分库分表之Sharding-JDBC
Posted FINANCE RETAIL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分库分表之Sharding-JDBC相关的知识,希望对你有一定的参考价值。
课程目标
1、掌握Sharding-JDBC的使用方式,掌握自定义分片算法的配置
2、掌握分布式事务、全局ID等问题的解决方案
3、理解Sharding-JDBC的工作流程和实现原理
4、理解基于客户端的分库分表方案和基于代理的分库分表方案的差别
内容定位
适合已经理解了分库分表的意义、分库分表的类型,不知道如何实现在客户端实现分库分表的同学
1 架构与核心概念
https://gitee.com/Sharding-Sphere/sharding-sphere
1.1 回顾
数据源选择的解决方案层次:
DAO:AbstractRoutingDataSource
ORM:MyBatis插件
JDBC:Sharding-JDBC
Proxy:Mycat、Sharding-Proxy
Server:特定数据库或者版本
1.2 发展历史
它是从当当网的内部架构ddframe里面的一个分库分表的模块脱胎出来的,用来解决当当的分库分表的问题,把跟业务相关的敏感的代码剥离后,就得到了Sharding-JDBC。它是一个工作在客户端的分库分表的解决方案。
DubboX,Elastic-job也是当当开源出来的产品。
2018年5月,因为增加了Proxy的版本和Sharding-Sidecar(尚未发布),Sharding-JDBC更名为ShardingSphere,从一个客户端的组件变成了一个套件。
2018年11月,Sharding-Sphere正式进入Apache基金会孵化器,这也是对
Sharding-Sphere的
质量和影响力的认可。
不过现在还没有毕业(名字带incubator),一般我们用的还是io.shardingsphere的包。
现在Sharding-Sphere已经不属于当当网,也不属于作者张亮个人了。
因为更名后和捐献给Apache之后的groupId都不一样,在引入依赖的时候千万要注意。主体功能是相同的,但是在某些类的用法上有些差异,如果要升级的话import要全部修改,有些类和方法也要修改。
1.3 基本特性
Sharding-JDBC是怎么工作的?
https://shardingsphere.apache.org/document/current/cn/overview/
我们看一下官网的定义:
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
在maven的工程里面,我们使用它的方式是引入依赖,然后进行配置就可以了,不用像Mycat一样独立运行一个服务,客户端不需要修改任何一行代码,原来是SSM连接数据库,还是SSM,因为它是支持MyBatis的。
1.4 架构
我们在项目内引入Sharding-JDBC的依赖,我们的业务代码在操作数据库的时候,就会通过Sharding-JDBC的代码连接到数据库。
分库分表的一些核心动作,比如SQL解析,路由,执行,结果处理,都是由它来完成的。它工作在客户端。
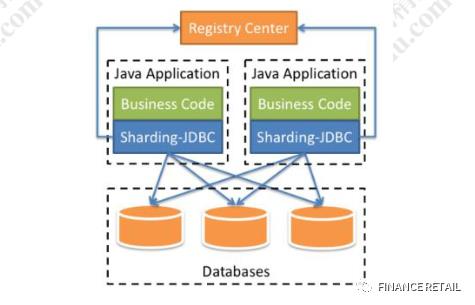
在Sharding-Sphere里面同样提供了代理Proxy的版本,跟Mycat的作用是一样的。Sharding-Sidecar是一个Kubernetes的云原生数据库代理,正在开发中。
