MyCat入门篇幅-介绍
Posted 程序猿集锦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MyCat入门篇幅-介绍相关的知识,希望对你有一定的参考价值。
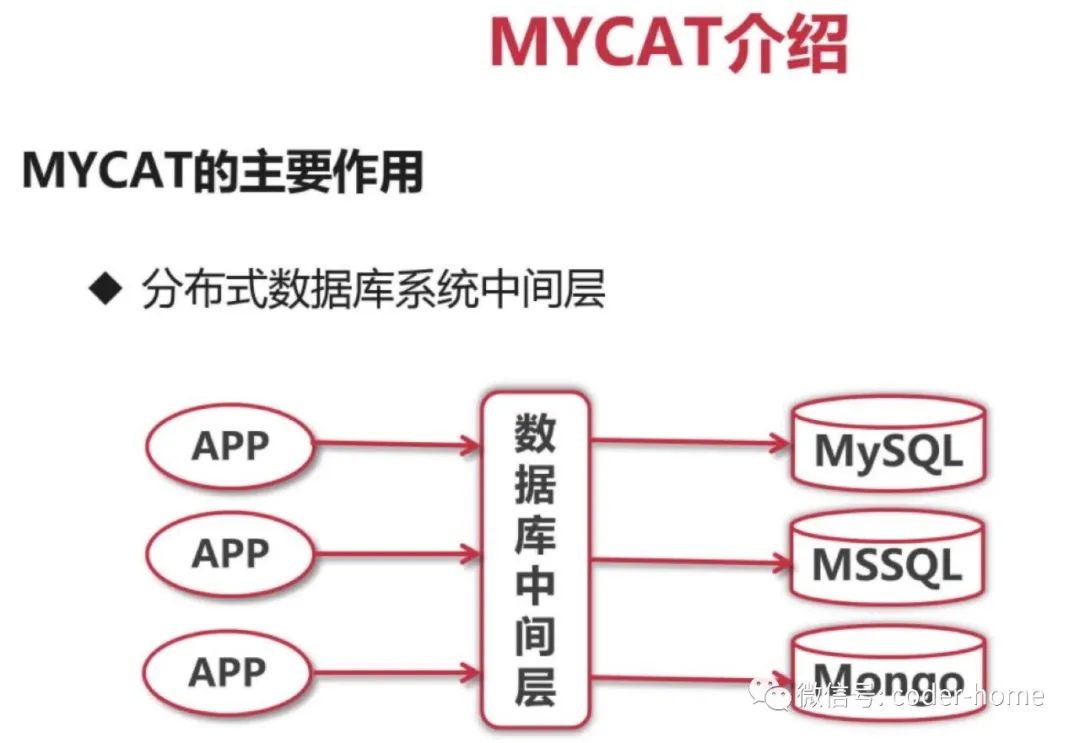
MyCat是什么?这个概念可大可小,作为使用者,我的理解是这样的:MyCat是一款开源的数据库中间件
什么是中间件?中间件是什么东西?可以理解为在两个东西中间起到衔接协调作用的这么一个东西。在软件架构中的位置,位于应用和数据库之间的一个应用软件
比如我们的软件前面有页面展现层,也就是我们平时所说的前端。前端后面的是处理前端发起的请求的后端。那么,后端再往后是什么?那就是存储我们的所有请求数据的数据库了。
而我们今天讨论的MyCat数据库中间件,就是在后端应用和数据库中间起到衔接协调转发作用的这么一个插件。
它除了可以连接各种关系数据库(mysql、Oracle、SQLsever)之外,还能连接各种非关系型数据库
发展历史
阿里巴巴可以说是MyCat的爸爸,没有阿里巴巴就没有MyCat。MyCat是经过下面的过慢慢演变而来的:
Amoeba(2008)->Cobar(2012)->MyCat(2013)-MyCat2.0(2020)
2008阿里使用MySQL去Oracle的时候用来放在应用和MySQL中间层的一个插件。
2012年,由于阿里的业务增长,Amoeba不足以支撑,推出了Cobar。
2013年,MyCat出现。
2020年,目前已经出现2.0版本。
功能介绍
既然MyCat是一个数据库中间件,那么这个数据库中间件它有哪些使用场景呢,什么情况下我才需要时候用MyCat呢?MyCat具体的时候用场景如下:
读写分离
垂直拆分
水平拆分
多租户场景
负载均衡
数据库连接池
涉及到以上场景的时候,可以考虑使用数据库中间件mycat来解决。注意: 包括但不仅限于上述场景,我这里只拿自己遇到的场景举例说明一下。
读写分离
对于向上述的一主一从的MySQL架构,mycat支持把写请求都转发到master主节点上,把读请求都转发到slave从节点上,进行sql过滤,进而达到读写分离的目的。
而对于一些一主多从的MySQL架构,mycat还支持把读请求均匀的分发到多个slave从节点上,从而达到对数据库读负载均衡的效果。
与此同时,如果多个从节点中的某个从节点挂掉了,那么mycat也会停止向这个从节点分发读请求,不会出现有些读请求返回异常错误,这也是mycat支持MySQL集群高可用的一种体现。

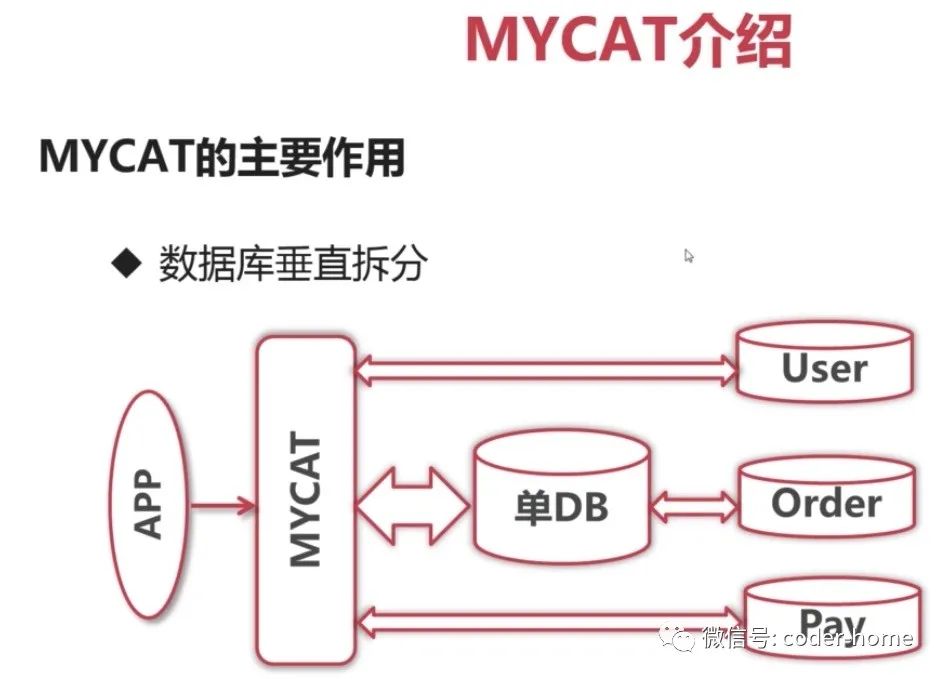
垂直拆分
垂直拆分是指:把业务中涉及到的所有的表,按照功能模块划分,将表分别创建在不同的MySQL数据库服务器上,避免所有的业务表全部放在一台MySQL数据库服务器上,通过增加MySQL数据库实例的数,来分担来自业务层模块的数据请求压力,从而达到对降低MySQL数据库的压力。
