EANet解读
Posted 周先森爱吃素
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了EANet解读相关的知识,希望对你有一定的参考价值。
最近关于MLP的工作还是蛮多的,先是MLP-Mixer为视觉开了个新思路,接着EANet(即External Attention)和RepMLP横空出世,乃至最新的《Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet》质疑Transformer中attention的必要性。由于我个人对自注意力是比较关注的,因此EANet通过线性层和归一化层即可替代自注意力机制还是很值得关注的。
论文作者最近发布了一篇解读在知乎上,补充了多头注意力的实现,感兴趣的可以参考一下,链接给出。
简介
自注意力其实早已在计算机视觉中有所应用,从较早的Non-Local到最近的Transformer,计算机视觉兜兜转转还是有回到全局感知的趋势。相比于卷积这种局部感知的操作,自注意力计算每个位置与其他所有位置信息的加权求和来更新当前位置的特征,从而捕获长程依赖(这在NLP中至关重要)获取全局信息。但是自注意力的劣势也是非常明显的,一方面自注意力对每个位置都要计算与其他位置的关系,这是一种二次方的复杂度,是非常消耗资源的;另一方面,自注意力对待每个样本同等处理,其实忽略了每个样本之间的潜在关系。针对此,清华计图团队提出了一种新的external attention(外部注意力),仅仅通过两个可学习的单元即可取代现有的注意力并将复杂度降到和像素数目线性相关,而且由于这个单元全数据集共享所以它能隐式考虑不同样本之间的关系。实验表明,由external attention构建的EANet在图像分类、语义分割、图像生成、点云分类和分割等任务上均达到甚至超越自注意力结构的表现,并且有着小得多的计算量和内存开销。
-
论文标题
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks
-
论文地址
https://arxiv.org/abs/2105.02358v1
-
论文源码
https://github.com/MenghaoGuo/-EANet
EA
论文中关于自注意力机制的发展就不多赘述了,这一节按照论文的思路来阐述一下External Attention。
Self-Attention
首先,不妨来回顾一下原始的自注意力机制,如下图a所示,给定输入特征图 F ∈ R N × d F \\in \\mathbb{R}^{N \\times d} F∈RN×d,这里的 N N N表示像素数目而 d d d则表示特征的维度也就是通道数目。自注意力首先通过三个线性投影将输入变换为query矩阵 Q ∈ R N × d ′ Q \\in \\mathbb{R}^{N \\times d^{\\prime}} Q∈RN×d′、key矩阵 K ∈ R N × d ′ K \\in \\mathbb{R}^{N \\times d^{\\prime}} K∈RN×d′和value矩阵 V ∈ R N × d V \\in \\mathbb{R}^{N \\times d} V∈RN×d,从而按照下面的式子计算自注意力的输出,这两个式子分别表示根据Query和Key计算相似性权重,然后将权重系数作用于Value得到加权求和的注意力结果。 至于这里的点积相似性只是相似性计算的一种方式而已。
A = ( α ) i , j = softmax ( Q K T ) F out = A V \\begin{aligned} &A =(\\alpha)_{i, j}=\\operatorname{softmax}\\left(Q K^{T}\\right) \\\\ &F_{\\text {out }} =A V \\end{aligned} A=(α)i,j=softmax(QKT)Fout =AV
在上面这个式子中, A ∈ R N × N A \\in \\mathbb{R}^{N \\times N} A∈RN×N表示注意力矩阵并且 α i , j \\alpha_{i, j} αi,j就是第 i i i个像素和第 j j j个像素之间的逐对相似性。
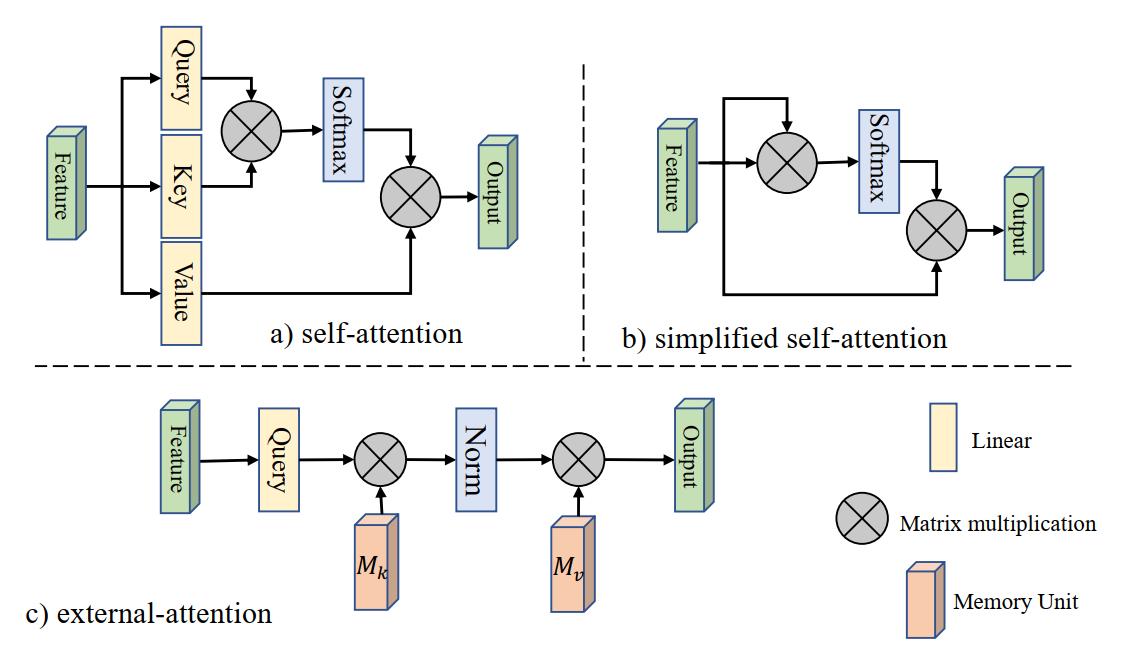
