SparseArray 源码分析
Posted 不会写代码的丝丽
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SparseArray 源码分析相关的知识,希望对你有一定的参考价值。
SparceArray效率对比
我们使用HashMap来进行对比,我们这里使用androiX下面的SparceArray版本对象。
实现代码:
val hashMap = java.util.HashMap<Int, String>(num)
var time = measureTimeMillis {
for (i in 0..num) {
//请勿直接使用i插入,否则一定能够是sparseArray更快,顺序插入在实际生活很少不具备实验性
hashMap[Random.nextInt()] = ""
}
}
Log.e( "FMY", "运行时间: hashmap ${time} 内存 ${Runtime.getRuntime().totalMemory()}");
var sparseArray = SparseArrayCompat<String>(10)
var time = measureTimeMillis {
for (i in 0..num) {
//请勿直接使用i插入,否则一定能够是sparseArray更快,顺序插入在实际生活很少不具备实验性
sparseArray.put(Random.nextInt(), "")
}
}
Log.e( "FMY","运行时间: sparseArray: ${time} 内存 ${Runtime.getRuntime().totalMemory()}");
我们设置val num = 100000;然后运行上面两段代码
输出:
运行时间: sparseArray: 2693 内存 3811581
运行时间: hashmap 98 内存 9711854
hashmap运行效率非常快,但是内存占用几乎是sparseArray两倍。
我们把变量缩小val num = 10000;再次运行
运行时间: sparseArray: 49 内存 3150014
运行时间: hashmap 6 内存 3330456
现在你还觉得SparseArray真的使用来代替HashMap的吗?这里我只是觉得有些博主文章写的太过于偏激,凡事皆有利弊。
个人建议
100000以上的数据量使用HashMap,而以下使用SparseArray
与HashMap效率对象
- 内存方向
HashMap每个节点都是Map.Entry<K,V>对象,也就是每个节点都要多出这个一个对象额外存储。SparseArray采用了两个数组,一个直接存储key另一个存储value且不用类封装
- 运行时效
HashMap对于非冲突节点查找效率为O(1),而对于冲突节点的效率为O(n)SparseArray采用了二分查找的逻辑完成,所以为O(logn)
SparseArray源码分析
Sparse是稀疏的意思,加上Array就是稀疏数组的翻译.但是SparseArray并没有采用我们常见的稀疏数组的实现方式,但是也同样也提高了数组内存使用率。
关于常见的稀疏数组请看稀疏数组.
但是Google的工程师用了其他巧妙的方式也实现高效的内存使用.
算法思想:
假设当前数组长度为n,数组为num
(1) 插入第一个元素i1.一定插入数组的第0个位置,也就是num[0]
(2) 插入第二个元素i2.假设i2大于i1,那么一定会插入i1的后面也就是num[1]
(3) 插入第三个元素i3.假设i3大于i1但是i3小于i2,那么一定会插入i1的后面以及i2的前面,那么此时移动i2到num[2],最后插入i3到num[1]
我们这里来画几个图来表示SparseArray插入:
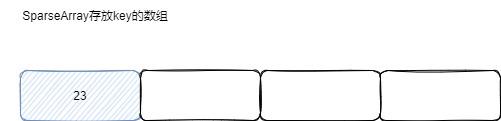
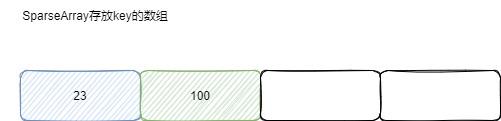
我们插入的顺序是: [23 ,100 ,0]
插入23
插入100
插入0
此时需要移动数组元素
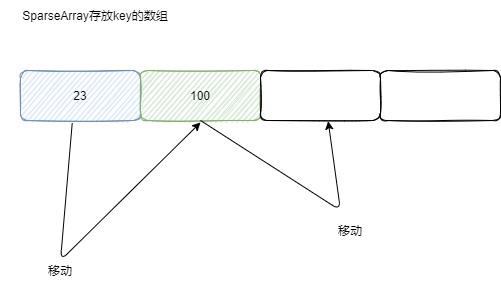
最后执行插入0

也就是说当SparseArray执行插入操作的时候如果是非顺序的插入那么有可能引起插入的缓慢。
但是如果你是顺序插入的你的效率将极高
我们做出以下的实验方便大家大家理解
val hashMap = java.util.HashMap<Int, String>(num)
var time = measureTimeMillis {
for (i in 0..num) {
//i是递增的所以是顺序插入
hashMap[i] = ""
}
}
Log.e( "FMY", "运行时间: hashmap ${time} 内存 ${Runtime.getRuntime().totalMemory()}");
var sparseArray = SparseArrayCompat<String>(10)
var time = measureTimeMillis {
for (i in 0..num) {
//i是递增的所以是顺序插入
sparseArray.put(i, "")
}
}
Log.e( "FMY","运行时间: sparseArray: ${time} 内存 ${Runtime.getRuntime().totalMemory()}");
我们执行val num = 100000;后输出:
运行时间: sparseArray: 38 内存 3843040
运行时间: hashmap 58 内存 8815567
当你的数据一定升序插入的可以只考虑使用sparseArray。
理解上面的知识后我们开始进行正式的源码分析:
我们首先查看一个比较难懂的函数binarySearch
//如果能在array中查找到value那么久返回对应的下标(大于0)。
//如果array中没有查找到value那么返回应该插入下标的位取反结果,位取反一定小于0.再次取反可以得到正数
//size表示当前array数组里面到底有多少个存储的数据
static int binarySearch(int[] array, int size, int value) {
int lo = 0;
int hi = size - 1;
//在数组中进行二分查找,注意末端是size-1哦,也就是只在已经有的数据范围内查找
while (lo <= hi) {
int mid = (lo + hi) >>> 1;
int midVal = array[mid];
if (midVal < value) {
lo = mid + 1;
} else if (midVal > value) {
hi = mid - 1;
} else {
return mid; // value found
}
}
//取反后小于0,让上层知道没有查找到value的下标,不过你再次取反可以得到应该插入的位置