例如:
把用户模块相关的表,都创建在M1节点上,所有和用户相关的业务流量全部都去访问M1数据库实例。
把订单模块相关的表,都创建在M2节点上,所有和订单相关的业务流量全部都去访问M2数据库实例。
把支付模块相关的表,都创建在M3节点上,所有和支付相关的业务流量全部都去访问M3数据库实例。
这样就避免了所有的业务模块:用户、订单、支付各个模块全部都去访问一个数据库节点,分摊自业务模块对数据库的请求,降低了服务器的压力,提高了访问的性能和效率。
而上述的这样的拆分,如果没有mycat在中间做分流转发,那么这些对数据库的请求逻辑都要在业务代码层来实现才可以达到不用的业务模块去访问去访问不同的数据库。在业务代码中就会维护多个数据源,这样对业务代码来说就有侵入性。
而有了mycat中间件之后,它在业务代码和数据库中间起到衔接、转发、路由的功能,就把业务代码和数据库的关系进行了解耦。使得业务代码更灵活,以后即便是数据库变为其他的数据库,业务代码也不需要做更改。只要在mycat层做配置既可。
水平拆分
水平拆分是指:把业务中涉及到的一张或多张数据量特别大的表,按照一定的拆分规则,均匀的分布到不同的数据库服务器分开来存储,在各个数据服务器上,都有这样的一张数据表,表结构在各个数据库服务器上完全相同,只是各个数据库服务器上面的表中存储的数据行数和每一行的数据内容不同。需要把所有的数据库服务器上面的表中的数据合并在一起才是一个完整的表数据。
这样就把一个特别大的表,水平拆分到不同的数据库服务器上,来分担一个数据库服务器的压力。提高数据库的性能和效率。
例如:一个订单表数据量特别大,达到了千万级别以上。比如1000万的数据。MySQL单表的数据量超过千万级别之后,就有查询性能瓶颈问题了。
所以对于这样的一张大表,建议拆分到不同的数据库服务器上面分别存储一部分数据行。
现在把这个大的订单表,分摊到两个MySQL数据服务器上,每个MySQL数据库服务器上只存储500万行的数据,分摊的规则按照自增主键的奇偶数原则分别放在M1和M2两个数据库服务器上。
主键是奇数的行订单都放在M1上面的订单表中
主键是偶数的行订单都放在M2上面的订单表中。
这个时候把M1和M2上面的订单数据合并在一起才是完整的订单数据。
但是上面的这样的方式,因为当我们要插入一条数据到时候,我们要明确是该插入到M1上还是M2上,当我们查询的时候,我们要知道是去M1上查询我们要的数据还是去M2上去查询我们要的数据。所以代码中要有这样的逻辑,对业务代码来说也是有侵入性的。而有了mycat之后,mycat会根据配置规则,自动路由到对应的节点上去做插入和查询的操作。然后把合并后的结果发送给业务层,降低了业务层和数据库层的耦合度。
mycat的介绍就告一段落了,相信这篇文章之后,你应该对mycat有一个整体的印象。
后面我会继续分析mycat的安装部署的相关内容。关注我,不迷路。
以上是关于MyCat入门篇幅-介绍的主要内容,如果未能解决你的问题,请参考以下文章