值得收藏你想知道的并发都在这里传统并发与Go并发
Posted 小生凡一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了值得收藏你想知道的并发都在这里传统并发与Go并发相关的知识,希望对你有一定的参考价值。
并发操作总结
参考书籍及网站
《计算机操作系统原理分析(第二版)》
《Go程序设计语言》
《Go并发编程实战》
https://medium.com/rungo/anatomy-of-channels-in-go-concurrency-in-go-1ec336086adb
由于本人能力有限,
如果本文有地方错误或是表达不清楚,欢迎在评论区评论或是私信我!
我们一起交流,一起进步!
Coding Change World!
(一). 基础知识

1. 知识储备
1.1 并发主要思想
使多个任务可以在同一时间段内执行以便能够得到结果。
1.2 并发概念
在多道程序涉及环境下,处理器在开始执行一道程序的第一条指令后,在这道程序完成之前,处理器可以开始执行下一道程序,同样地,更多其他的程序也可以开始运行。
也就是说,处理器在执行一道程序的两条指令之间,可以执行其他程序的指令。
1.3 进程
1.3.1 定义
一道程序在一个数据集上的一次执行过程,称为进程
为了实现并发执行,分析、解决并发执行中出现的问题,操作系统引入了一个概念,即进程,来深入揭示程序的运行规律和动态变化。
1.3.2 特征
-
动态性:每个进程都有一个生命周期,具有一个从创建、运行到消亡的过程。进程是动态的,而程序是静态的。程序可以以纸质或电子存储介质等形式存在,如果程序员没有修改,程序还可以长期保存;进程是程序在处理器上的运行过程,是动态变化的,具有从产生到消亡的过程。
从进程的动态性又可分为以下几个部分:- 运行状态 :处理器当前执行的指令正是该进程对应的程序代码,进程正占用CPU运行,或是说CPU分配给进程。
- 就绪状态 :对于当前不再运行状态的进程,如果把CPU分配给它,他就可以立即运行。
- 阻塞状态 :对于当前不在运行状态的一个进程,即使把处理器分配给它,他也不能运行。
-
并发性:多个程序可以并发执行。一个进程被创建后,在他消亡之前,其他的进程也可以被创建。这样,宏观上有多个进程同时在运行中,但是对于单处理器,任意时刻只能运行一个进程的程序代码。
-