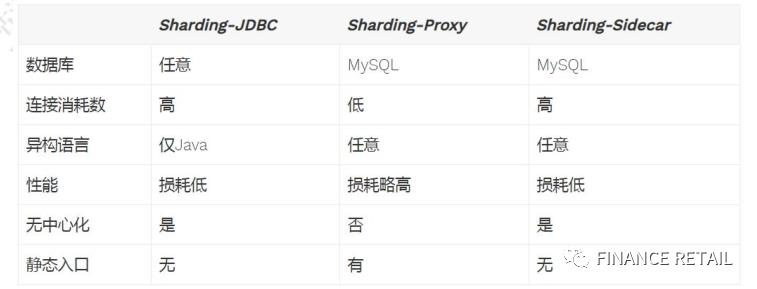
1.5 功能
分库分表后的几大问题:跨库关联查询、分布式事务、排序翻页计算、全局主键。
1.5.1数据分片
1、分库&分表
2、读写分离
https://shardingsphere.apache.org/document/current/cn/features/read-write-split/
3、分片策略定制化
4、无中心化分布式主键(包括UUID、雪花、LEAF)
https://shardingsphere.apache.org/document/current/cn/features/sharding/other-features/key-generator/
1.5.2分布式事务
https://shardingsphere.apache.org/document/current/cn/features/transaction/
1、标准化事务接口
2、XA强一致事务
3、柔性事务
1.6 核心概念
https://shardingsphere.apache.org/document/current/cn/features/sharding/concept/sql/
逻辑表、真实表、分片键、数据节点、动态表、广播表、绑定表
1.6.1 主要概念
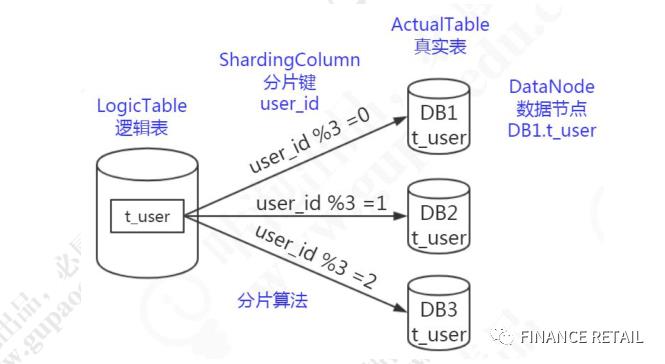
逻辑表会在SQL解析和路由时被替换成真实的表名。
分片键不一定是主键,也不一定有业务含义。
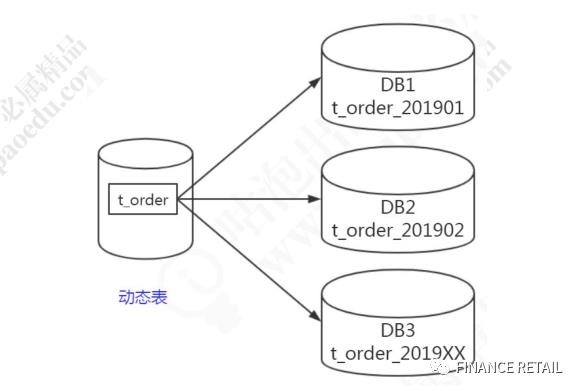
1.6.2 动态表
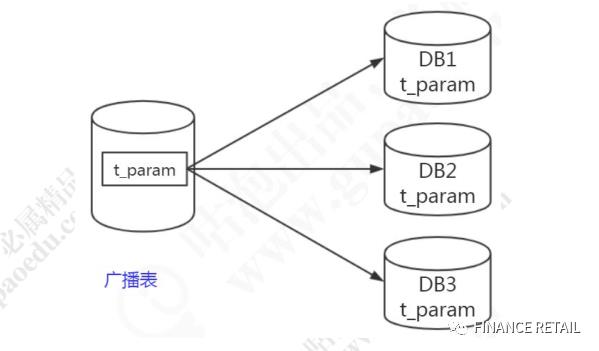
1.6.3 广播表
跟Mycat的全局表对应
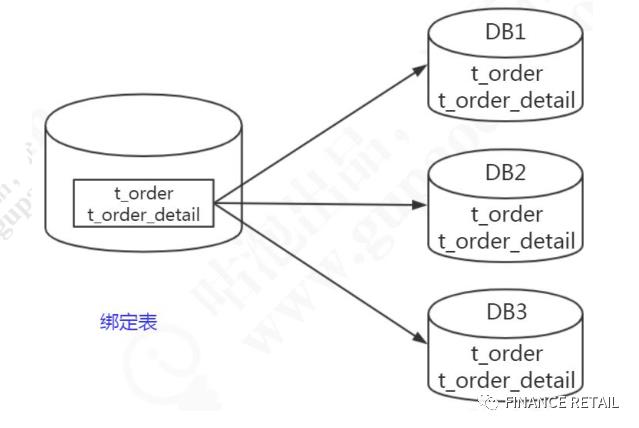
1.6.4 绑定表
跟Mycat的ER表对应
1.7 使用规范
不支持的SQL:
https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/sql/
分页的说明:
https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/pagination/
2 Sharding-JDBC实战
快速入门
https://shardingsphere.apache.org/document/current/cn/quick-start/sharding-jdbc-quick-start/
2.1 引入依赖
注意,在SpringBoot中使用Sharding-JDBC,可以直接引入sharding-jdbc的依赖。注意组织名称(groupId)的区别:
org.apache.shardingsphere:捐献给Apache之后
包名和某些类有差异,如果替换需要注意,import的包名都需要修改。
核心依赖是(artifactId):sharding-jdbc-core和sharding-core
前面两个group在SpringBoot中还提供了starter,Apache暂时没有。
2.2 原生JDBC使用
回顾:JDBC
gupao-shard-prop工程com.gupaoedu.jdbc.JdbcTest
gupao-shard-yml工程com.gupaoedu.jdbc.ShardJDBCTest



