Scrapy爬虫 爬取豆瓣TOP250
Posted xingweikun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy爬虫 爬取豆瓣TOP250相关的知识,希望对你有一定的参考价值。
使用Scrapy爬虫框架爬取豆瓣电影TOP250
分析网页
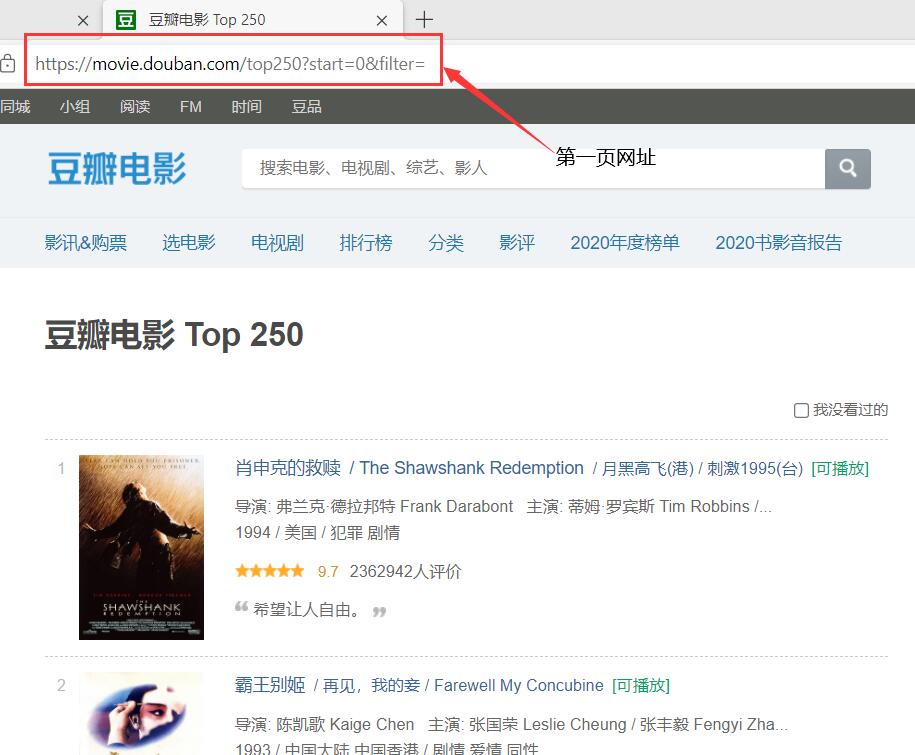
第一页
start=0
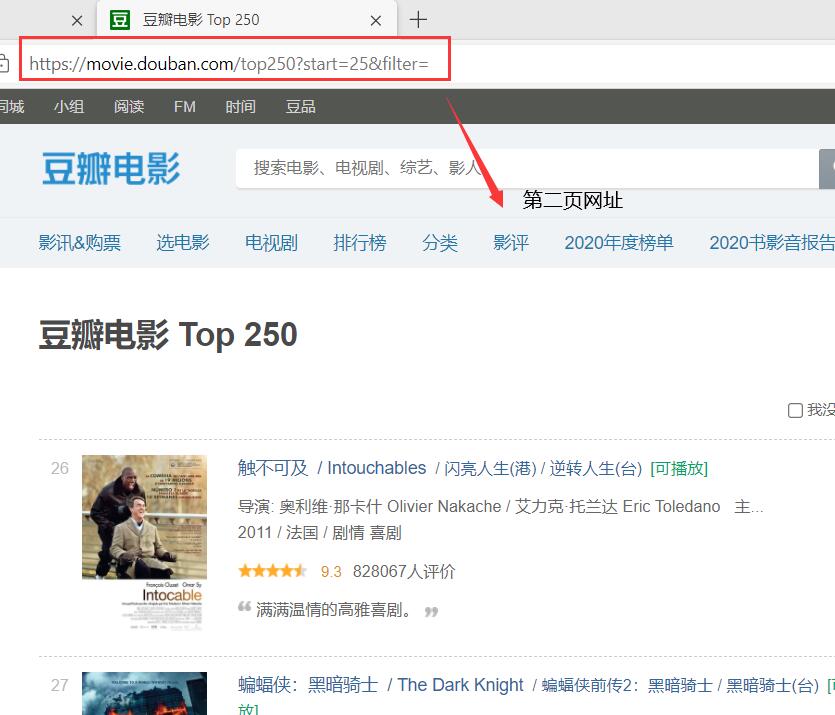
第二页
start=25
最后一页
start=225
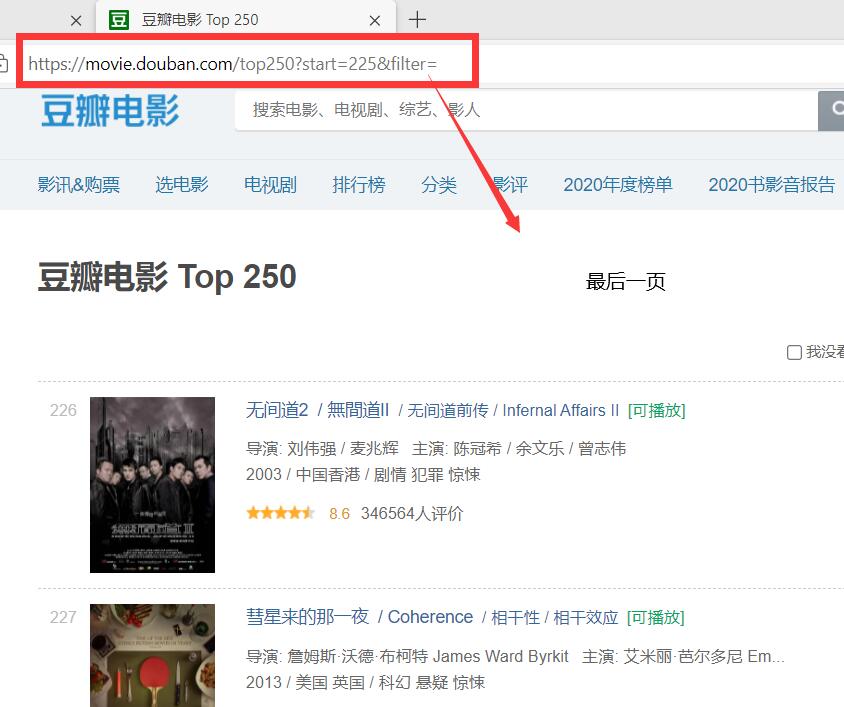
可以看出网页的网址是有规律的
创建Scrapy爬虫框架
C:\\Users\\dell>cd Desktop\\python_test\\
C:\\Users\\dell\\Desktop\\python_test>scrapy startproject dbmovie
C:\\Users\\dell\\Desktop\\python_test>cd dbmovie\\dbmovie
C:\\Users\\dell\\Desktop\\python_test\\dbmovie\\dbmovie>scrapy genspider dbmovie_spider movie.douban.com
修改spider脚本
import scrapy
from dbmovie.items import DoubanItem
class DbmovieSpiderSpider(scrapy.Spider):
name = 'dbmovie_spider'
allowed_domains = ['movie.douban.com/top250']
list=[]
for page in range(0,226,25):
url='start='+str(page)+'&filter='
start_urls='https://movie.douban.com/top250?'+url
list.append(start_urls)
start_urls = list
