不懂ZAB,敢说掌握Zookeeper?
Posted Java编程之道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不懂ZAB,敢说掌握Zookeeper?相关的知识,希望对你有一定的参考价值。
ZAB协议
国庆八天乐就这样结束了!2020年没有假期了!同学你难受吗?

今天先简单聊聊ZAB协议,个人认为搞懂ZAB协议和Leader选举算法的关系和流程对于深入认识Zookeeper是一个必不可少的环节。
「请允许我盼过年!」
Zookeeper
❝百度百科:ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。
它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等
❞
zookeeper是一个很热门的分布式框架,熟练掌握ZK的基本使用、分布式锁的实现以及相关场景的运用是必不可少的。鄙人有幸在Shopee的面试中被问过ZAB协议以及Learder选举流程,所以在此做一个总结,分享给大家自己的理解,愿对你有所帮助。
今天不介绍ZK的基础使用,仅对ZK中的ZAB协议的理解进行一个分享,如有不足之处欢迎大家指出。
ZAB协议
❝ZAB 协议全称:Zookeeper Atomic Broadcast(Zookeeper 原子广播协议)。
❞
Zookeeper 是一个为分布式应用提供高效且可靠的分布式协调服务。在CAP理论中Zookeeper 属于CP模型,强调各个节点间数据强一致性,通过zab协议建立一个高可用可扩展的分布式数据主备系统。
-
深刻理解ZAB协议,才能更好的理解zookeeper对于分布式系统建设的重要性。以及为什么采用zookeeper就能保证分布式系统中数据最终一致性,服务的高可用性。
ZAB协议原理
ZAB协议要求每个leader都要经历三个阶段,即发现,同步,广播。
-
「发现」:即要求zookeeper集群必须选择出一个leader进程,同时leader会维护一个follower可用列表。将来客户端可以和follower中的节点进行通信。 -
「同步」:leader要负责将本身的数据与follower完成同步,做到多副本存储。这样也是体现了CAP中高可用和分区容错。follower将队列中未处理完的请求消费完成后,写入本地事物日志中。 -
「广播」:leader可以接受客户端新的proposal请求,将新的proposal请求广播给所有的follower。
应用范畴
-
原子广播(Leader可用时) -
崩溃恢复(Leader不可用时)
下面我会重点讲这两个东西。
zookeeper根据ZAB协议建立了主备模型完成zookeeper集群中数据的同步。这里所说的主备系统架构模型是指,在zookeeper集群中,只有一台leader负责处理外部客户端的事务请求(或写操作),然后leader服务器将客户端的写操作数据同步到所有的follower节点中。
「注意:」
-
所有的操作都由Learder发出,即时客户端向Fllower发出请求,最终它会把这个请求交给Leader处理。
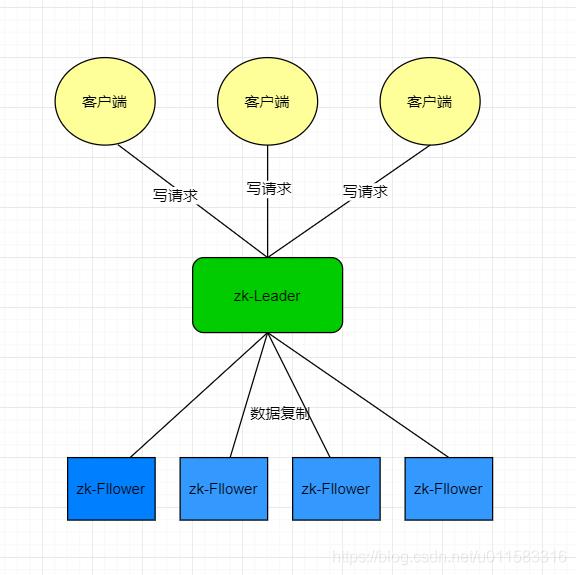
数据是如何复制的呢?