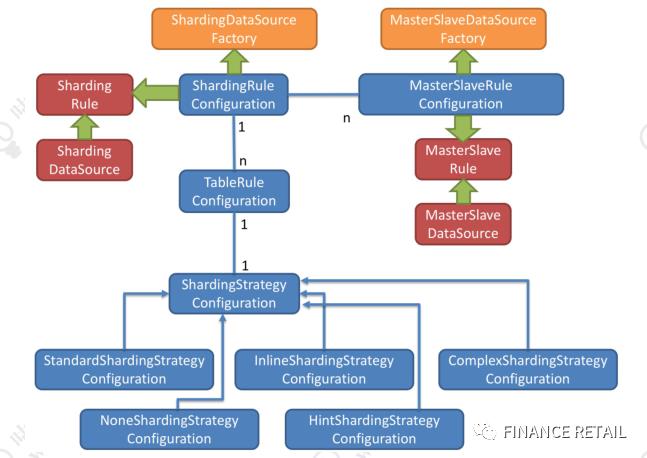
总结:ShardingRuleConfiguration可以包含多个TableRuleConfiguration(多张表),也可以设置默认的分库和分表策略。
每个TableRuleConfiguration可以针对表设置ShardingStrategyConfiguration,包括分库分分表策略。
ShardingStrategyConfiguration有5种实现(标准、行内、复合、Hint、无)。
ShardingDataSourceFactory利用ShardingRuleConfiguration创建数据源。
在JDBC中使用,我们可以直接创建数据源,如果在Spring中使用,我们自定义的数据源怎么定义使用呢?可以通过注解或者xml配置文件注入。
2.3 Spring中使用
先来总结一下,因为我们要使用Sharding-JDBC去访问数据库,所以我们不再使用ORM框架或者容器去定义数据源,而是注入Sharding-JDBC自定义的数据源,这样才能保证动态选择数据源的实现。
第二个,因为Sharding-JDBC是工作在客户端的,所以我们要在客户端配置分库分表的策略。跟Mycat不一样的是,Sharding-JDBC没有内置各种分片策略和算法,需要我们通过表达式或者自定义的配置文件实现。我们创建的数据源中包含了分片的策略。
总体上,需要配置的就是这两个,数据源和分片策略,当然分片策略又包括分库的策略和分表的策略。
https://shardingsphere.apache.org/document/current/cn/manual/sharding-jdbc/configuration/config-java/
位置:4.用户手册——4.1Sharding-JDBC——4.1.2配置手册
2.3.1 Java配置
第一种是把数据源和分片策略都写在JavaConfig中,它的特点是非常灵活,我们可以实现各种定义的分片策略。但是缺点是,如果把数据源、策略都配置在JavaConfig中,就出现了硬编码,在修改的时候比较麻烦。
2.3.2 SpringBoot配置
第二种是直接使用SpringBoot的application.properties来配置,这个要基于
starter模块,org.apache.shardingsphere的包还没有starter,只有io.shardingsphere的包有starter。
把数据源和分库分表策略都配置在properties文件中。这种方式配置比较简单,但是不能实现复杂的分片策略,不够灵活。
2.3.3 yml配置
第三种是使用SpringBoot的yml配置(shardingjdbc.yml),也要依赖starter模块。当然我们也可以结合不同的配置方式,比如把分片策略放在JavaConfig中,数据源配置在yml中或properties中。
2.4 Spring案例验证(gupao-shard-prop工程)
我们这里验证的是切分到本地的两个库ds0,ds1。
注意:之前Mycat的课程演示,不同的数据节点都在不同的机器上,这里我们以同一数据库服务中不同的database来替代。无论是多个IP的多个库还是一个IP的多个库,对于验证来说没有区别。
两个库里面都是相同的4张表(user_info,t_order,t_order_item,t_config),(sys_user是AbstractRoutingDataSource用的,不用管)。
这些表必须提前创建,中间件是不会帮我们生成表结构的。
然后我们用MyBatis的Generator生成相应的实体类、Mapper接口和映射器。
对数据库的基本的SSM的操作弄完了,接下来就是分库分表的配置,一个是数据源,
我们先来看一下我们的数据源的配置application.properties。

