阿里最新数据库面试题MySQL主从一致性
Posted JavaEdge.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里最新数据库面试题MySQL主从一致性相关的知识,希望对你有一定的参考价值。
为什么备库执行了binlog就可以跟主库保持一致?
mysql主备的基本原理
- 基本的主备切换流程

上部分状态:客户端的读写都直接访问A,B是A的备库,只是将A的更新都同步过来,到本地执行。这样可以保持B和A的数据相同。
当需要切换时,就切成下部分状态:客户端读写访问的都是B,A是B的备库。
上部分状态,虽然节点B没有被直接访问,但推荐把B(备库)设成只读(readonly),考虑如下:
- 有时候一些运营类的查询语句会被放到备库上去查,设置为只读可以防止误操作
- 防止切换逻辑有bug,比如切换过程中出现双写,造成主备不一致
- 可以用readonly状态,来判断节点的角色。
把备库设置成只读了,还能和主库保持同步更新吗?
用于同步更新的线程,拥有超级权限。 readonly设置对超级(super)权限用户无效。
A到B这条线的内部流程是什么样的?下图中画出的就是一个update语句在节点A执行,然后同步到节点B的完整流程图
- 主备流程图
TODO
主库接收到客户端的更新请求后,执行内部事务的更新逻辑,同时写binlog。
备库B跟主库A之间维持了一个长连接。主库A内部有一个线程,专门用于服务备库B的这个长连接。一个事务日志同步的过程:
- 在备库B通过change master命令,设置主库A的IP、端口、用户名、密码,以及要从哪个位置开始请求binlog,这个位置包含文件名和日志偏移量
- 在备库B上执行start slave命令,这时备库会启动io_thread、sql_thread。io_thread负责与主库建立连接
- 主库A校验完用户名、密码后,开始按照备库B传过来的位置,从本地读取binlog,发给B
- 备库B拿到binlog后,写到本地文件,称为中转日志(relay log)
- sql_thread读取中转日志,解析出日志里的命令,并执行
后来由于多线程复制方案的引入,sql_thread演化成为了多个线程。
binlog里到底是什么
为什么备库拿过去可以直接执行。
- 创建个表并初始化数据
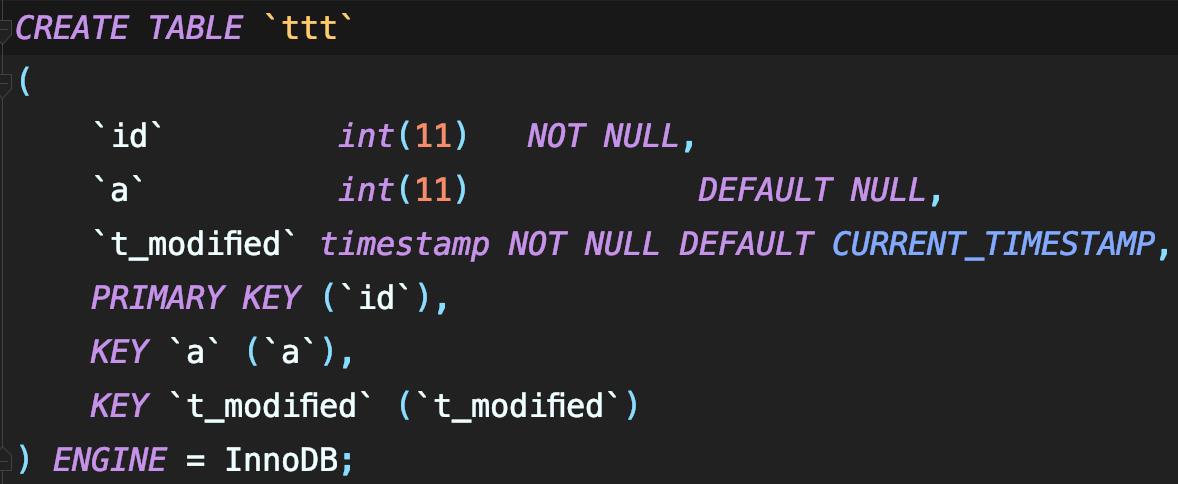
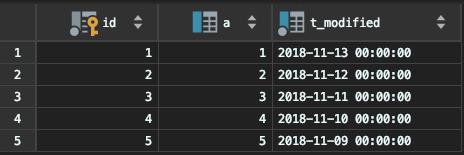
要在表中删除一行,这个delete语句的binlog是怎么记录的。
注意,下面这个语句包含注释,如果你用MySQL客户端来做这个实验的话,要记得加-c参数,否则客户端会自动去掉注释。
delete
from ttt -c /*comment*/
where a >= 4
and t_modified <= '2018-11-10'
limit 1;
当binlog_format=statement时,binlog里面记录的就是SQL语句的原文。你可以用
- 查看binlog内容,上面是 ROW 格式,下面是 statement 格式。
mysql> show binlog events in 'binlog.000034';
+---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------------------------------+