其实zab协议下的数据复制类似于2PC。但ZAB只需要Follower有一半以上返回Ack信息就可以执行commit提交。接收到半数Ack就提交的方式,可以大大减少同步阻塞,避免过长等待所有节点的反馈才进行操作(要么全部成功要么全部失败)。
如何理解这句话将直接影响你对於ZAB的理解。所以请继续往后看!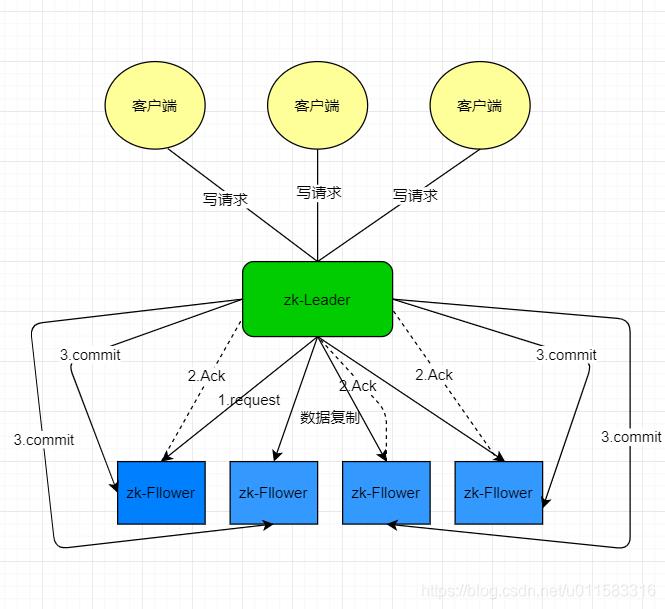
图解
-
zk集群中只有一个节点即Leader将客户端的写操作 转化为事务(或提议-proposal)--记住这个proposal的含义他会贯穿zk的整个体系。 -
Leader节点在数据写完之后,将向所有的follower节点发送数据广播(复制)请求,等待所有的follower节点 反馈(Ack)。 -
待Leader接收到超过半数follower节点反馈(Ack),Leader节点就会向所有的follower服务器 发送commit(事务提交)消息。 -
最后数据同步到follower上,完成数据同步。
消息广播
在Zookeeper集群中,Fllower和Leader之间的通信是通过消息队列来实现的,消息队列的加入降低了耦合度,解除了同步阻塞。
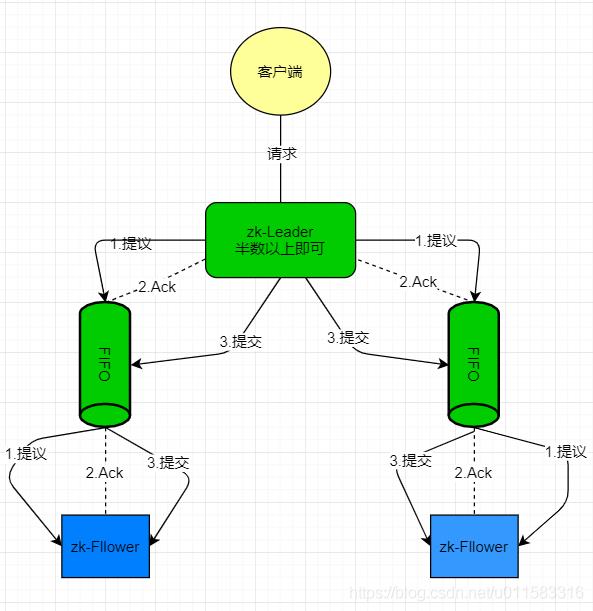
「Zookeeper中消息广播的具体步骤如下」:
-
客户端发起一个写操作请求 ,Leader服务器将客户端的request请求转化为事物proposql提案,同时为每个proposal分配一个 全局递增唯一的ID,即ZXID(事务ID)。 -
leader服务器与每个follower之间都有一个队列,leader将消息发送到该队列 。 -
follower机器从队列中取出消息处理完( 写入本地事物日志中)毕后,向leader服务器发送ACK确认。 -
leader服务器收到半数以上的follower的ACK后,即认为可以发送commit 。leader向所有的follower服务器发送commit消息。
崩溃恢复
❝在刚刚我们说的消息广播过程中,Leader在某个时间节点突然崩溃下线了我们又该如何保证数据的一致性,比如Leader本地提交了,但是commit没有发送?