既然QKV的计算都是线性变换,因此可以省略这个过程直接对输入特征进行点积相似度的计算,从而得到注意力图,因而简化版的自注意力如下式,这对应上图的b。然而,这种算法虽然简化了,但是 O ( d N 2 ) \\mathcal{O}\\left(d N^{2}\\right) O(dN2)的计算复杂度大大限制了自注意力的使用,特别是用于图像这种像素众多的数据上,因此很多的工作都是patch之间计算自注意力而不是在pixel上计算。
A = softmax ( F F T ) F out = A F \\begin{aligned} &A =\\operatorname{softmax}\\left(F F^{T}\\right) \\\\ &F_{\\text {out }} =A F \\end{aligned} A=softmax(FFT)Fout =AF
External Attention
论文作者通过可视化注意力图,发现大部分像素其实只和少量的其他像素密切相关,因此构建一个N-to-N的注意力矩阵其实是非常冗余的。因此自然产生一个想法,能否通过少量需要的值来精炼原始的输入特征呢?这就诞生了external attention模块来替代原始的注意力,它在输入特征和一个外部单元 M ∈ R S × d M \\in \\mathbb{R}^{S \\times d} M∈RS×d计算注意力。
A = ( α ) i , j = Norm ( F M T ) F out = A M \\begin{aligned} &A =(\\alpha)_{i, j}=\\operatorname{Norm}\\left(F M^{T}\\right) \\\\ &F_{\\text {out }} =A M \\end{aligned} A=(α)i,j=Norm(FMT)Fout =AM
上面的式子表示EA的计算过程,这里的M是一个独立于输入的可学习参数,它相当于整个数据集的memory,因此它是所有样本共享的,可以隐式考虑所有样本之间的影响。A是通过先验推断出的注意力图,它类似于自注意力那样进行标准化,然后根据A和M对输入特征更新。
实际上,为了增强EA的表达能力,与自注意力相似,论文采用了两个记忆单元分别是 M k M_k Mk和 M v M_v Mv分别作为key和value,因此External Attention可以表示为下面修改后的式子。
A = Norm ( F M k T ) F out = A M v \\begin{aligned} &A =\\operatorname{Norm}\\left(F M_{k}^{T}\\right) \\\\ &F_{\\text {out }} =A M_{v} \\end{aligned} A=Norm(FMkT)Fout =AMv
从这个式子和上面的图c不难发现,EA的计算过程其实就是线性运算和Norm层,源码中线性层采用的是1x1卷积实现的,Norm层的实现下面会提到。整个EA的计算复杂度其实为 O ( d S N ) \\mathcal{O}(d S N) O(dSN),S和d都是超参数,这个复杂度因此和像素数目线性相关了,通过修改S的大小可以方便地控制计算的复杂度,事实上,实验中,作者发现S设置为64效果就已经很好了。因此,EA通过线性层就替代了自注意力机制并且非常高效轻量,非常适用于大尺度的输入特征图。
Normalization
在自注意力中,Softmax常被用于注意力图的标准化以实现 ∑ j α i , j = 1 \\sum_{j} \\alpha_{i, j}=1 ∑jαi,j=1,然而注意力图常常通过矩阵乘法计算得到,不同于余弦相似度,这种算法的相似度是尺度敏感的。因此作者对double-attention优化得到了下面这个分别行列进行标准化的方法。
(
α
~
)
i
,
j
=
F
M
k
T
α
i
,
j
=
exp
(
α
~
i
,
j
)
∑
k
exp
(
α
~
k
,
j
)
α
i
,
j
=
α
i
,
j
∑
k
α
i
,
k
\\begin{aligned} (\\tilde{\\alpha})_{i, j} &=F M_{k}^{T} \\\\ \\alpha_{i, j} &=\\frac{\\exp \\left(\\tilde{\\alpha}_{i, j}\\right)}{\\sum_{k} \\exp \\left(\\tilde{\\alpha}_{k, j}\\right)} \\\\ \\alpha_{i, j} &=\\frac{\\alpha_{i, j}}{\\sum_{k} \\alpha_{i, k}} \\end{aligned}
(α~)i,jαi,jαi,j=FMkT=∑kexp(α~k,j)exp(α~i,j)=∑kαi,k