| binlog.000034 | 786 | Anonymous_Gtid | 1 | 865 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| binlog.000034 | 865 | Query | 1 | 977 | BEGIN |
| binlog.000034 | 977 | Query | 1 | 1151 | use `common_mistakes`; delete from ttt where a >= 4 and t_modified <= '2018-11-10' limit 1 |
| binlog.000034 | 1151 | Query | 1 | 1264 | COMMIT |
+---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------------------------------+
16 rows in set (0.00 sec)
- BEGIN和最后的COMMIT匹配,表示中间是个事务
- 第三行就是真实执行的语句。在真实执行的delete命令之前,还有一个use命令。这条命令是MySQL根据当前要操作的表所在的数据库而自行添加的。这么做,可以保证日志传到备库去执行时,不论当前工作线程在哪个库,都能够正确更新到common_mistakes库的ttt表。
- 后面的delete 语句,就是SQL原语句
- 最后一行是一个COMMIT写着xid。
当前binlog设置的是statement格式,并且语句中有limit,该命令可能是unsafe的。因为delete 带limit,可能出现主备数据不一致。比如上面这个例子:
- 若delete使用的是索引a,则会根据索引a找到第一个满足条件的行,即删除的是a=4这一行
- 但若使用的是索引t_modified,则删除的就是
t_modified='2018-11-09',即a=5这行
由于statement格式下,记录到binlog里的是原语句,可能发生:在主库执行该SQL时,用的是索引a;而在备库执行该SQL时,却使用索引t_modified。因此,这样写是有风险的。
若把binlog改为ROW 格式,是不是就没这问题了?
- row格式binlog
mysql> show binlog events in 'binlog.000034';
+---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------------------------------+
| binlog.000034 | 156 | Anonymous_Gtid | 1 | 235 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| binlog.000034 | 235 | Query | 1 | 329 | BEGIN |
| binlog.000034 | 329 | Table_map | 1 | 392 | table_id: 102 (common_mistakes.ttt) |
| binlog.000034 | 392 | Delete_rows | 1 | 440 | table_id: 102 flags: STMT_END_F |
| binlog.000034 | 440 | Xid | 1 | 471 | COMMIT /* xid=71 */
BEGIN和COMMIT是一样的。但row格式的binlog里没有原SQL语句,而两个event:
- Table_map event
说明接下来要操作的表是test库的表t - Delete_rows event
