Redis缓存设计与优化
Posted 并发编程之美
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis缓存设计与优化相关的知识,希望对你有一定的参考价值。
介绍
缓存带来了加速读写,降低后端负载的好处外,同时也存在一定的成本,比如数据不一致,缓存层和数据层有时间窗口不一致,和更新策略有关;代码维护成本多了一层缓存逻辑;以及运维成本,例如Redis Cluster等。所以在实际的使用中,我们需要区分场景合理使用缓存逻辑。同时缓存对粒度控制分缓存全部数据和部分重要数据:
通用性:全量属性更好
占用空间:部分属性更好
代码维护上:表面上全量属性更好
一、缓存适用场景
缓存的适用场景示例:
对高消耗的SQL:join结果集/分组统计结果缓存
加速请求响应:利用Redis/Memcache优化IO响应时间
大量写合并为批量写:如计数器先Redis累加再批量写DB
二、缓存更新策略
缓存的更新策略:
控制最大内存情况下,LRU/LFU/FIFO算法剔除:例如maxmemory-policy
超时剔除:例如expire
主动更新:开发控制生命周期
三种缓存更新策略对比:
| 策略 |
一致性 |
维护成本 |
| LRU/LIRS算法剔除 |
最差 |
低 |
| 超时剔除 |
较差 |
低 |
| 主动更新 |
强 |
高 |
使用建议:
低一致性:最大内存和淘汰策略
高一致性:超时剔除和主动更新结合,最打内存和淘汰策略兜底
除了缓存服务器自带的缓存失效策略之外,我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
定时去清理过期的缓存
当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存
两者各有优劣,第一种的缺点是维护大量缓存的key是比较麻烦的,第二种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂。
二、缓存穿透优化
缓存穿透最常见的场景就是访问根本就不存在的数据。一般是黑客故意去请求缓存中不存在的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
原因:
业务代码自身问题,空变量
恶意攻击、爬虫等
解决:
1. 缓存空对象+过期时间
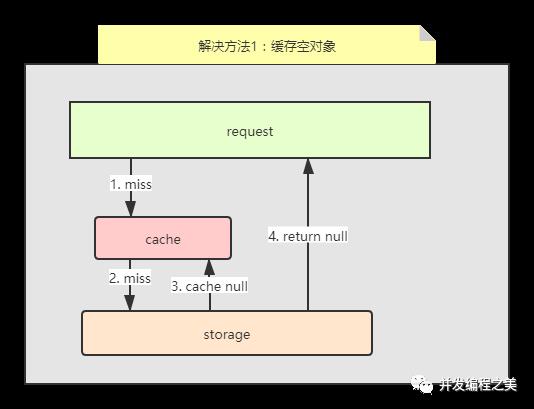
存在的问题:
需要更多的键
缓存层和存储层数据短期不一致
示例代码:
public String getPassThrough(String key) {String cacheValue = cache.get(key);if (StringUtils.isBlank(cacheValue)) {String storageValue = storage.get(key);cache.set(key, storageValue);//如果存储数据为空,需要设置一个过期时间(300秒)if (StringUtils.isBlack(storageValue)) {cache.expire(key, 60 * 5);}return storageValue;} else {return cacheValue;}}
