C++从学渣到学霸之了解C++
Posted 蚍蜉撼树谈何易
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++从学渣到学霸之了解C++相关的知识,希望对你有一定的参考价值。
C++入门
引言
引言:本篇博客主要介绍C++的发展史及C++的一些特性。及相对于C语言来说C++做了那些更好的优化。如果你刚结束完C语言学习的话,又相对C++了解的话,相信我,这篇博客可以让你收益良多。
什么是C++
C语言是结构化和模块化的语言,适合处理较小规模的程序。对于复杂的问题,规模较大的程序,需要高度的抽象和建模时,C语言则不合适。为了解决软件危机, 20世纪80年代, 计算机界提出了OOP(objectoriented programming:面向对象)思想,支持面向对象的程序设计语言应运而生。
1982年,Bjarne Stroustrup(本贾尼)博士在C语言的基础上引入并扩充了面向对象的概念,发明了一种新的程序语言。为了表达该语言与C语言的渊源关系,命名为C++。因此:C++是基于C语言而产生的,它既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行面向对象的程序设计。
C++发展史
从c++诞生到现在,它经历过3个发展阶段。第一阶段是从1980~1995,在这个阶段,c++开始在编程领域展露头角。进过一段时间的发展,c++已经在工业上的开发语言占很大的比例。
第二个阶段是1995~2000年,在这阶段,c++的近况大不如前。因为一些新型语言的开发与发展,也在硬件价格大规模下降的社会背景下,c++逐渐在编程语言的舞台上显现弱势,这个阶段也可以称为c++发展以来的一次大危机。