定义删除的行为
其实还需要借助mysqlbinlog工具,用下面的命令解析和查看binlog内容。因为图5中的信息显示,这个事务的binlog是从8900这个位置开始的,所以可以用start-position参数来指定从这个位置的日志开始解析。
/usr/local/Cellar/mysql/8.0.21_1/bin/mysqlbinlog
-vv /usr/local/var/mysql/binlog.000034
--start-position=156;
row格式binlog 示例的详细信息
BEGIN
/*!*/;
# at 329
#210606 14:11:44 server id 1 end_log_pos 392 CRC32 0xe8d79800 Table_map: `common_mistakes`.`ttt` mapped to number 102
# at 392
#210606 14:11:44 server id 1 end_log_pos 440 CRC32 0x8b3b43d1 Delete_rows: table id 102 flags: STMT_END_F
BINLOG '
IGe8YBMBAAAAPwAAAIgBAAAAAGYAAAAAAAEAD2NvbW1vbl9taXN0YWtlcwADdHR0AAMDAxEBAAIB
AQAAmNfo
IGe8YCABAAAAMAAAALgBAAAAAGYAAAAAAAEAAgAD/wAEAAAABAAAAFvlrwDRQzuL
'/*!*/;
### DELETE FROM `common_mistakes`.`ttt`
### WHERE
### @1=4 /* INT meta=0 nullable=0 is_null=0 */
### @2=4 /* INT meta=0 nullable=1 is_null=0 */
### @3=1541779200 /* TIMESTAMP(0) meta=0 nullable=0 is_null=0 */
# at 440
#210606 14:11:44 server id 1 end_log_pos 471 CRC32 0x8e0dab1d Xid = 71
COMMIT/*!*/;
- server id 1
该事务在server_id=1的库上执行 - 每个event都有CRC32值,因为binlog_checksum是CRC32
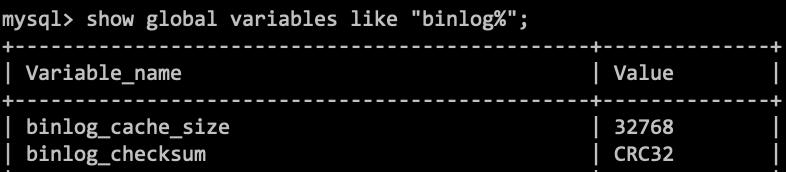
- Table_map event
显示了接下来要打开的表,map到数字226。现在我们这条SQL语句只操作了一张表,若操作多表呢?每个表都有一个对应的Table_map event、都会map到一个单独的数字,用于区分对不同表的操作。 - -vv参数是为了把内容都解析出来,所以从结果里面可以看到各个字段的值(比如,@1=4、 @2=4这些值)
- binlog_row_image
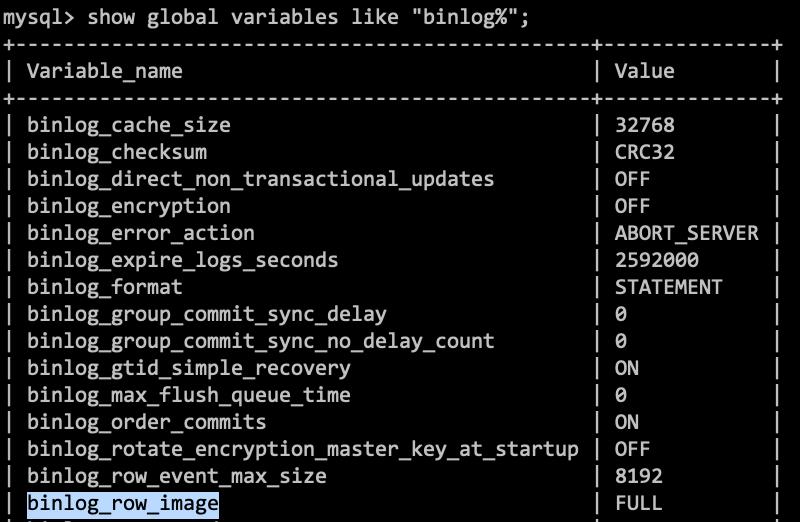
默认配置是FULL,因此Delete_event里面,包含了删掉的行的所有字段的值。若把binlog_row_image设置为MINIMAL,则只会记录必要的信息。在该例,就只会记录id=4。 - Xid event
表示事务被正确提交了。
可见,当binlog_format=row,binlog记录了真实删除行的主键id,这样binlog传到备库时,就肯定会删除id=4的行,不会有主备删除不同行的问题。
为何binlog有mixed格式?