独立性:进程是操作系统分配资源的基本单位,一个进程的程序和数据只能由该进程本身访问,进程地址空间是私有的。
-
结构性:操作系统经过概括、抽象后,定义了一个相对固定的格式即数据结构,用于表示一个进程,这个数据结构就是进程控制块PCB。
-
异步性:多个进程并发执行时,每一个进程的运行过程不可预知,因此,它何时完成也无法准确预知,这就要求操作系统必须做到,在一个程序运行完成之前,随时可以创建一个或更多新的进程,这就是进程的异步性。
1.4 线程
1.4.1 定义
把进程细化为若干个可以独立运行的实体,每一个实体称为一个线程。
1.4.2 特征
- 实现进程内部的并发执行,提高并行程度。
- 减少处理器切换的开销
- 简化进程通信通信
(二). 基于内存共享的并发(传统并发)
这种并发就是我们在计算机操作系统中学习到的并发,也是传统的并发。
2. 制约关系
并发进程的制约关系分为间接制约和直接制约,分别对应进程互斥关系和同步关系。
进程同步是对进程并发执行的协调,通过进程同步机制保证程序的可再现性。
2.1 间接制约与互斥关系
简介
两个或是多个进程共享一种资源时,当一个进程在访问或使用该资源时,制约其他进程的访问或使用,否则,就可能造成执行结果的错误。
把并发进程之间的这种制约关系称为间接制约关系,也就是进程通过第三方即共享的资源,暂时限制其他进程的运行,间接制约关系时由资源共享引起的。
流程
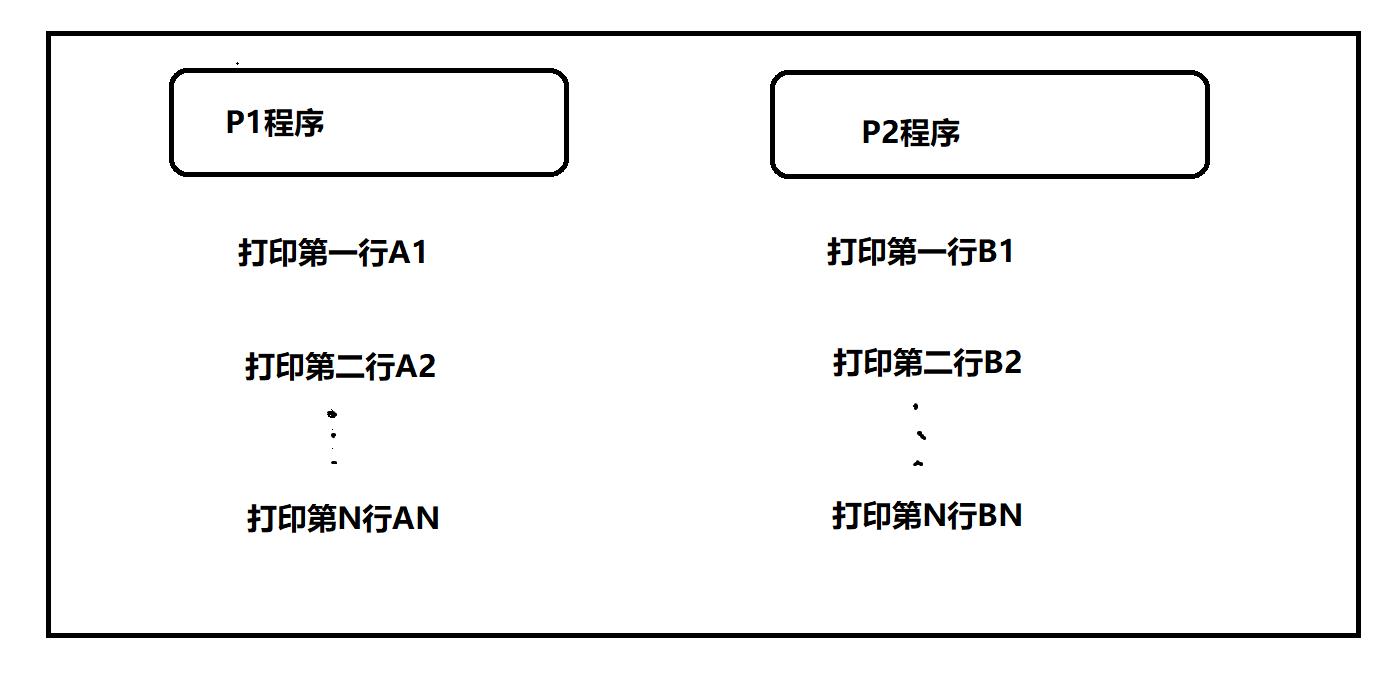
- 临界资源与间接制约
一次只能让一个进程使用的资源称为临界资源。
常见的临界资源有打印机,存储单元,堆栈等。
间接制约关系就是一组并发进程在共享某种临界资源时存在的一种制约关系。
如下图所示
- 临界区与互斥关系
临界区是指进程对应的程序中访问临界资源的一段代码。
- 称一个进程要进入临界区,是指该进程已经执行临界区的第一条指令/语句;
- 称一个进程离开或退出临界区,是指该进程已经执行了临界区的最后一条指令/语句;
- 称一个进程在临界区内执行,是指该进程已经开始执行临界区的第一条指令但还没有离开这个临界区。
操作系统对一组进程的间接制约关系的控制,转为实现这组进程的互斥关系。
2.2 直接制约与同步关系
简介
