吧。在操作系统中,有高速缓存,主存,虚拟内存,外存,知道它们之间有什么样的关系,以及它们的作用是啥?
- 对它们来说,肯定会存在一个问题,就是当我们的主存满了,或者虚存满了,那么需要存在一个换页操作,你知道有那些换页算法么?
- 我们来聊聊LRU?叫你手写一个LRU算法谈谈你的思路?
- 用链表的方式实现,时间复杂度是O(N),有没有什么方式能够让它是O(1)的时间复杂度呢?
- OK,思路还可以,那你手写一个LRU算法吧?(双向链表 + Hash?)
字节跳动面试题答案:
以上三轮面试的技术题的详细答案与解析均整理在文档内,由于解析文字过多,不在文章中分享,需要这份面试题答案可以私信我。

总结
这次能够顺利入职字节跳动,可以说是运气和实力参半,但我一直持有的一个观念就是:好运永远是留给有准备的人。
所以,作为一名技术人,对大厂有着执念,那就要落实下来,相信自己付出是会有所回报的。在这,我也祝大家在接下来的金九银十里,面试顺利,过关斩将,拿下offer。
以上文章里写到的所有文档资料,均免费分享,有需要的小伙伴一键三连(点赞+收藏+关注)后

以上是关于入职字节跳动那一天,我哭了(蘑菇街被裁,奋战2个月拿下offer)的主要内容,如果未能解决你的问题,请参考以下文章
入职腾讯那一天,我哭了(蘑菇街被裁,奋战7个月拿下offer)
入职腾讯的前一天,我哭了(传统行业被裁,奋战一年成功逆袭!)
15k入职腾讯测试岗那天,我哭了,这6个月做的一切都值了...