def parse(self, response):
item=DoubanItem()
movies=response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
item['ranking']=movie.xpath('.//div[@class="star"]/span[4]/text()').extract()[0]
item['movie_name']=movie.xpath('.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score']=movie.xpath('.//div[@class="star"]/span[@class="rating_num"]/text()').extract()[0]
item['describe']=movie.xpath('.//span[@class="inq"]/text()').extract()
yield item
修改items脚本
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 评论人数
ranking=scrapy.Field()
# 电影名称
movie_name=scrapy.Field()
# 评分
score=scrapy.Field()
# 电影描述
describe=scrapy.Field()
修改settings脚本
修改内容
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36'
}
FEED_URL="douban.csv"
FEED_FORMAT='csv'
FEED_EXPORT_ENCODING="gbk"
运行
在命令行输入
# 指定保存文件名或目录
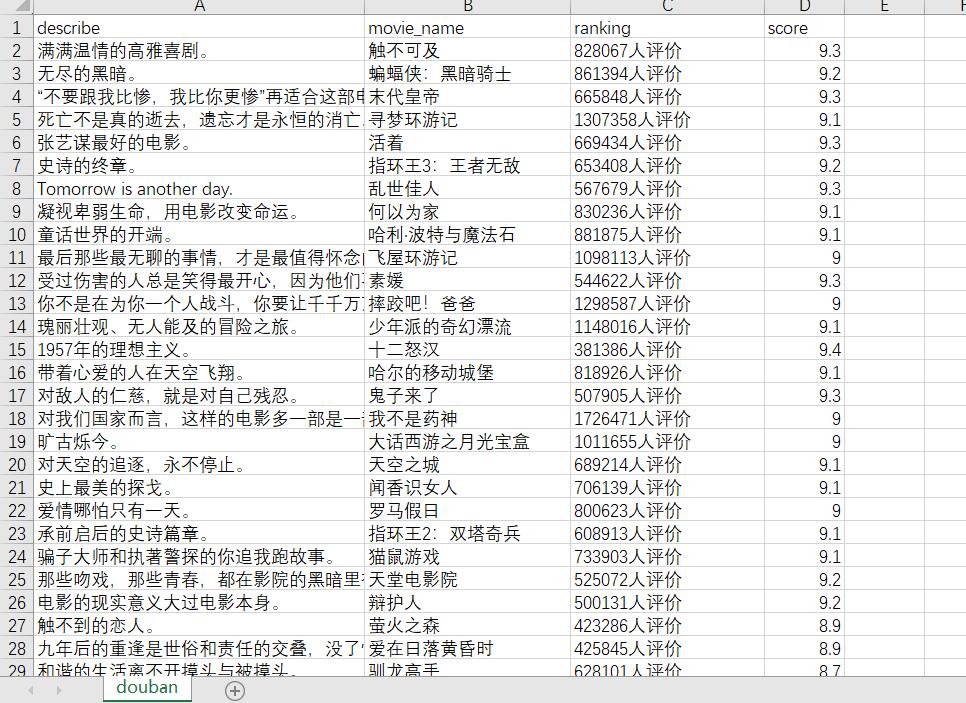
scrapy crawl dbmovie_spider -o douban.csv
可以看到爬取结果并不是按照顺序排列的
大家可以尝试如何爬取带顺序的结果
以上是关于Scrapy爬虫 爬取豆瓣TOP250的主要内容,如果未能解决你的问题,请参考以下文章