直接制约关系则时由任务协作引起的。几个进程共同协作完成一项任务,因任务性质的要求,这些进程的执行顺序由严格的固定,只有按实现规定的顺序依次执行,任务才能得到正确的处理,否则,就可能造成错误结果。把并发进程之间的这种制约关系称为直接制约关系,也就是一个进程的执行状况直接决定了另一个或几个进程可否执行。
流程
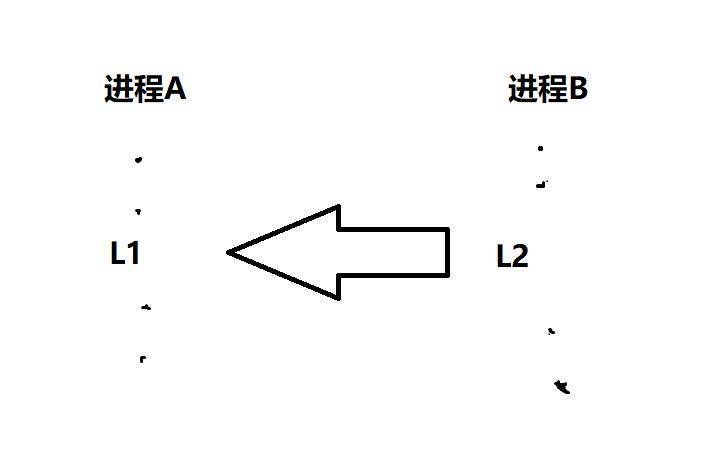
- 单向依赖关系
对于进程A和B,如果处理器在执行过程A中某条指令之前,要求先执行进程B的一条指令;在进程B指定的指令没有执行之前,进程A的对应指令不能执行,这时称进程A依赖于进程B。
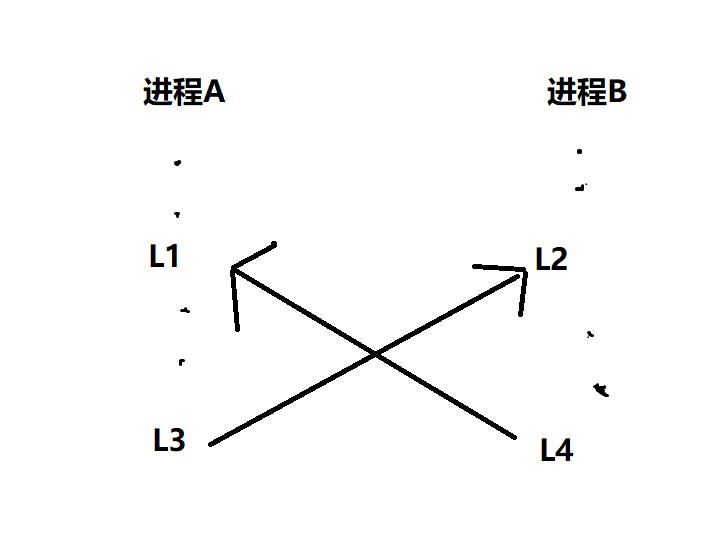
- 相互依赖关系
如果进程A依赖于进程B,同时进程B也依赖于进程A,则称A和B具有相互依赖关系。
- 同步关系
在一组并发进程中,如果每个进程至少同组中另一个进程存在单向或相互依赖关系,则称这组进程具有同步关系,简称同步进程。
3.同步机制
3.1 互斥关系与加锁机制
3.1.1 临界区管理准则
- 空闲让进:在一个进程要求进入临界区执行时,如果进程在相关临界区内执行,则允许其进入临界区运行。
- 忙则等待:当有一个进程在临界区内执行时,要求进入相关临界区执行的其他任何进程都要等待。
- 有限等待:对于要求进入临界区执行的进程,之多经过有限时间的等待之后,应有机会进入临界区执行,不能让其进行无期限等待下去。是为了系统的公平性,也为了防止饥饿。
- 让权等待:当进程离开临界区时,即在临界区内执行的进程在执行完临界区的最后一条指令后,应把处理器让给下一个进程执行。让权等待与进程调度密切相关。
3.1.2 加锁机制原理
- 锁变量key
对于一组相关临界区定义的第一个变量称为锁变量,锁变量取值0和1
并规定key=0时,锁时开着的,临界资源当前时空的,此时允许进程进入对应的临界区执行;
key=1表示对应的锁时关的,临界资源当前是忙的状态,此时禁止进程进入对应的临界区。
- 加锁操作
检查进程是否可以进入临界区执行。在临界区的第一条指令之前,加入一个枷锁的奥做,以实现进程要进入临界区执行时的检查。
lock(key){
while(key==1); //循环测试语句
key=1; //设置语句
}
只有得到锁的进程才允许进入临界区执行,没有得到锁的进程要等待。
3. 解锁操作
unlock(key){
key = 0
}
3.1.3 加锁例子
加锁的控制方法
初始变量 key = 0;
...