近些年来,c++的发展也开始复苏。2000~如今,这就是c++发展的第三阶段。这也是c++发展史上的另一个巅峰
C++的关键字
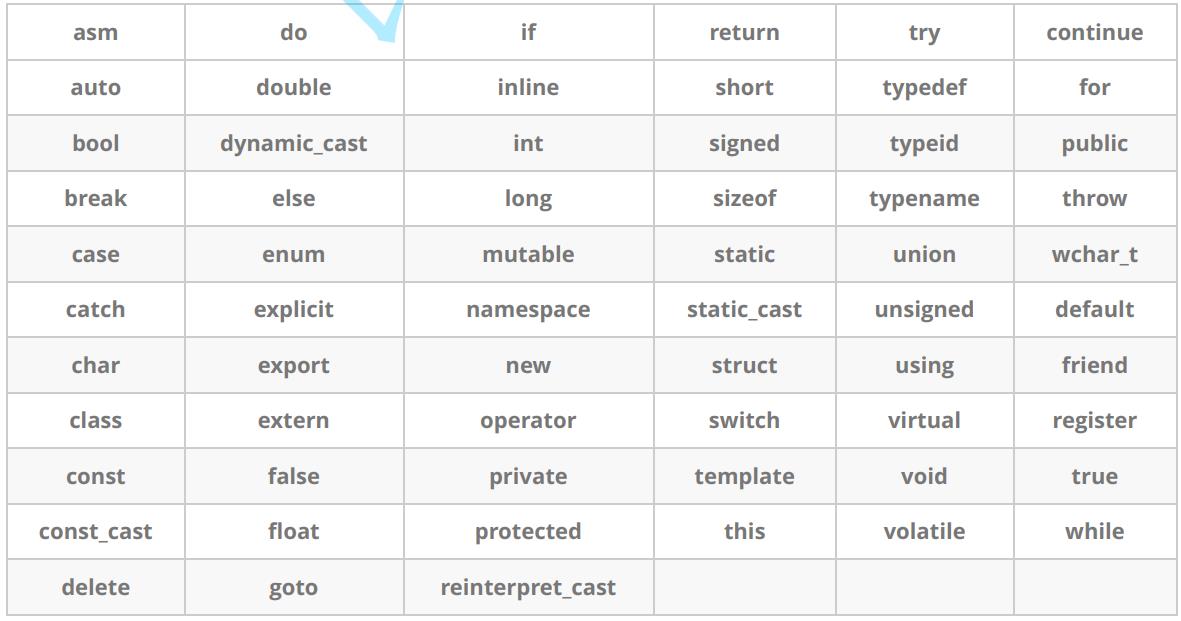
C++总计63个关键字,C语言32个关键字(C-98标准下)
C++的三大特征(这里只做了解)
继承
继承是为了提高代码的复用性与可扩展性。
封装
封装的目的是为了保证变量的安全性,使用者不必在意具体实现细节,而只是通过外部接口即可访问类的成员
多态
多态的目的是实现了动态联编,使程序运行效率更高,更容易维护和操作。
C语言与C++区别(没学过C语言的可以忽略)
这里列举几个,当然不全,初步了解一下,可以避免大多数的错误。
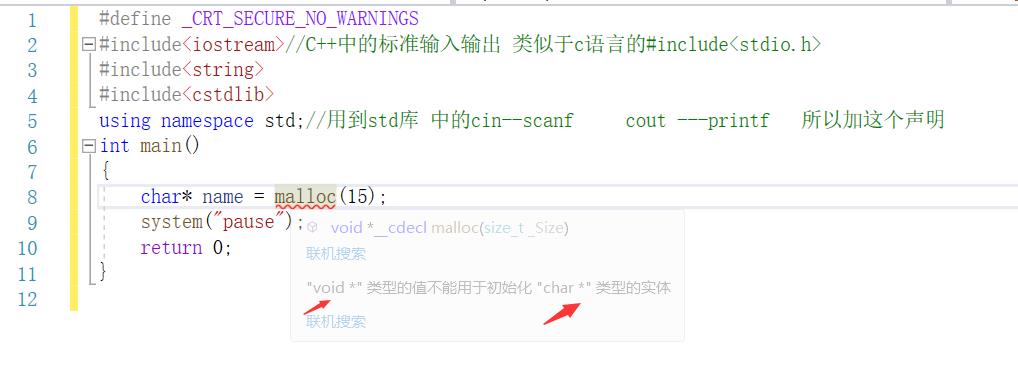
更严格的类型转换
这里可以看到C++项目下,malloc返回值void是不可以赋值给char的,必须要经过转换,所以下面这个报错语句应该写成 charname=(char)malloc(15);
而在c语言条件下只会报警告。
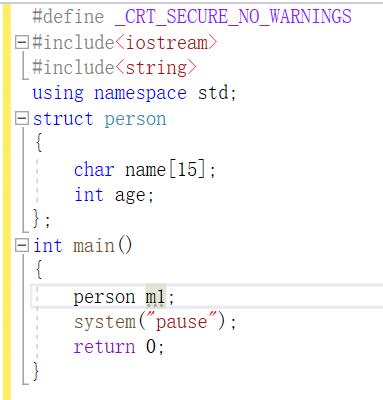
struct类型的优化
在c语言下面,若没有经过typedef重命名,则定义结构体变量必须加上struct,当然,是在函数体内部进行定义,你在结构体后定义那我没得说。
在C++下只需要 结构体名+变量名,不需要加struct关键字
三目运算符的区别
大家都知道在C语言程序下,三目运算符的返回值是一个数值(右值),但在C++底下返回的是左值