当我们使用了Sharding-JDBC的数据源以后,对于数据的操作会交给
Sharding-JDBC的代码来处理。
分片策略从维度上分成两种,一种是分库,一种是分表。
我们可以定义默认的分库分表策略(配置中注释了),例如:用user_id作为分片键。这里用到了一种分片策略的实现,叫做行内表达式。我们对user_id取模,然后选择数据库。如果模2等于0,在第一个数据库中。模2等于1,在第二个数据库中。

对于不同的表,也可以单独配置分库策略(databaseStrategy)和分表策略(tableStrategy)。案例中只有分库没有分表,所以没定义tableStrategy。

2.4.1 取模分片
我们用user_info表来验证取模分片。根据user_id,把用户数据划分到两个数据节点上。
在本地创建两个数据库ds0和ds1,都创建user_info表:

这里只定义了分库策略,没有定义单库内的分表策略,两个库都是相同的表名。
路由的结果:ds0.user_info,ds1.user_info。
如果定义了分库策略,两个库里面都有两张表,那么路由的结果可能是4种:

gupao-shard-prop工程:
在我们的单元测量测试类UserShardingTest里面,执行insert(),调用Mapper接口循环插入100条数据。
我们看一下插入的结果。user_id为偶数的数据,都落到了第一个库。user_id为奇数的数据,都落到了第二个库。
执行select()测一下查询,看看数据分布在两个节点的时候,我们用程序查询,能不能取回正确的数据。
2.4.2 绑定表
第二种是绑定表,也就是父表和子表有关联关系。主表和子表使用相同的分片策略。


除了定义分库和分表算法之外,我们还需要多定义一个binding-tables。

什么叫笛卡尔积?假如有2个数据库,两张表要相互关联,两张表又各有分表,那么SQL的执行路径就是2*2*2=8种。
gupao-shard-yml工程:com.gupaoedu.OrderTest#selectOrderItem

2.4.3 广播表
最后一种是广播表,也就是需要在所有节点上同步操作的数据表。

如果我们需要更加复杂的分片策略,properties文件中行内表达式的这种方式肯定满足不了。实际上properties里面的分片策略可以指定,比如user_info表的分库和分表策略。