lock (key);
临界区
unlock(key);
...
进程PA()与进程PB()
PA(){
int x;
lock(key);
x = count;
x = x + 1;
count = x;
unlock(key);
}
PB(){
int y;
lock(key);
y = count;
y = y - 1;
count = y;
unlock(key)
}
1.由于一开始的key=0,所以在PA的lock的循环中,PA的key = 1,获得了锁,进入临界区。
2.如果处理器要去处理B的操作,则会因为PB中的lock中的循环一直在转,所以一直在阻塞,无法执行后续的步骤。
3. 只有当PA的key释放之后,使得B获得了锁才能进入临界区。
所以在单单这种加锁的条件下是不能实现互斥关系的。
需要借助硬件操作,以x86为例子,利用汇编指令xchg实现lock(key)
tsl :
mov ax,1
xchg ax,key
cmp ax,o
jne tsl
//对于多处理器系统,通常提供指令前缀lock,利用指令前缀lock封锁总线实现指令的执行的互斥。
tsl:
mov ax,1
lock xchg ax,key
cmp ax,0
jne tsl
3.1.4 加锁机制分析
- 普通的加锁机制不能实现互斥关系,借助硬件的加锁机制可以实现进程的互斥关系。
- 存在“忙等待”的状况,浪费处理器时间。当一个B进程等待的时候,A进程完成之后,处理器可能会调用C进程,D进程,不执行B进程,因为并发的随机性,所以B可能永远都无法执行。
- 存在“饥饿”现象。忙等待的状况的不断出现会造饥饿现象,或是饿死现象,可见加锁机制不满足临界区管理准则。
- 多个锁变量的加锁操作可能造成进程死锁。
3.2 互斥关系与信号量机制
信号量机制不仅可以实现进程互斥关系,还可以实现进程的同步关系
3.2.1 信号量机制原理
- 信号量
一种信号量对应一个整形变量value,一个等待队列bq,同时还可以对应其他的控制信息。
struct semaphore{
int value; //信号量的整形变量
PCB *bp; //信号量对应的等待队列
}
- p操作
s是一个信号量
p(s){
s.value = s.value - 1;
if(s.value<0) {
blocked(s);
//这个是阻塞原语,把当前调用p(s)操作的进程设置为阻塞状态并加入到信号量s对应的等待队列bq中
}
}
- v操作
s是一个信号量
v(s){
s.value = s.value + 1;
if(s.value <= 0) {
wakeup(s);
// 这里的wakeup(s)是唤醒原语,从信号量s对应的等待队列bq中唤醒一个进程,也就是按照一定策略从等待队列bq中选择一个进程,将其转化就绪状态。
}
}
p、v操作也是一个原语操作。
3.2.2 信号量分析
- 当s.value>=1时,进程调用p(s)操作后,不会造成进程阻塞。
- 当s.value<=0时,进程调用p(s)操作后,会造成进程阻塞,系统会把处理器分配给下一个进程运行,而不像加锁机制中的“忙等待”,阻塞进程就会被加入到等待队列中,当执行当前进程后,再通过一定的算法(先进先出,先进后出等等),从等待队列中选出执行的进程。激活进程。
3.2.3 实现例子及分析
定义一个信号量s,初始值为 1
信号量的控制描述如下
...
p(s);
临界区;
v(s);
...