因为有些statement格式的binlog可能会导致主备不一致,所以要使用row格式。
但row很占空间(不然怎么叫肉呢?)。比如你用一个delete语句删掉10万行:
- statement就是一个SQL语句被记录到binlog,占用几十个字节
- row就要把这10万条记录都写到binlog。不仅占用巨大空间,写binlog也要耗费I/O资源,影响执行速度。
所以,MySQL采取折中方案-mixed:MySQL自己会判断该SQL是否可能引起主备不一致:
- 有可能,用row
- 不可能,用statement
即mixed既可以利用statment格式的优点,又能避免数据不一致。
比如我们的例子,设为mixed后:
- 就会记录为row
- 若执行的语句没有limit 1,就记录为statement
现在越来越多的场景要求把MySQL的binlog格式设成row。这么做的理由有很多,比如恢复数据。
数据恢复的重要性
- 即使执行delete,row格式binlog也会保存被删掉的行的整行信息。所以,若你在执行完一条delete后,发现删错数据了,可以直接把binlog中记录的delete转insert,把错删数据插回。
- 若执行错insert呢?row下,insert的binlog里会记录所有字段信息,可以用来定位被插入的那行。再直接把insert转delete 即可。
- 若执行update,binlog会记录修改前整行的数据和修改后的整行数据。所以只需把这个event前后两行信息对调,在DB里执行
虽然mixed格式的binlog现在已经用得不多了,但这里还是要再借用一下mixed格式来说明一个问题,来看一下这条SQL语句:
insert into ttt values(10,10, now());
若binlog设为mixed,MySQL会把它记录为啥格式呢?

MySQL采用statement格式。若该binlog过了1min才传给备库,那主备数据不就不一致了?
再用mysqlbinlog查看:
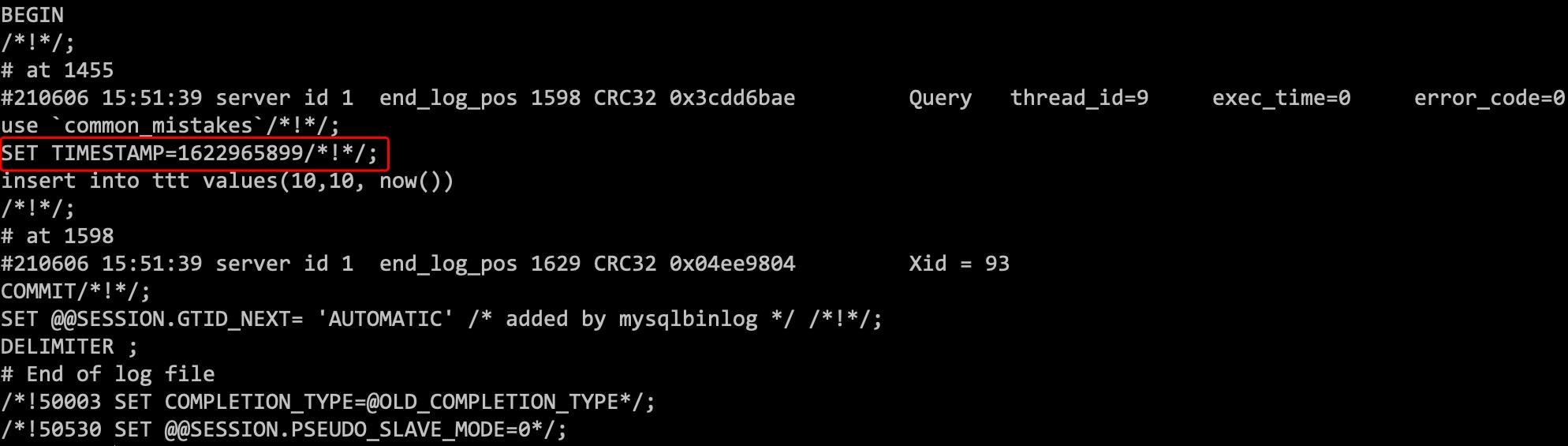
binlog在记录event时,多记了一条命令:SET TIMESTAMP。它用 SET TIMESTAMP命令约定了接下来的now()函数的返回时间。
因此,无论该binlog多久后被备库执行或用于恢复该库的备份,该insert插入的行,值都固定。即通过SET TIMESTAMP,MySQL保证了主备数据一致性。
有人重放binlog时,是这么做的:
- 用mysqlbinlog解析出日志
- 然后把里面的statement语句直接拷贝出来执行
这样有风险。因为有些语句的执行结果依赖于上下文命令,直接执行很可能错误。
使用binlog恢复数据的正确做法:
- 用 mysqlbinlog工具解析出来
- 然后把解析结果整个发给MySQL执行。类似下面的命令:
mysqlbinlog master.000001 --start-position=2738 --stop-position=2973 | mysql -h127.0.0.1 -P13000 -u$user -p$pwd;
将 master.000001 文件里面从第2738字节到第2973字节中间这段内容解析出来,放到MySQL去执行。
循环复制问题
binlog确保了在备库执行相同的binlog,可以得到与主库相同的状态。
因此,可以认为正常情况下主备数据是一致的。即文章一开始的图中A、B两个节点的内容是一致的。不过那是M-S结构,实际生产上使用比较多的是双M结构:
- MySQL主备切换流程–双M结构
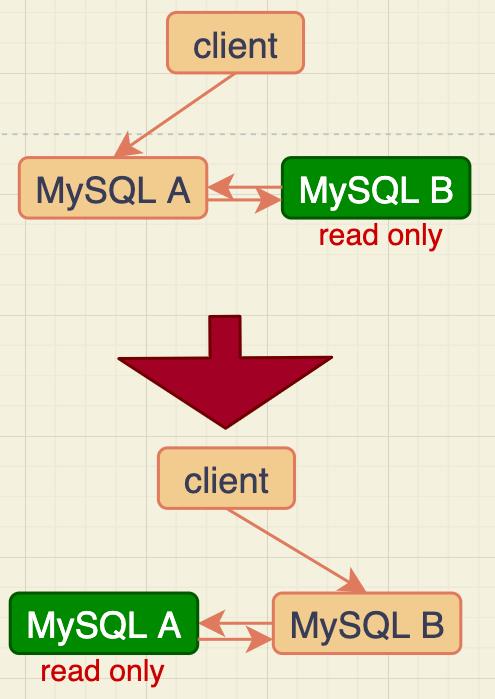
区别只是多了一条线,即:节点A和B之间总是互为主备关系。这样在切换的时候就不用再修改主备关系。
但是,双M结构还有一个问题需要解决:业务逻辑在节点A上更新了一条语句,然后再把生成的binlog 发给节点B,节点B执行完这条更新语句后也会生成binlog。(推荐把参数log_slave_updates设置为on,表示备库执行relay log后生成binlog)。
那么,若节点A同时是节点B的备库,相当于又把节点B新生成的binlog拿过来执行了一次,然后节点A和B间,会不断地循环执行这个更新语句,也就是循环复制了。这怎么解决?
我们已经知道,MySQL在binlog中记录了这个命令第一次执行时所在实例的server id。因此,可以用下面的逻辑解决两个节点间的循环复制的问题:
- 规定两个库的server id必须不同,如果相同,则它们之间不能设定为主备关系
- 一个备库接到binlog并在重放的过程中,生成与原binlog的server id相同的新的binlog
- 每个库在收到从自己的主库发过来的日志后,先判断server id,如果跟自己的相同,表示这个日志是自己生成的,就直接丢弃这个日志
按照这个逻辑,如果我们设置了双M结构,日志的执行流就会变成这样:
4. 从节点A更新的事务,binlog里面记的都是A的server id
5. 传到节点B执行一次以后,节点B生成的binlog 的server id也是A的server id
6. 再传回给节点A,A判断到这个server id与自己的相同,就不会再处理这个日志。所以,死循环在这里就断掉了
binlog在MySQL高可用方案很重要,是所有MySQL高可用方案,诸如多节点、半同步、MySQL group replication等的基础。
以上是关于阿里最新数据库面试题MySQL主从一致性的主要内容,如果未能解决你的问题,请参考以下文章