c语言下
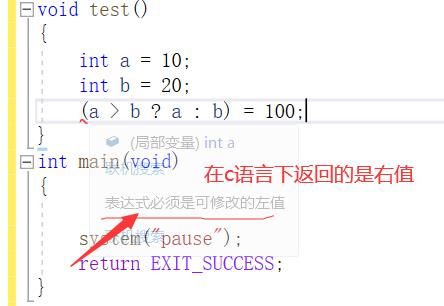
我们在C++底下再跑一下这样的程序
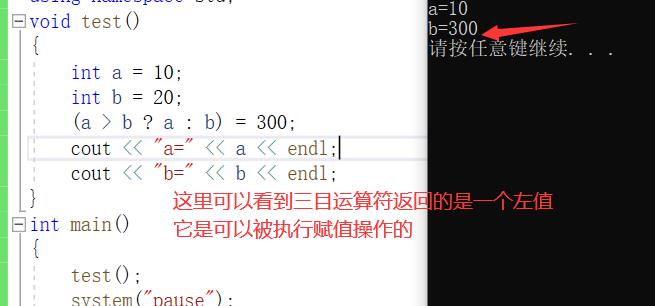
可以得出这样一个结论:c语言底下的三目运算符返回的是一个右值(数值),而c++底下返回的相当于是它返回的其实是a或者b的引用,也就是a或者b的别名,代表的是相同的一段存储空间,那么也就意味着能够通过引用开改变它们的值,也就是三目运算符能作为左值运算的原因。
const修饰变量的区别
相同点:定义为全局变量的数据都不可以被修改,直接间接都不可以
不同点:假如说定义在一个函数体内,它在编译时被存放在栈上,此时c语言是可以对它做出修改的。而c++不可以(语法上允许,但是没用)。
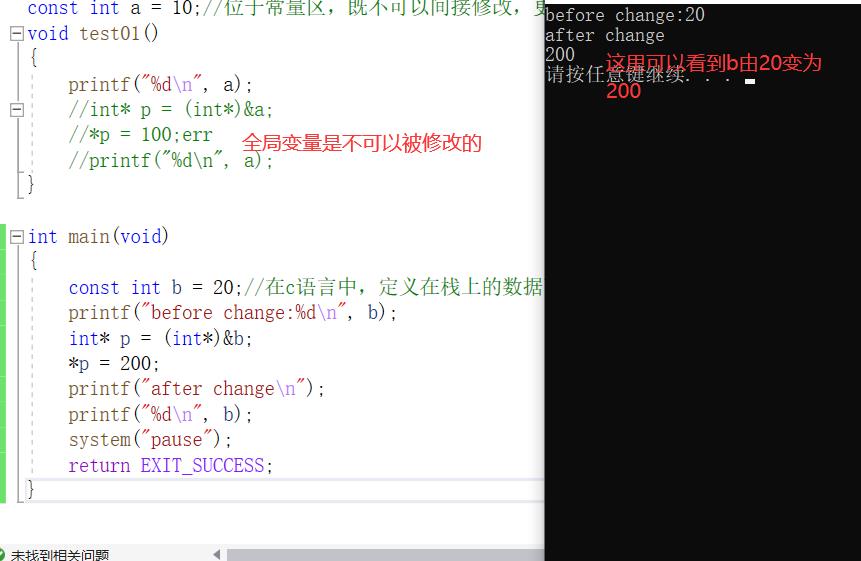
首先先看位于函数体内部c语言是怎么修改const变量的
int main(void)
{
const int b = 20;//在c语言中,定义在栈上的数据可以通过间接修改的方式达到修改某一区域的数据。
printf("before change:%d\\n",b);
int* p = (int*)&b;
*p = 200;
printf("after change\\n");
printf("%d\\n", b);
system("pause");
return EXIT_SUCCESS;
}
接下来我们看看c++的
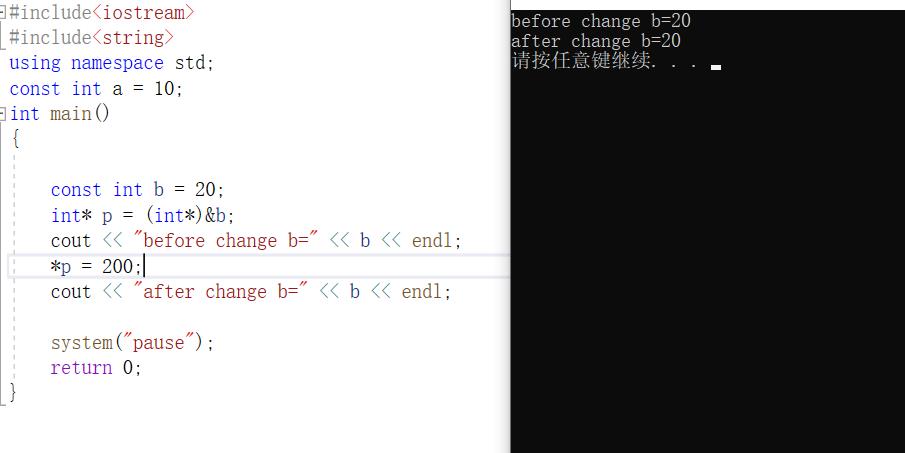
可以看到没有发生任何改变。这是为什么呢?