改进上述加锁机制中的PA() PB()操作
PA(){
int x;
p(s);
x = count;
x = x + 1;
count = x;
v(s);
}
PB(){
int y;
p(s);
y = count;
y = y - 1;
count = y;
v(s);
}
- 处理器再执行PA()进程的进程的时候,会执行p(s)操作,由于s.value = 1,所以执行完之后,s.value=0,是不会阻塞的。
- 此时如果处理器要处理PB()操作,由于s.value = 0 所以执行完之后,s.value<0,将B进程阻塞,并将B进程放入等待队列bq中。
- 当处理器处理完A的操作的时候,就会在等待队列中唤醒一个程序,是否下一个程序是B就看是什么算法了。
4. 例题
4.1 读写操作模型
第一题
实现Read、Move、Write并发执行
semaphore s1 = 1,s2 = 0 , s3 =1 ,s4 = 0;
Read(){
从原磁盘读取一个文件;
p(s1); //执行从文件读到buff1的操作
文件数据存入缓冲区buff1
v(s2); //激活读取buff1的操作,使得进入就绪状态
}
Move(){
p(s2); //执行从buff1中读取文件的操作
从缓冲区buff1取文件数据
v(s1); //执行完了从文件读到buff1的读操作
p(s3); //执行从buff1读取的文件写入buff2的写操作
将文件数据存入buff2中
v(s4); //激活从buff2写入磁盘的写操作
}
Write(){
p(s4); //执行从buff2写入磁盘的写操作
把buff2中的数据存入目标磁盘的文件中;
v(s3); //执行完从buff1读取的文件写入buff2的写操作
}
main(){
cobegin
{
repeat Read();
repeat Move();
repeat Write();
}
}
4.2 PC问题
第二题
实现生产者/消费者模型(PC问题)
semaphore mutex = 1, empty = k , full = 0;
Producer(){
生产一个物品
p(empty)
p(mutex);
物品存入缓冲区buf[]的某个单元格
v(mutex);
p(full);
}
Consumer(){
p(full);
p(mutex);
从缓冲区buf[]的某个单元格取物品
v(mutex);
v(empty);
消费
}
只有生产者生产出,消费者才能进行消费,不然消费者会处于阻塞状态。
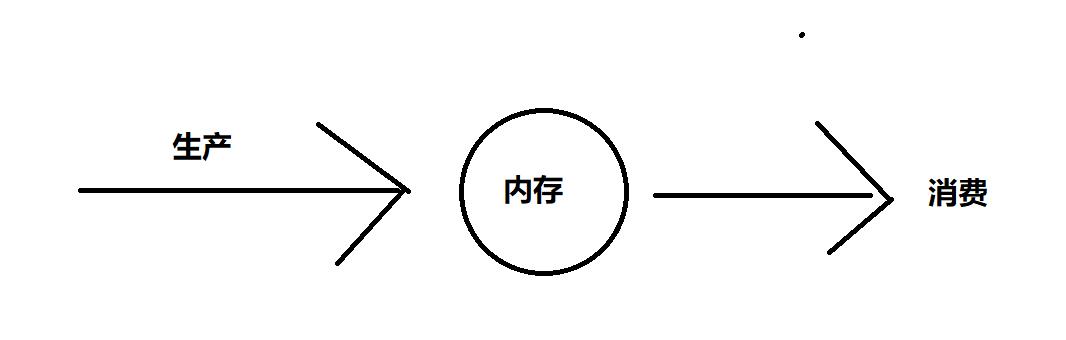
(三). 基于通道通信的并发
在go社区有这样一句话
不要通过共享内存来通信,而是通过通信来共享内存。
go官方是建议使用管道通信的方式来进行并发。
通道 是用于协程间交流的通信载体。严格地来说,通道就是数据传输的管道,数据通过这根管道被 “传入” 或被 “读出”。 因此协程可以发送数据到通道中,而另一个协程可以从该通道中读取数据。
在这里就要引入一个新名词:协程
将线程再细分为多个协程,比如说是一条流水线上的多人协作。那么就可以减少各个线程内部的等待时间。
5 .通道简介
Go 提供一个 chan 关键词去创建一个通道。一个通道只能传入一种类型的数据,其他的数据类型不允许被传输。

将线程再分成更细的协程,使得中间等待时候更少,提高效率!