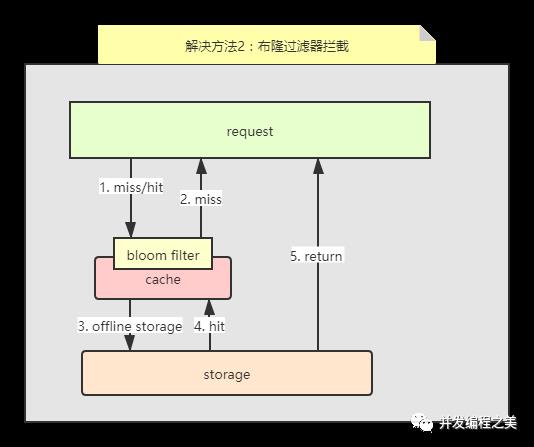
2. 布隆过滤器拦截
最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
三、缓存无底洞问题优化
有这么一个场景,已经存在了很多Redis或者Memcache服务节点,发现加机器性能没提示反而下降:http://highscalability.com/blog/2009/10/26/facebooks-memcached-multiget-hole-more-machines-more-capacit.html
问题关键点:
更多的机器!=更高的性能
批量接口需求(mget、mset等)
数据增长与水平扩展需求
所以原因就是批量操作的变化,当只有一个节点是,一个mget操作是有一次网络IO,当阶段扩大到3个时候,使用顺序IO方式的话,一次mget的操作会随着机器节点的个数增加而网络传输次数也越来越多,对客户端执行效率带来很大的下降。实际上IO由于扩容从原来的o(1)增加到了o(node)。
优化IO的几种方法:
命令本身优化:例如慢查询keys、hgetall bigkey
减少网络通信次数
降低接入成本:例如客户端长链接/连接池、NIO等
串行mget
串行io
并行io
hash_tag
串行mget、串行io、并行io以及hash_tag介绍详见【Redis Cluster高可用集群模式】
四种方案优缺点对比:
| 方案 |
优点 |
缺点 |
网络IO |
| 串行mget |
少量keys满足需求 | 大量keys请求延迟严重 |
o(keys) |
| 串行IO |
少量节点满足需求 |
大量nodes延迟严重 |
o(nodes) |
| 并行IO |
延迟取决于最慢的节点 |
超时定位问题复杂 |
o(max_slow(node)) |
| hash_tag |
性能最高 |
读写增加tag维护成本,tag分布容易出现数据倾斜 |
o(1) |
四、缓存雪崩问题优化
当流量洪峰到达时,缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉,就是缓存雪崩。
解决方法:
事前:尽量保证整个 redis 集群的高可用性,如采用Redis Cluster架构,发现机器宕机尽快补上。选择合适的内存淘汰策略
事中:本地cache缓存 + hystrix限流&降级,避免mysql崩掉
事后:利用 redis 持久化机制保存的数据尽快恢复缓存
对缓存进行实时监控,当请求访问的慢速度比超过阈值,及时报警,通过自动故障转移,服务降级,停止部分非核心接口的访问
提前压测预估系统处理能力,做好限流与服务降级
五、缓存预热优化
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题,用户直接查询事先被预热的缓存数据。解决思路:
直接写个缓存刷新页面,上线时手工操作下
数据量不大,可以在项目启动的时候自动进行加载
定时刷新缓存
六、热点key重建优化
热key重建指的是开发人员设置好的缓存过期时间过了,需要重新构建缓存。热key说明当前可能有大量的请求,同时访问同一个key,而且这个并发量特别大,缓存失效的瞬间可能会有大量的线程来重建缓存,造成后端数据库压力暴增。