这是因为C++编译器在编译时候进行了常量折叠的操作。
所谓常量折叠:通常C++编译器并不为const创建存储空间,相反它把这个定义保存在它的符号表里。 相当于在编译的时候已经将b替换为20了,所以此时就算修改也对它毫无影响。 取决于const变量为内部连接的情况。如果为外部连接或者对它执行取地址操作、或者是加了volatile关键字、亦或将const变量作为左值,则此时编译器不会进行常量折叠,因为此时需要的是一个真正的常量地址。
为了验证常量折叠的操作,此时我们加上volatile关键字来禁止它执行常量折叠的情况,再试试,
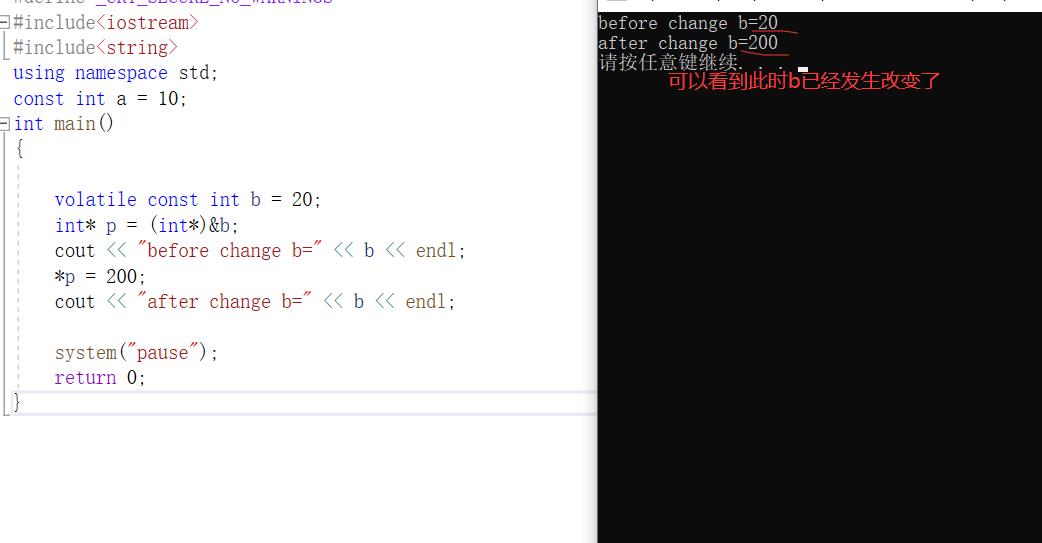
输入与输出的区别
C语言下输入输出标准库为#include<stdio.h>
C++输入输出标准库为#include
更简洁的输入输出
c语言:int a; scanf("%d",&a); c++: std::cin>>a;
输出: c语言、printf("%d\\n",a); c++ std::cout<<a;
命名空间
什么是命名空间
这里真的不好阐述,直接列个实例吧!
namespace +名称(不加也行)
{ 变量1;
变量2;
…
}
这就是个命名空间
为什么要提出命名空间?
