python如何提取网页信息?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python如何提取网页信息?相关的知识,希望对你有一定的参考价值。
比如tianqi.2345.com/air-53698.htm
想要每小时自动提取
PM2.5
PM10
二氧化硫
二氧化氮
一氧化碳
臭氧
的数值,python要怎么编写呢?
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents) 参考技术B #不用第三方模块
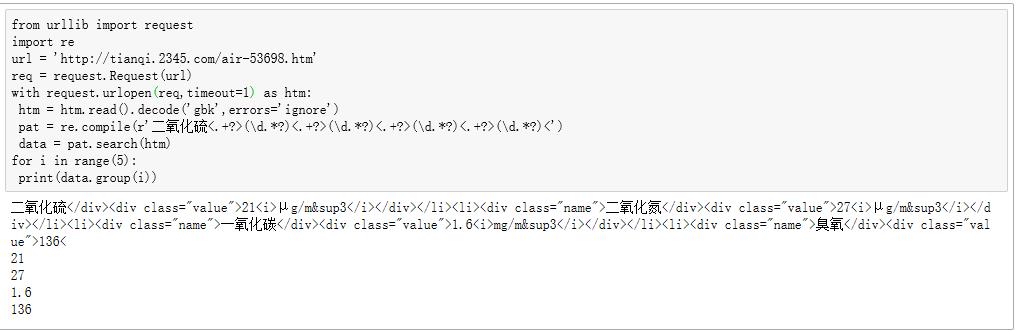
from urllib import request
import re
url = '' # 你的网址
req = request.Request(url)
with request.urlopen(req,timeout=60) as htm:
htm = htm.read().decode('gbk',errors='ignore')
pat = re.compile(r'二氧化硫<.+?>(\d.*?)<.+?>(\d.*?)<.+?>(\d.*?)<.+?>(\d.*?)<')
data = pat.search(htm)
for i in range(5):
print(data.group(i)) # 第 0 个是整体匹配字符串,1-4才是所要的数字追问
您好,使用了如上的代码,还是有很多不需要的内容显示。
能否告知下去掉的方法呢?

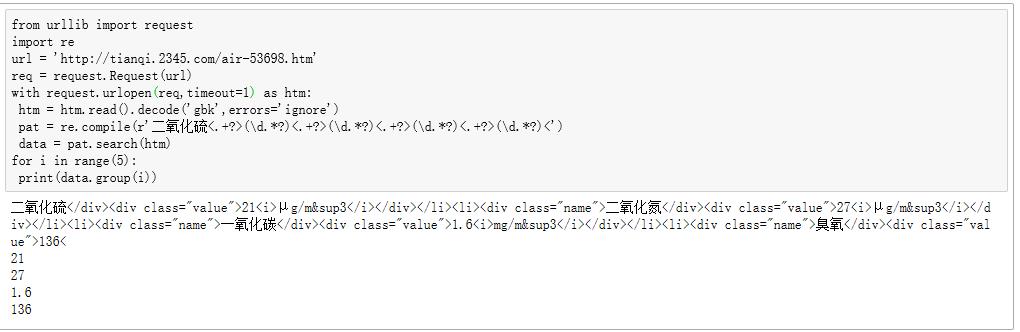
我代码里不是说了吗:
print(data.group(i)) # 第 0 个是整体匹配字符串,1-4才是所要的数字
你当然可以这样:
for i in range(1,5):
print(data.group(i))
这不就成了,嘿嘿
或者:
res = []
for i in range(1,5):
res.append(data.group(i)) # 结果是字符型数字
#es.append(float(data.group(i))) #将字符串转为float型数值
您好,已经用筛选出了下列内容,只显示指定内容的正则表达式编写方法能否告知一下……谢谢
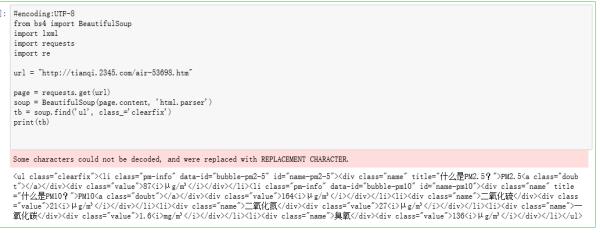
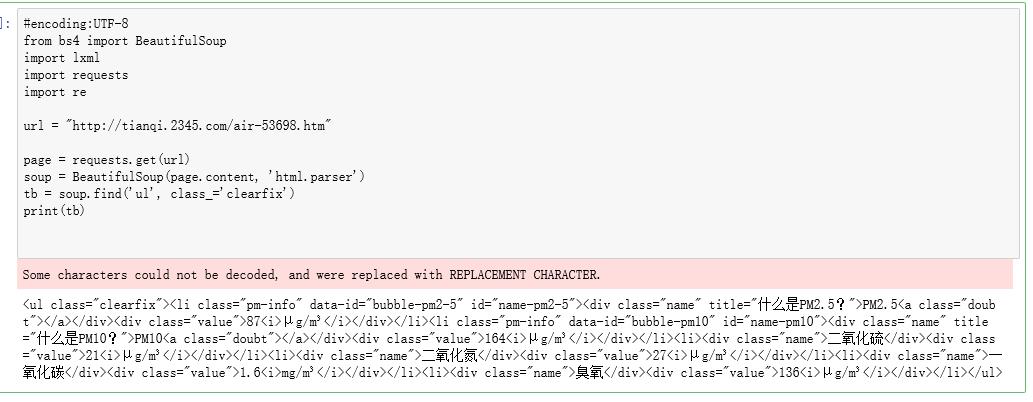
你这个是表格,最好网上找一些库来解析,比如beautifulsoup4啥的,自己查下
你这个是表格,最好网上找一些库来解析,比如beautifulsoup4啥的,自己查下
参考技术D 看源代码就可以了如何利用python爬取网页内容
参考技术A利用python爬取网页内容需要用scrapy(爬虫框架),但是很简单,就三步
定义item类
开发spider类
开发pipeline
想学习更深的爬虫,可以用《疯狂python讲义》
以上是关于python如何提取网页信息?的主要内容,如果未能解决你的问题,请参考以下文章