5.1 声明
package main
import "fmt"
func main(){
var channel chan int //声明了一个可以传入 int 类型数据的通道 channel 。
fmt.Println(channel)
//程序会打印nil, 因为通道的 0 值是 nil。
}
一个 nil 通道是没有用的。你不能向它传递数据或者读取数据。
因此,我们必须使用 make 函数器创建一个可以使用的通道。
package main
import "fmt"
func main(){
channel := make(chan int)
//声明了一个可以传入 int 类型数据的通道 channel 。
fmt.Println(channel)
//程序会打印channel的地址。 0xc0000180c0
}
它是一个指针内存地址。通道变量默认是一个指针。多数情况下,当你想要和一个协程沟通的时候,你可以给函数或者方法传递一个通道作为参数。当从协程接收到通道参数后,你不需要再对其进行解引用就可以从通道接收或者发送数据。
5.1 读写
Go 语言提供一个非常简洁的左箭头语法
<-去从通道读写数据。
有变量接受管道值
channel <- data
上面的代码意味着我们想要把 data 数据推入到通道 channel 中,注意看箭头的指向。
它表明是从 data数据 to到 通道 channel。
因此我们可以当作我们正在把 data 推入到通道 channel。
无变量接受管道值
<- data
这个语句不会把数据传输给任何变量,但是仍然是一个有效的语句。
上面的通道操作默认是阻塞的。
- 在以前的课程中,我们知道可以使用 time.Sleep 去阻塞一个通道。通道操作本质上是阻塞的。当一些数据被写入通道,对应的协程将阻塞直到有其他的协程可以从此通道接收数据。
- 通道操作会通知调度器去调度其他的协程,这就是为什么程序不会一直阻塞在一个协程。通道的这些特性在不同的协程沟通的时候非常有用,它避免了我们使用锁或者一些 hack 手段去达到阻塞协程的目的。
6 .通道详解
6.1 例子
package main
import "fmt"
func Rush(c chan string) {
fmt.Println("Hello "+ <-c + "!")
// 声明一个函数 greet, 这个函数的参数 c 是一个 string 类型的通道。
// 在这个函数中,我们从通道 c 中接收数据并打印到控制台上。
}
func main(){
fmt.Println("Main Start")
// main 函数的第一个语句是打印 main start 到控制台。
channel := make(chan string)
// 在 main 函数中使用 make 函数创建一个 string 类型的通道赋值给 ‘ channel ’ 变量
go Rush(channel)
// 把 channel 通道传递给 greet 函数并用 go 关键词以协程方式运行它。
// 此时,程序有两个协程并且正在调度运行的是 main goroutine 主函数
channel <- "DEMO"
// 给通道 channel 传入一个数据 DEMO.
// 此时主线程将阻塞直到有协程接收这个数据. Go 的调度器开始调度 greet 协程接收通道 channel 的数据
fmt.Println("Main Stop")
// 然后主线程激活并且执行后面的语句,打印 main stopped
}
/*
Main Start
Hello DEMO!