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的 目的是对标识符的名称进行本地化,以避免命名冲突或名字污染, namespace关键字的出现就是针对这种问题的。
命名空间的书写
先给个结论,然后一个一个验证
1.命名空间是不可以写在函数体内部的
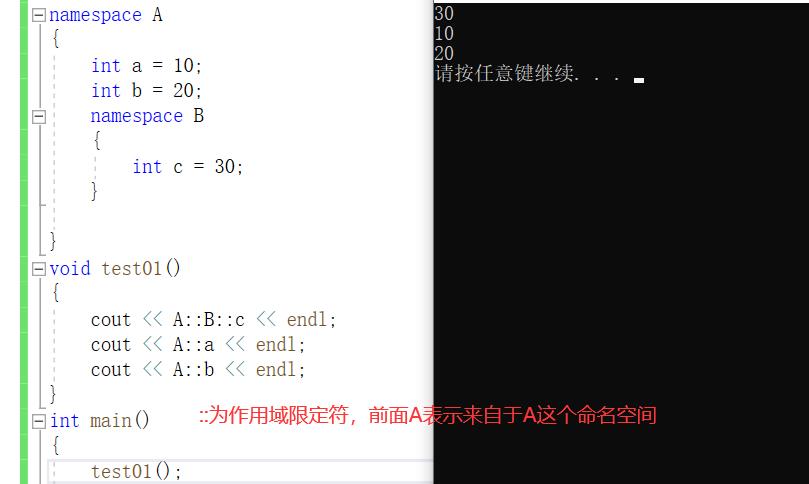
2.命名空间是可以进行嵌套的。
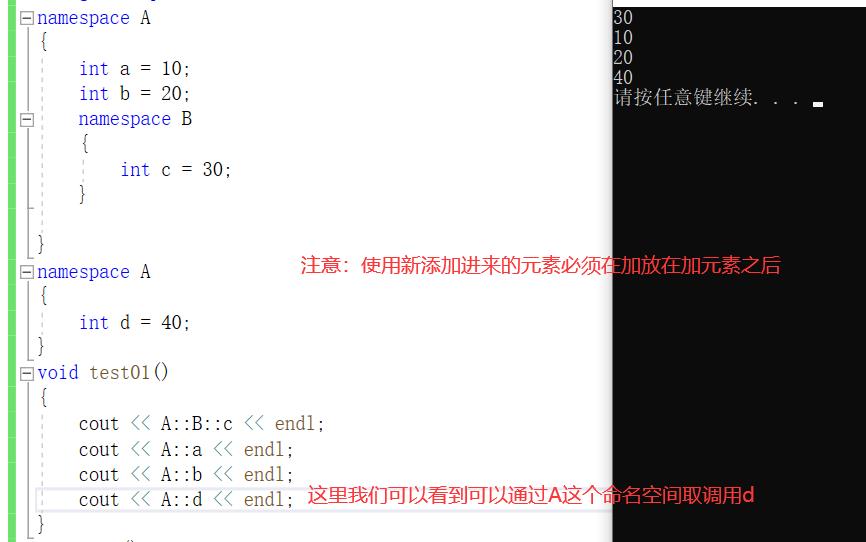
3.命名空间是可以在定义完添加元素的
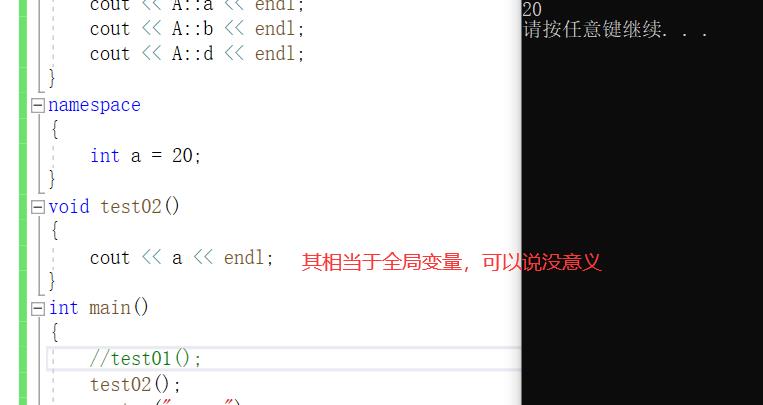
4.命名空间是可以不起名字的
5.命名空间是可以起别名的
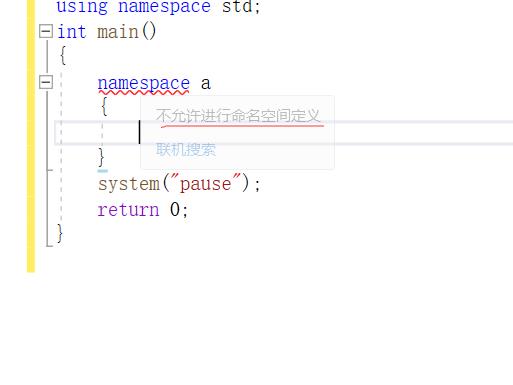
验证一、命名空间是不可以写在函数体内部的
验证二、命名空间是可以嵌套的
验证三、命名空间是可以定义完后再添加元素的
验证四、命名空间可以不起名字(没意义)
验证五、命名空间是可以取别名的
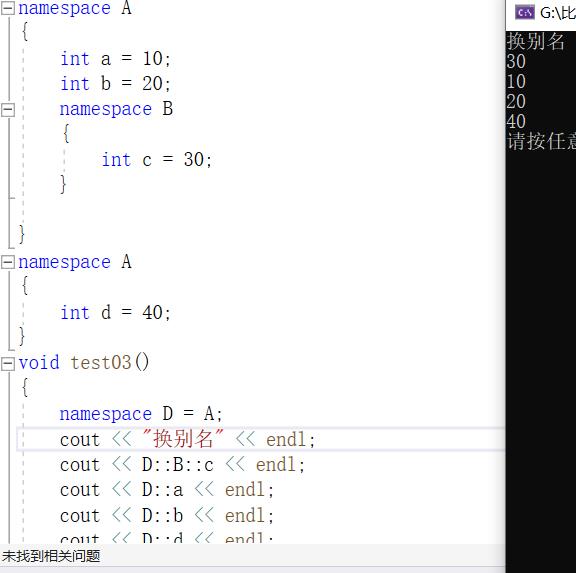
注cout<<::变量名<<endl;相当于去调用全局变量,::作用域限定符前不加任何参数的话默认情况下为全局变量。
using的使用
比如我们经常会在c++程序看到这样一个语句
using namespace std; 这个std就相当于是标准程序库所驻之命名空间(namespace)的名称。里面封装着 cin(标准输入)、cout(标准输出)、endl(换行)等。

缺省参数