这个时候我们需要了解Sharding-JDBC中几种不同的分片策略。
3 分片策略详解(gupao-shard-java)
https://shardingsphere.apache.org/document/current/cn/features/sharding/concept/sharding/
Sharding-JDBC中的分片策略有两个维度:分库(数据源分片)策略和分表策略。
分库策略表示数据路由到的物理目标数据源,分表分片策略表示数据被路由到的目标表。分表策略是依赖于分库策略的,也就是说要先分库再分表,当然也可以不分库只分表。
跟Mycat不一样,Sharding-JDBC没有提供内置的分片算法,而是通过抽象成接口,让开发者自行实现,这样可以根据业务实际情况灵活地实现分片。
3.1 分片策略
包含分片键和分片算法,分片算法是需要自定义的。可以用于分库,也可以用于分表。
Sharding-JDBC提供了5种分片策略,这些策略全部继承自ShardingStrategy。
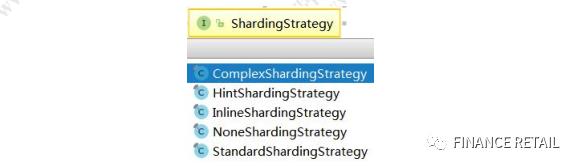
3.1.1 行表达式分片策略
https://shardingsphere.apache.org/document/current/cn/features/sharding/other-features/inline-expression/
对应InlineShardingStrategy类。只支持单分片键,提供对=和IN操作的支持。行内表达式的配置比较简单。
${[unit1,unit2,unit_x]}表示枚举值
t_user_$->{u_id%8}表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。
行表达式中如果出现连续多个${expression}或$->{expression}表达式,整个表
达式最终的结果将会根据每个子表达式的结果进行笛卡尔组合。
${['db1','db2']}_table${1..3}
db1_table1,db1_table2,db1_table3,
db2_table1,db2_table2,db2_table3
3.1.2 标准分片策略
对应StandardShardingStrategy类。
标准分片策略只支持单分片键,提供了提供PreciseShardingAlgorithm和
RangeShardingAlgorithm两个分片算法,分别对应于SQL语句中的=,IN和BETWEENAND。
如果要使用标准分片策略,必须要实现PreciseShardingAlgorithm,用来处理=和IN的分片。RangeShardingAlgorithm是可选的。如果没有实现,SQL语句会发到所有的数据节点上执行。
3.1.3 复合分片策略
比如:根据日期和ID两个字段分片,每个月3张表,先根据日期,再根据ID取模。
对应ComplexShardingStrategy类。可以支持等值查询和范围查询。
复合分片策略支持多分片键,提供了ComplexKeysShardingAlgorithm,分片算法需要自己实现。
3.1.4Hint分片策略
对应HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。有点类似于Mycat的指定分片注解。
https://shardingsphere.apache.org/document/current/cn/manual/sharding-jdbc/usage/hint/
3.1.5 不分片策略
对应NoneShardingStrategy。不分片的策略。
3.2 分片算法
创建了分片策略之后,需要进一步实现分片算法。Sharding-JDBC目前提供4种分片算法。
3.2.1 精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
3.2.2 范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。需要配合StandardShardingStrategy使用。
如果不配置范围分片算法,范围查询默认会路由到所有节点。
3.2.3 复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
3.2.4 Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
https://shardingsphere.apache.org/document/current/cn/manual/sharding-jdbc/usage/hint/
3.2.5 算法实现
所有的算法都需要实现对应的接口,实现doSharding()方法:
例如:PreciseShardingAlgorithm


4 分布式事务(shard-gupao-yml)
4.1 事务概述
https://shardingsphere.apache.org/document/current/cn/features/transaction/
4.2 两阶段事务-XA
com.gupaoedu.TransactionTest


模拟在两个节点上操作,id=12673、id=12674路由到两个节点,第二个节点插入两个相同对象,发生主键冲突异常,会发生回滚。
XAShardingTransactionManager——XATransactionManager——AtomikosTransactionManager
4.3 柔性事务Saga
ShardingSphere的柔性事务已通过第三方SPI实现Saga事务,Saga引擎使用
Servicecomb-Saga。
参考官方的这篇文章《分布式事务在Sharding-Sphere中的实现》

4.4 柔性事务Seata
https://github.com/seata/seata
https://github.com/seata/seata-workshop
https://mp.weixin.qq.com/s/xfUGep5XMcIqRTGY3WFpgA
GTS的社区版本叫Fescar(Fast&EasyCommitAndRollback),Fescar改名后叫SeataAT(SimpleExtensibleAutonomousTransactionArchitecture)。
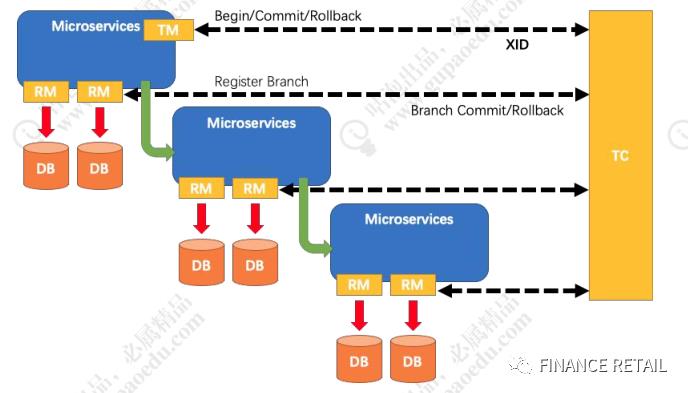
需要额外部署Seata-server服务进行分支事务的协调。
官方的demo中有一个例子:
https://github.com/apache/incubator-shardingsphere-example
incubator-shardingsphere-example-devsharding-jdbc-example ransaction-example ransaction-base-seata-raw-jdbc-example
5 分布式全局ID(shard-gupao-yml)
https://shardingsphere.apache.org/document/current/cn/features/sharding/other-features/key-generator/
在shard-gupao-yml中,使用key-generator-column-name配置,生成了一个18位的ID。