问题描述:热点key+较长的重建时间。
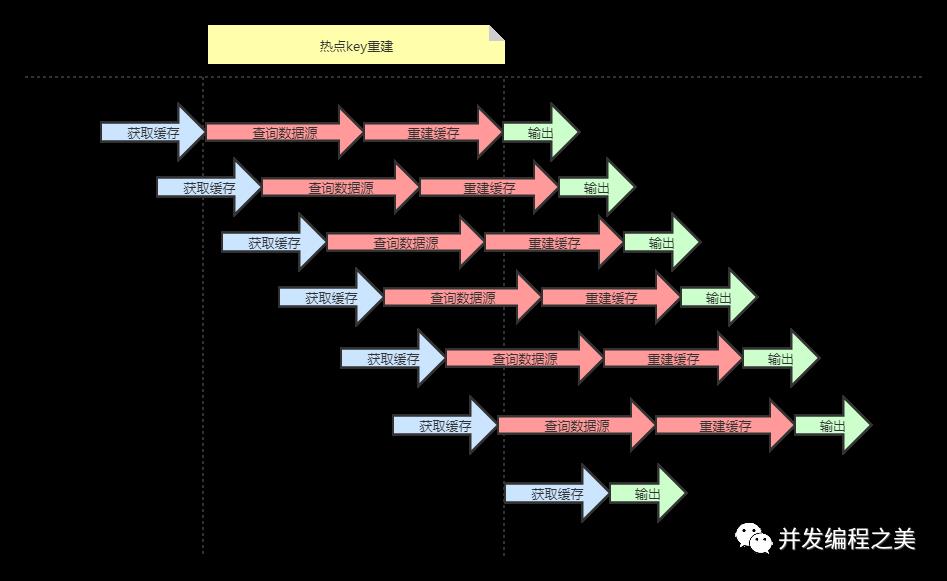
存在问题:大量的线程都会做缓存重建和查询数据源。
解决方法:
1. 互斥锁(mutex key)
通过设置互斥锁,统一时间只允许一个请求进行热key的重建。如基于redis的setnx命令实现
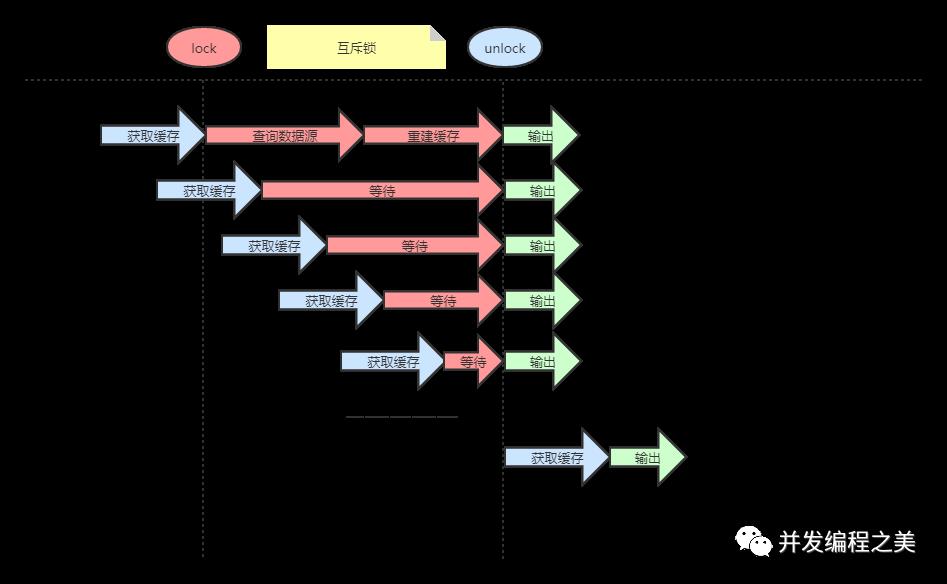
存在问题:不需要大量重建工作,但是存在大量线程等待的问题。
示例代码:
String get(String key) {String value = redis.get(key);if (value == null) {String mutexKey = "mutex:key:" + key;if (redis.set(mutexKey, "1", "ex 180", "nx")) {value = db.get(key);redis.set(key,value);redis.delete(mutexKey);} else {//其他线程休息50毫秒后重试Thread.sleep(50);get(key);}}return value;}
2. 永不过期
为每个value添加逻辑过期时间,发现超过逻辑过期时间后,会使用单独的线程去构建缓存,但是存在缓存不一致情况。示例代码:
String get(final String key) {V v = redis.get(key);String value = v.getValue();long logicTimeout = v.getLogicTimeout();if (logicTimeout >= System.currentTimeMills()) {String mutexKey = "mutex:key:" + key;if (redis.set(mutexKey, "1", "ex 180", "nx")) {//异步更新后台异步执行threadPool.execute(() -> {String dbValue = db.get(key);redis.set(key,dbValue, newLogicTimeout());redis.delete(mutexKey);});}}return value;}
3. 方案对比
| 方案 |
优点 | 缺点 |
| 互斥锁 |
保证一致性 |
代码复杂,存在死锁风险 |
| 永远不过期 |
基本杜绝热点key重建问题 |
不保证一致性,逻辑过期时间增加维护成本和内存成本 |
4. 缓存降级
与热点key相对立的策略就是缓存降级了,服务降级的目的,是为了防止Redis服务故障,导致数据库跟着一起发生雪崩问题。因此,对于不重要的缓存数据,可以采取服务降级策略,例如一个比较常见的做法就是,Redis出现问题,不去数据库查询,而是直接返回默认值给用户。
推荐阅读
1. Redis云平台CacheCloud:https://github.com/sohutv/cachecloud
看完本文有收获?请转发分享给更多人
关注「并发编程之美」,一起交流Java学习心得
以上是关于Redis缓存设计与优化的主要内容,如果未能解决你的问题,请参考以下文章