什么是缺省参数
缺省参数就相当于是生活中的“备胎”,需要的时候用它,不需要的时候就不使用它。
int add(int a,int b=0)
{
return a+b;
}
void fun()
{
cout<<add(10)<<endl;//right 在执行时调用add(10,0)
cout<<add(10,20)<<endl;//right 因为此时有20这个存在,所以此时调用add(10,20);
}
C语言是不支持默认参数的,原因是C语言没有重载机制,反之面向对象的编写思想均可以实现带有默认参数的函数 。
不过我们可以利用宏来模拟实现
#define a 20
#define Fun(i) fun(i,a)
int fun(int x,int y)
{
return x+y;
}
int main(void)
{
printf("10+20=%d\\n", Fun(10));
system("pause");
return EXIT_SUCCESS;
}
缺省参数的作用
当我们要经常使用某一值时,我们就可以将这个参数的默认值置为该值,增加了运算的灵活性。当我们不需要它时,只需要给该位置传参,这样它就不会使用默认值。
缺省参数的注意事项
1.缺省参数的右边必须全为缺省参数
比如 int add(int a,int b=10,int c);
这是不允许的。因为程序不知道你传参到底是怎么传的。到底是给b还是给c赋值。
2.定义与声明中不可同时含有默认参数,不然会报重定义的错误。这很好理解,比如你在声明时给了一个默认参数,这时候定义的话又给一个不一样的默认参数,编译器怎么知道到底该使用哪一个默认参数。
3.