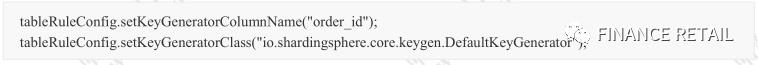
keyGeneratorColumnName:指定需要生成ID的列
KeyGenerotorClass:指定生成器类,默认是DefaultKeyGenerator.java,里面使用了雪花算法。
6 Sharding-JDBC工作流程
内核剖析
https://shardingsphere.apache.org/document/current/cn/features/sharding/principle/
SQL解析=>执行器优化=>SQL路由=>SQL改写=>SQL执行=>结果归
并。
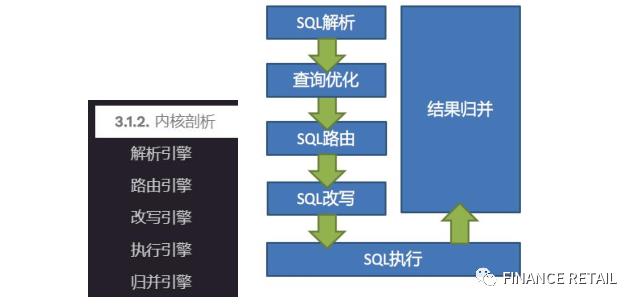
6.1 SQL解析
SQL解析主要是词法和语法的解析。目前常见的SQL解析器主要有fdb,jsqlparser和Druid。Sharding-JDBC1.4.x之前的版本使用Druid作为SQL解析器。从1.5.x版本开始,Sharding-JDBC采用完全自研的SQL解析引擎。
6.2SQL路由
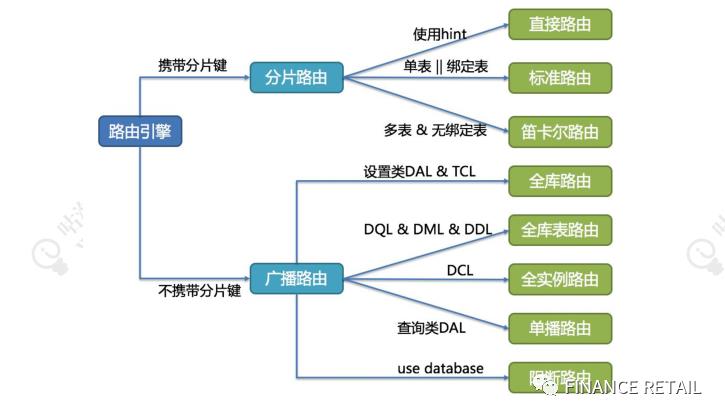
SQL路由是根据分片规则配置以及解析上下文中的分片条件,将SQL定位至真正的数据源。它又分为直接路由、简单路由和笛卡尔积路由。
Binding表是指使用同样的分片键和分片规则的一组表,也就是说任何情况下,Binding表的分片结果应与主表一致。例如:order表和order_item表,都根据order_id分片,结果应是order_1与order_item_1成对出现。这样的关联查询和单表查询复杂度和性能相当。如果分片条件不是等于,而是BETWEEN或IN,则路由结果不一定落入单库表),因此一条逻辑SQL最终可能拆分为多条SQL语句。
笛卡尔积查询最为复杂,因为无法根据Binding关系定位分片规则的一致性,所以非Binding表的关联查询需要拆解为笛卡尔积组合执行。查询性能较低,而且数据库连接数较高,需谨慎使用。
6.3 SQL改写
6.4 SQL执行
因为可能链接到多个真实数据源,Sharding-JDBC将采用多线程并发执行SQL。
6.5 结果归并
7 Sharding-JDBC实现原理
大家还记不记得,我们在Mycat的第一节课说到JDBC的四大核心对象?
DataSource、Connection、Statement(PS)、ResulstSet。
Sharding-JDBC封装了这四个核心类,在类名前面加上了Sharding。
gupao-shard-prop工程。
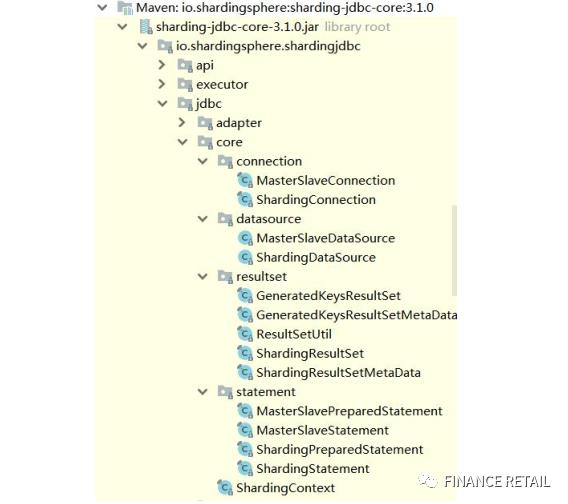
如果说带Sharding的类要替换JDBC的对象,那么一定要找到创建和调用他们的地方。ShardingDataSource我们不说了,系统启动的时候就创建好了。
问题就在于,我们是什么时候用ShardingDataSource获取一个
ShardingConnection的?
我们以整合了MyBatis的项目为例。MyBatis封装了JDBC的核心对象,那么在MyBatis操作JDBC四大对象的时候,就要替换成Sharding-JDBC的四大对象。
没有看过MyBatis源码的同学一定要去看看。我们的查询方法最终会走到SimpleExecutor的doQuery()方法,这个是我们的前提知识,那我们直接在doQuery()打断点。
doQuery()方法里面调用了prepareStatement()创建连接

