Flink SQL 自定义 redis connector
Posted JasonLee-后厂村程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink SQL 自定义 redis connector相关的知识,希望对你有一定的参考价值。
一般情况下,我们不需要创建新的 connector,因为 Flink SQL 已经内置了丰富的 connector 供我们使用,但是在实际生产环境中我们的存储是多种多样的,所以原生的 connector 并不能满足所有用户的需求,这个时候就需要我们自定义 connector,这篇文章的重点就是介绍一下如何实现自定义 Flink SQL connector ?
先来看一下官网的一张 connector 架构图:
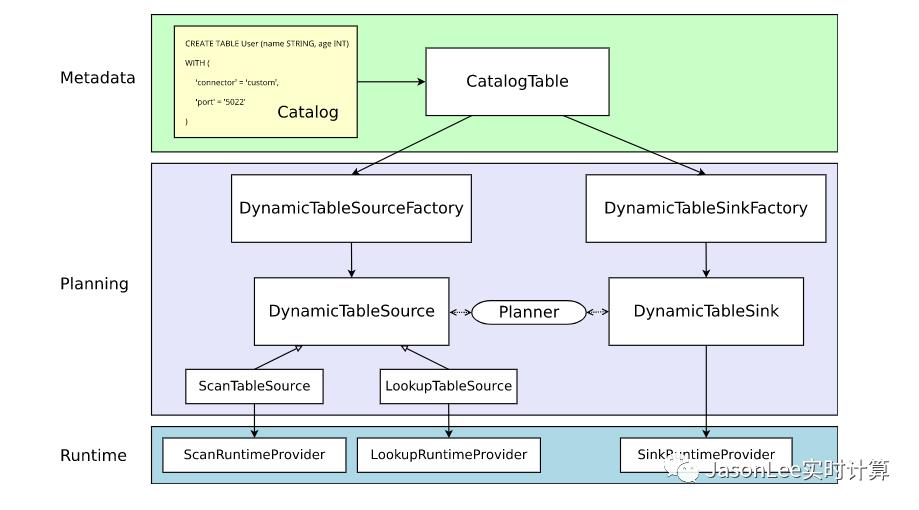
Metadata
Table API 和 SQL 都是声明式 API。这包括表的声明。因此,执行 CREATE TABLE 语句会导致目标目录中的元数据更新。对于大多数目录实现,不会为此类操作修改外部系统中的物理数据。特定于连接器的依赖项不必出现在类路径中。WITH 子句中声明的选项既不经过验证也不以其他方式解释。动态表的元数据(通过 DDL 创建或由目录提供)表示为 CatalogTable 的实例。必要时,表名将在内部解析为 CatalogTable。
Planning
在规划和优化表程序时,需要将 CatalogTable 解析为 DynamicTableSource(用于在 SELECT 查询中读取)和 DynamicTableSink(用于在 INSERT INTO 语句中写入)。
DynamicTableSourceFactory 和 DynamicTableSinkFactory 提供特定于连接器的逻辑,用于将 CatalogTable 的元数据转换为 DynamicTableSource 和 DynamicTableSink 的实例。在大多数情况下,工厂的目的是验证选项(例如示例中的 'port' = '5022')、配置编码/解码格式(如果需要)以及创建表连接器的参数化实例。
默认情况下,使用 Java 的服务提供者接口 (SPI) 发现 DynamicTableSourceFactory 和 DynamicTableSinkFactory 的实例。连接器选项(例如示例中的 'connector' = 'custom')必须对应于有效的工厂标识符。
尽管在类命名中可能不明显,但 DynamicTableSource 和 DynamicTableSink 也可以被视为有状态的工厂,它们最终为读取/写入实际数据生成具体的运行时实现。
规划器使用源和接收器实例来执行特定于连接器的双向通信,直到找到最佳逻辑计划。根据可选声明的能力接口(例如 SupportsProjectionPushDown 或 SupportsOverwrite),规划器可能会对实例应用更改,从而改变生成的运行时实现。
Runtime
一旦逻辑规划完成,规划器将从表连接器获取运行时实现。运行时逻辑在 Flink 的核心连接器接口中实现,例如 InputFormat 或 SourceFunction。
这些接口按另一个抽象级别分组为 ScanRuntimeProvider、LookupRuntimeProvider 和 SinkRuntimeProvider 的子类。
例如,OutputFormatProvider(提供 org.apache.flink.api.common.io.OutputFormat)和 SinkFunctionProvider(提供 org.apache.flink.streaming.api.functions.sink.SinkFunction)都是 SinkRuntimeProvider 的具体实例,规划器可以 处理。
自定义 redis sink connector
大概需要下面 4 个过程:
自定义 Factory,根据需要实现 DynamicTableSourceFactory, DynamicTableSinkFactory.