引用
引用概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
区分指针与引用
指针的作用
1.指向该部分的地址,起到节约内存的作用
引用:
用法:与指针一样,都是获取传递数据的内存,语法相对于指针来说更加的简便
本质:给这段空间取别名
引用的使用
引用来修改某一数据值
int a=10;
int &b=a;
b=20;
cout<<a<<endl;//a=20
引用作为函数参数
void fun(int &a)//此时传参时相当于int&a=b//相等于给b取别名
{
a=300;
}
void test()
{
int b=3;
fun(b);
cout<<b<<endl;
}
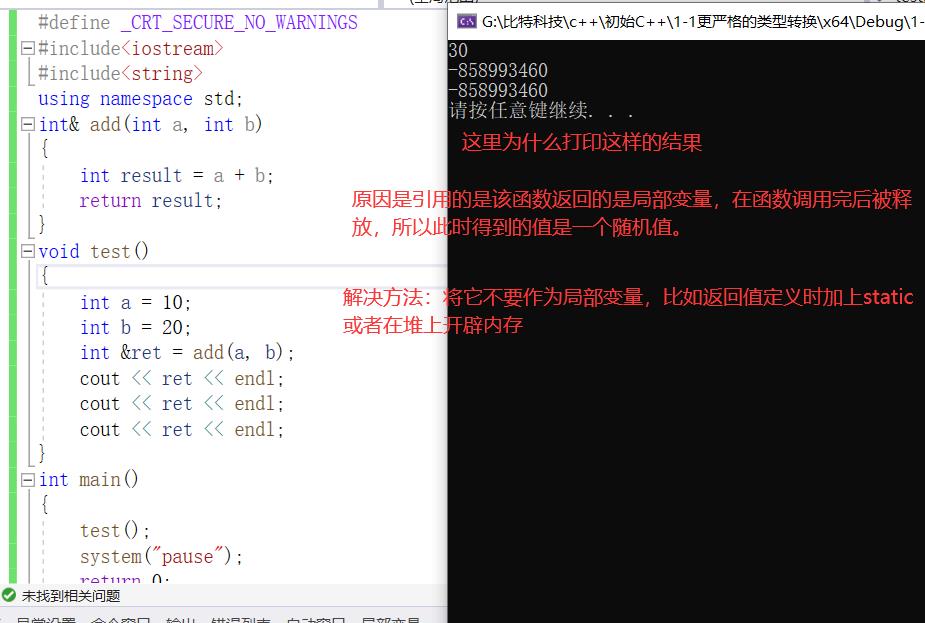
引用作为返回值
int& add(int a, int b)
{
int result = a + b;
return result;
}
void test()
{
int a = 10;
int b = 20;
int &ret = add(a, b);
cout << ret << endl;
cout << ret << endl;
cout << ret << endl;
}
引用数组
int arr[] = { 1,2,3,4,5 };
//定义引用数组的第一种方法
typedef int(parr)[5];
parr& a1 = arr;
//定义引用数组的第二种方法
typedef int(&parr1)[5];
parr1 a2 = arr;
//定义引用数组的第三种方法
int (&parr2)[5]=arr;
引用的本质
本质:引用的本质在c++内部实现是一个常指针.
Type& ref = val; // Type* const ref = &val;
在底层实现上实际是有空间的,因为引用是按照指针方式来实现的
引用的注意事项
//引用的注意
//1.int &a=b;只是起一个标志作用,表示给b取别名,而不是执行取址操作,在形参中也是一样的作用
void test01()
{
//int& b;//err,2.引用在创建的时候,必须执行初始化的操作
int a = 20;
int& b = a;//3.引用一旦生成,不可对其的指向进行修改
int c = 100;
b = c;//此处为赋值操作,并不是更改引用的指向
//4.引用必须引用一块合法的内存空间
}
三种传参对比
其中传值 最慢:因为它会在调用的时候将实参先形成一份拷贝,然后再使用传入的值。
指针与引用差不多:因为它在底层的实现与指针是相同。是一个常指针。
内联函数
什么是内联函数
内联函数就相当于是C语言中宏定义的那些短小的函数,在编译时会进行替换操作,执行效率较高。
语法:inline +返回值+ 函数名+(参数)
使用内联函数
inline int add(int a, int b)//内联函数定义
{
return a + b;
}
int main()
{