它经过以下两个方法,返回了一个ShardingConnection。
DataSourceUtil.fetchConnection()
Connectioncon=dataSource.getConnection();
基于这个ShardingConnection,最终得到一个ShardingStatement
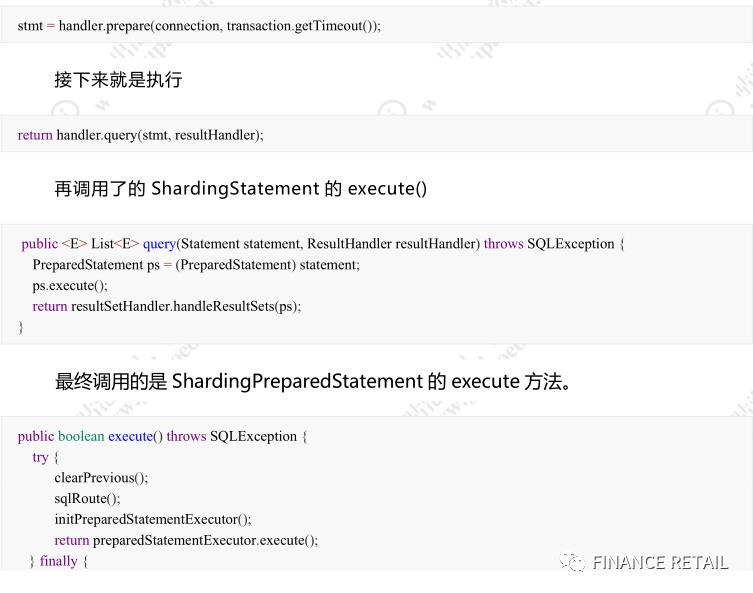
SQL的解析路由就是在这一步完成的。
8 Sharding-Proxy介绍
https://github.com/sharding-sphere/sharding-sphere-doc/raw/master/dist/sharding-proxy-3.0.0.tar.gz
ib目录就是sharding-proxy核心代码,以及依赖的JAR包;
conf目录就是存放所有配置文件,包括sharding-proxy服务的配置文件、数据源以及sharding规则配置文件和项目日志配置文件。
Linux运行start.sh启动(windows用start.bat),默认端口3307
需要的自定义分表算法,只需要将它编译成class文件,然后放到conf目录下,也可以打成jar包放在lib目录下。
9 与Mycat对比
从易用性和功能完善的角度来说,Mycat似乎比Sharding-JDBC要好,因为有现成的分片规则,也提供了4种ID生成方式,通过注解可以支持高级功能,比如跨库关联查询。
建议:小型项目,分片规则简单的项目可以用Sharding-JDBC。大型项目,可以用Mycat。
以上是关于分库分表之Sharding-JDBC的主要内容,如果未能解决你的问题,请参考以下文章
浅谈高性能数据库集群之分库分表
Mysql之分库分表及中间件
分库分表之Mycat实现
架构之数据库分表分库
分库分表之sharding-jdbc
MySQL分库分表之MyCat实现