❞
Zab协议在原Leader崩溃后会立即要求zookeeper集群进行崩溃恢复和leader选举。我们先简单聊一下崩溃恢复的机制。
ZAB协议崩溃恢复要求满足如下2个原则:
-
确保已经被leader提交的proposal(提议) 必须最终被所有的follower服务器提交。 -
确保 丢弃已经被leader发出的但是没有被提交的proposal。
所以,ZAB设计了以下的选举算法:
前面我们提交到每个客户端请求都会被Leader包装成一个拥有唯一递增的事务ID,如果我们可以保证新选举的leader节点中含有最高的ZXID。那么就可以满足ZAB协议的两个重要原则。这样做可以省去 Leader 服务器检查事务的提交和丢弃工作的这一步操作
「Why?」
在Leader崩溃之前,所有的从队列里面取出事务来处理的Fllower的事务ID应该是一样的。如果我们从现有的Fllower中可以选举出最高的ZXID所在的服务器:
-
假设:leader在提出proposal时未提交之前就崩溃,那么我们找到的最大的ZXID所在的服务器一定不包含未提交的提议(proposal)。 -
假设:leader在发送commit消息之后崩溃。即消息已经发送到队列中,期间该被提交(commit)的提议(proposal)会被Fllower处理,那么我们一定可以找到一个ZXID最大的服务器。即该follower节点将会被选举为最新的Leader。
「在选举出Leader后需要进行的就是Leader和Fllower之间的数据同步。」
数据同步
❝关于数据同步Zookeeper中数据同步一共有四类,如下:
❞
DIFF:直接差异化同步 TRUNC+DIFF:先回滚再差异化同步 TRUNC:仅回滚同步 SNAP:全量同步
本次就不对其中的四种方式一一细说,大家可以参阅《Zookeeper-数据同步》这篇文章,在此我只是笼统的介绍一下ZK的数据同步概念。
Zookeeper集群中新的leader选举成功之后,leader会将自身的提交的最大提议(proposal)的事务ZXID发送给其他的follower节点。follower节点会根据leader的消息进行回退或者是数据同步操作。具体流程请移步《Zookeeper-数据同步》。
「Zookeeper集群如何保证新选举的leader分配的ZXID是全局唯一呢?」
ZXID是一个长度64位的数字,其中低32位是按照数字递增,即每次客户端发起一个proposal,低32位的数字简单加1。高32位是leader周期的epoch编号,每当选举出一个新的leader时,新的leader就从本地事物日志中取出ZXID,然后解析出高32位的epoch编号,进行加1,再将低32位的全部设置为0。这样就保证了每次新选举的leader后,保证了ZXID的唯一性而且是保证递增的。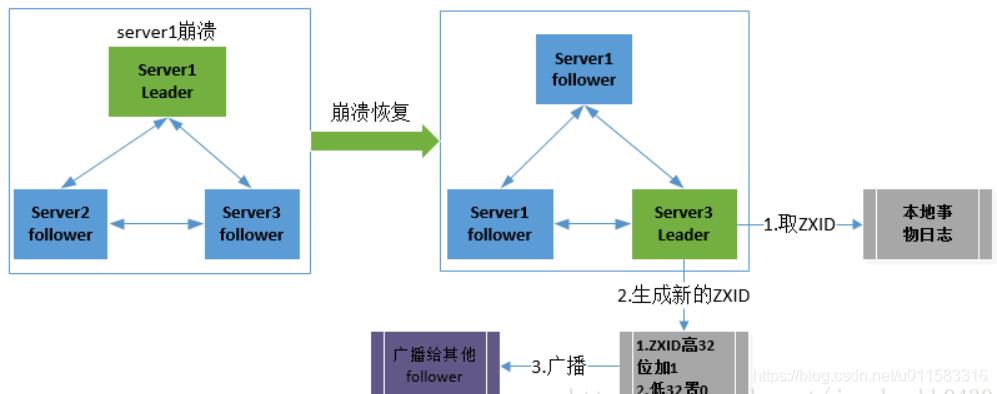
总结
关于ZAB协议的介绍暂时就这么多了,Zookeeper通过ZAB协议来保证Zookeeper集群的强一致性其核心在于类2PC的数据复制方法以及ZXID的唯一性设计。
Zookeeper-数据同步:https://www.cnblogs.com/youngchaolin/p/13211752.html
end
♥有热门推荐♥
1.
2.
3.
4.
5.

扫描二维码更精彩
以上是关于不懂ZAB,敢说掌握Zookeeper?的主要内容,如果未能解决你的问题,请参考以下文章