int ret = add(10, 20);
cout << ret << endl;
system("pause");
return 0;
}
这时看汇编,并没有执行call指令调用函数

内联函数的使用说明
什么情况下不可成为内联函数
1.函数体过于庞大
2.函数体中有循环语句
3.函数体进行取址操作(此时编译器无法做出优化)
4.函数体有较多的判断语句
内联函数的意义/好处
1.拥有着与宏定义一样的效率,同时消除了宏定义的弊端
2.内联函数会自动将类的成员函数变为内敛函数
内联函数的执行效率高的原理*
1.当调用一个内联函数的时候,编译器首先确保传入参数类型是正确匹配的(这点是define宏定义所不能比的),或者如果类型不正完全匹配,但是可以将其转换为正确类型,
2.并且返回值在目标表达式里匹配正确类型,或者可以转换为目标类型,内联函数就会直接替换函数调用,这就消除了函数调用的开销。
内联函数本质
本质:是向编译器进行申请内联函数的资格。能否变为内联函数取决于编译器是否给你这个权力,不给你你也没办法。简单点来说就是你加了inline也不一定会成为内联函数
函数重载
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 顺序)必须不同,常用来处理实现功能类似数据类型不同的问题。
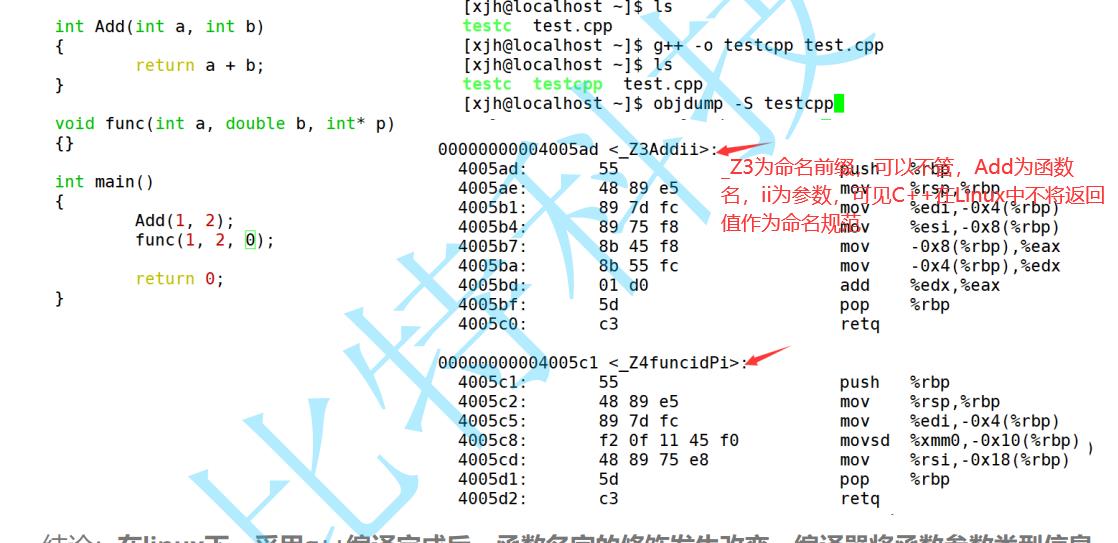
C语言可不可以使用函数重载?
答案是不行,这跟c语言的命名有关系
C语言在汇编文件中会给函数名后加上_+函数名 作为它的函数名。
函数重载的使用
重载方式:
1.函数参数个数不同
2.函数参数顺序不同
3.函数的参数类型不同
//函数参数不同
int add(int a, int b)
{
return a + b;
}
int add(int a)
{
return a;
}
//函数参数顺序不同
double add1(int a, double b)
{
return a + b;
}
double add1(double a, int b)
{
return a + b;
}
//参数类型不同
double add2(int a)
{
return a;
}
double add2(double a)
{
return a;
}
函数返回值不能作为函数参数的原因:
因为函数调用时是可以不接收返回值使用的。
这里提一下C++在编译时的命名规范问题
比如一个
void add(int a)
{
a=100;
}
int add(int a)
{
a=100;
return a;
}
这两个函数再调用时都可以直接写成add(10);//哪怕你不接受返回值
扩展
命名规则

define实现offsetof()
#define offsetof(StructType, MemberName) (size_t)&(((StructType *)0)->MemberName)
以上是关于C++从学渣到学霸之了解C++的主要内容,如果未能解决你的问题,请参考以下文章