return ~lo; // value not present
}
我们这里举几个例子
//数组
int[] arr = new int[5];
//存储实际的数据大小
int size = 0;
//在数组中查找 1插入位置,这里由于数组没有插入过1
//所以i一定小于0,并且~i可以得到正确的插入位置
int i = binarySearch(arr, size, 1);
//这里i=-1 ~i=0 ,所以1应该插入下标为0
System.out.println("i = " + i + " ~i = " + ~i);
//插入元素
if (i<0) {
//i<0表示当前数组中没有1这个元素
//~i 取反得到位置
arr[~i] = 1;
//标记数据量
size++;
}
//再次搜索1,因为已经存在1,所以返回的i为0
i = binarySearch(arr, size, 1);
System.out.println("i = " + i + " ~i = " + ~i);
//我们寻找插入-2的位置
//由于-2不存在数组中所以 i一定小于0 且~i等于插入的位置。这里当然会插入0号位置
i = binarySearch(arr, size, -2);
//i = -1 ~i = 0
System.out.println("i = " + i + " ~i = " + ~i);
//我们寻找插入3的位置
//由于3不存在数组中所以 i一定小于0 且~i等于插入的位置。
// 这里当然会插入到【1】这个元素的后面也就是下标为1
i = binarySearch(arr, size, 3);
//i = -2 ~i = 1
System.out.println("i = " + i + " ~i = " + ~i);
现在我们从SparseArray构造函数开始
public class SparseArrayCompat<E> implements Cloneable {
//专门存放key的数组,且是升序排序且是紧凑的放在一起
private int[] mKeys;
//和mkeys对应的数据 mKeys[i]和mValues[i]对应
private Object[] mValues;
//现在数据的长度
private int mSize;
public SparseArrayCompat(int initialCapacity) {
//初始化数组的长度
if (initialCapacity == 0) {
mKeys = ContainerHelpers.EMPTY_INTS;
mValues = ContainerHelpers.EMPTY_OBJECTS;
} else {
//内部会判断数组容量是否合适,不合适会返回一个新的大小
initialCapacity = ContainerHelpers.idealIntArraySize(initialCapacity);
mKeys = new int[initialCapacity];
mValues = new Object[initialCapacity];
}
}
}
我们看下插入代码
public class SparseArrayCompat<E> implements Cloneable {
public void put(int key, E value) {
//寻找当前元素的key下标
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
//大于0表示已经存在,直接替换value即可
if (i >= 0) {
mValues[i] = value;
} else {
//小于0当前数据不存在数组中,取反得到这个数据应该放入的下标
i = ~i;
//这个位置被标记为已经被删除DELETED那么直接使用即可
if (i < mSize && mValues[i] == DELETED) {
mKeys[i] = key;
mValues[i] = value;
return;
}
//这里判断需要整理数组,(比如删除被标记为DELETED然后移动数组)
//这里代码我们首先不需要管,
if (mGarbage && mSize >= mKeys.length) {
gc();
// Search again because indices may have changed.
i = ~ ContainerHelpers.binarySearch(mKeys, mSize, key);
}
//当前需要扩容了不然放不了新元素
//扩容代码比较简单这里可以先不看
if (mSize >= mKeys.length) {
int n = ContainerHelpers.idealIntArraySize(mSize + 1);
int[] nkeys = new int[n];
Object[] nvalues = new Object[n];
// Log.e("SparseArray", "grow " + mKeys.length + " to " + n);
System.arraycopy(mKeys, 0, nkeys, 0, mKeys.length);
System.arraycopy(mValues, 0, nvalues, 0, mValues.length);
mKeys = nkeys;
mValues = nvalues;
}
//移动数组中i+1后元素,让i位置空出来放入新元素
if (mSize - i != 0) {
// Log.e("SparseArray", "move " + (mSize - i));
System.arraycopy(mKeys, i, mKeys, i + 1, mSize - i);
System.arraycopy(mValues, i, mValues, i + 1, mSize - i);
}
//将数据放入指定位置
mKeys[i] = key;
mValues[i] = value;
mSize++;
}
}
}
上面的插入代码比较简单,获取元素也是类似这里就不在贴出,我们看下删除代码:
public void remove(int key) {
//寻找被删除的位置
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
//如果大于0存在被删除的元素
if (i >= 0) {
//把当前位置标记为DELETED
if (mValues[i] != DELETED) {
mValues[i] = DELETED;
//标记下次需要整理下数组
mGarbage = true;
}
}
}
删除元素时候并不会里面进行数组移动操作,而是标记,这样可以启动优化作用(如果下一个插入元素正好放在这里)
以上是关于SparseArray 源码分析的主要内容,如果未能解决你的问题,请参考以下文章