自定义 TableSink, 实现 DynamicTableSink
定义 Options 也就是 connector 相关的属性
在 resource 下面添加配置文件 org.apache.flink.table.factories.Factory 里面添加 Factory 的全限定名
Factory
package flink.connector.redis;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.table.connector.sink.DynamicTableSink;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.factories.DynamicTableSinkFactory;
import org.apache.flink.table.factories.DynamicTableSourceFactory;
import org.apache.flink.table.factories.FactoryUtil;
import java.util.HashSet;
import java.util.Set;
/**
* 自定义 Factory
**/
public class RedisDynamicTableFactory implements DynamicTableSourceFactory, DynamicTableSinkFactory {
@Override
public DynamicTableSink createDynamicTableSink(Context context) {
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
helper.validate();
ReadableConfig options = helper.getOptions();
return new RedisDynamicTableSink(options);
}
/**
* 这里没有实现 source
* @param context
* @return
*/
@Override
public DynamicTableSource createDynamicTableSource(Context context) {
return null;
}
@Override
public String factoryIdentifier() {
return "redis";
}
@Override
public Set<ConfigOption<?>> requiredOptions() {
final Set<ConfigOption<?>> options = new HashSet();
options.add(RedisOptions.HOST);
options.add(RedisOptions.PORT);
return options;
}
@Override
public Set<ConfigOption<?>> optionalOptions() {
final Set<ConfigOption<?>> options = new HashSet();
options.add(RedisOptions.EXPIRE);
return options;
}
}
TableSink
package flink.connector.redis;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.table.connector.ChangelogMode;
import org.apache.flink.table.connector.sink.DynamicTableSink;
import org.apache.flink.table.connector.sink.SinkFunctionProvider;
import org.apache.flink.types.RowKind;
import static flink.connector.redis.RedisOptions.*;
/**
* 自定义 DynamicTableSink
**/
public class RedisDynamicTableSink implements DynamicTableSink {
private ReadableConfig options;
public RedisDynamicTableSink(ReadableConfig options) {
this.options = options;
}
@Override
public ChangelogMode getChangelogMode(ChangelogMode requestedMode) {
return ChangelogMode.newBuilder()
.addContainedKind(RowKind.INSERT)
.addContainedKind(RowKind.UPDATE_BEFORE)
.addContainedKind(RowKind.UPDATE_AFTER)
.build();
}
@Override
public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
// 获取 redis 的 host 和 port
String host = options.getOptional(HOST).get();
Integer port = options.getOptional(PORT).get();
Integer expire = options.getOptional(EXPIRE).get();
MyRedisSink myRedisSink = new MyRedisSink(host, port, expire);
return SinkFunctionProvider.of(myRedisSink);
}
@Override
public DynamicTableSink copy() {
return new RedisDynamicTableSink(this.options);
}
@Override
public String asSummaryString() {
return "redis table sink";
}
}
package flink.connector.redis;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.flink.table.data.RowData;
import redis.clients.jedis.Jedis;
/**
* 自定义 sink 写入 redis
**/
public class MyRedisSink extends RichSinkFunction<RowData> {
private final String host;
private final int port;
private int expire;
private Jedis jedis;
public MyRedisSink(String host, int port, int expire) {
this.host = host;
this.port = port;
this.expire = expire;
}
@Override
public void open(Configuration parameters) throws Exception {
this.jedis = new Jedis(host, port);
}
@Override
public void invoke(RowData value, Context context) throws Exception {
this.jedis.set(String.valueOf(value.getString(0)), String.valueOf(value.getInt(1)), "NX", "EX", expire);
}
@Override
public void close() throws Exception {
this.jedis.close();
}
}
这里用的是 Jedis 没有使用 Flink 自带的 redis connector ,因为 Flink 自带的功能有限,很多功能都需要自己扩展,所以就直接使用 Jedis.我这里只是为了演示,只实现了最简单的 set 功能.
Options
package flink.connector.redis;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ConfigOptions;
/**
* Option utils for redis table source sink.
*/
public class RedisOptions {
private RedisOptions() {}
public static final ConfigOption<String> HOST =
ConfigOptions.key("host")
.stringType()
.noDefaultValue()
.withDescription(
"The Redis table host.");
public static final ConfigOption<Integer> PORT =
ConfigOptions.key("port")
.intType()
.defaultValue(6379)
.withDescription(
"The Redis table port.");
public static final ConfigOption<Integer> EXPIRE =
ConfigOptions.key("expire")
.intType()
.noDefaultValue()
.withDescription(
"The Redis table expire time.");
}
所有 redis 相关的属性都可以在这里添加,比如用户名密码,连接池相关的配置等.
配置文件

最后也是最重要的一点就是在 resource 下面添加配置文件,因为 Flink 是通过 SPI 机制来发现工厂的,如果有不了解 SPI 机制的可以看前面这篇文章,注意这个路径一定不要写错.
到这里基本就完成了,下面来测试一下自定义的 connector 能否把数据准确的写入到 redis 里面.
使用&测试
// 定义数据源表
tEnv.executeSql("""
|CREATE TABLE datagen (
| f_sequence INT,
| f_random INT,
| f_random_str STRING,
| ts AS localtimestamp,
| WATERMARK FOR ts AS ts
|) WITH (
| 'connector' = 'datagen',
| -- optional options --
| 'rows-per-second'='1',
| 'fields.f_sequence.kind'='sequence',
| 'fields.f_sequence.start'='1',
| 'fields.f_sequence.end'='20',
| 'fields.f_random.min'='1',
| 'fields.f_random.max'='1000',
| 'fields.f_random_str.length'='10'
|)
|""".stripMargin)
// 定义 redis 表
tEnv.executeSql(
"""
|create table redis_sink (
|f1 STRING,
|f2 INT
|) WITH (
|'connector' = 'redis',
|'host' = 'xxx',
|'port' = '6379',
|'expire' = '100'
|)
|""".stripMargin)
// 执行插入 SQL
tEnv.executeSql(
"""
|insert into redis_sink
|select f_random_str,f_random
|from datagen
|""".stripMargin)
上面的 datagen 会产生 20 条数据.执行上面的 SQL 然后查询一下 redis 打印的数据如下:
68652c3a52 : 396
de3044d6d0 : 248
b09690ec10 : 436
dab4bb9ea9 : 821
d57a47d883 : 134
4d3d23767a : 63
9ca712a25f : 527
cb3019326d : 164
4a4af63f89 : 803
3cb960dbf1 : 575
db95bf7590 : 500
4274665b4b : 910
5c27396cb1 : 993
c1d957a2c8 : 951
8b24d7abe2 : 66
817b59d742 : 354
baa51bb58a : 14
db32f9cd53 : 510
3c5db2220b : 44
7c169eaef9 : 160
通过上面的 Demo,相信大家对自定义 Flink SQL connector 已经有所了解,那在生产环境中就可以根据自己的需求去定制各种 connector 了.
推荐阅读
Flink 1.11.x WatermarkStrategy 不兼容问题
如果你觉得文章对你有帮助,麻烦点一下赞和在看吧,你的支持是我创作的最大动力.
以上是关于Flink SQL 自定义 redis connector的主要内容,如果未能解决你的问题,请参考以下文章