Main Stop
*/
6.2 死锁
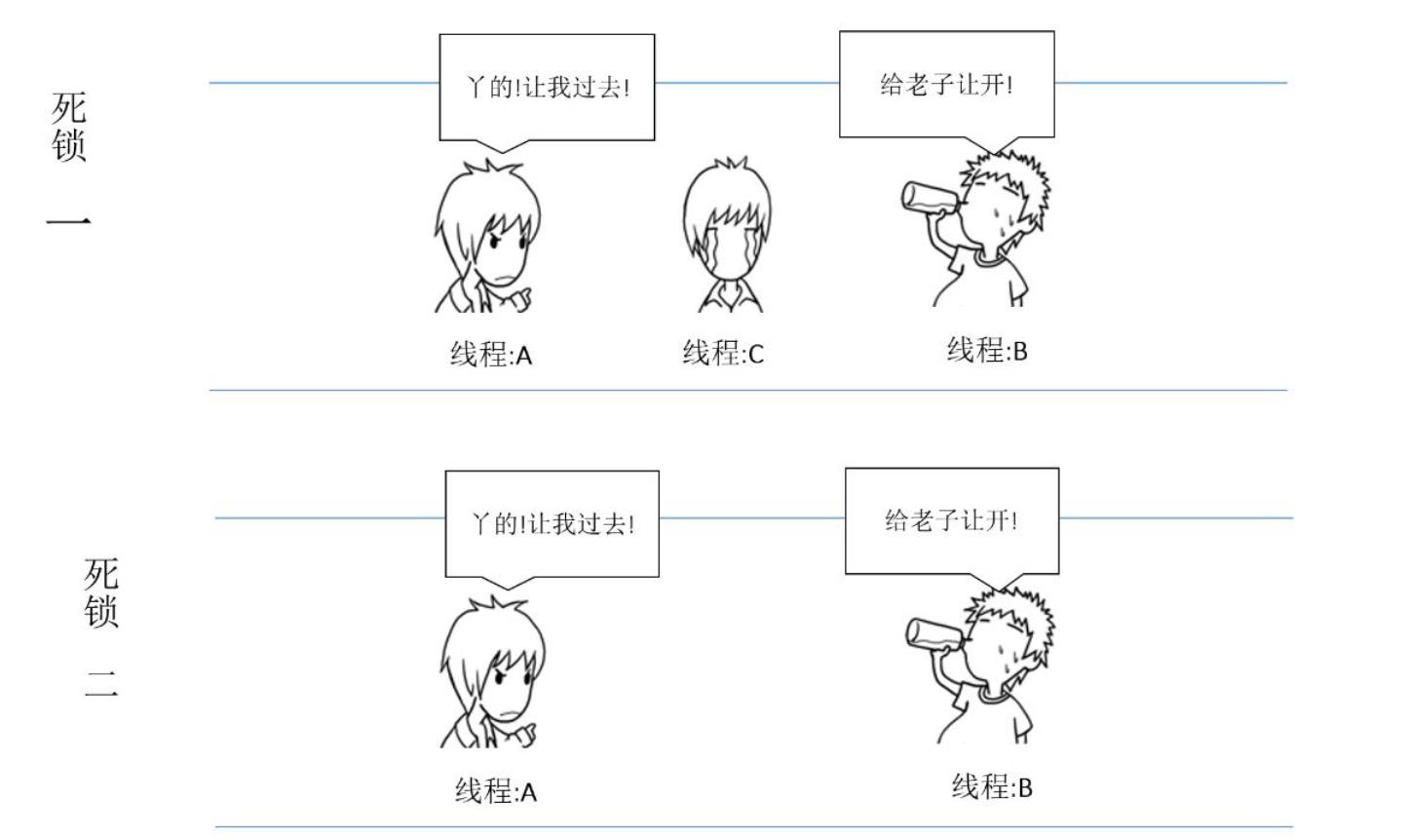
当通道读写数据时,所在协程会阻塞并且调度控制权会转移到其他未阻塞的协程。
- 如果当前协程正在从一个没有任何值的通道中读取数据,那么当前协程会阻塞并且等待其他协程往此通道写入值。
- 因此,读操作将被阻塞。类似的,如果你发送数据到一个通道,它将阻塞当前协程直到有其他协程从通道中读取数据。此时写操作将阻塞 。
下面是一个主线程在进行通道操作的时候造成死锁的例子
package main
import "fmt"
func main() {
fmt.Println("main start")
// main 函数的第一个语句是打印 main start 到控制台。
channel := make(chan string)
// 在 main 函数中使用 make 函数创建一个 string 类型的通道赋值给 ‘ channel ’ 变量
channel <- "GoLang"
// 给通道 channel 传入一个数据 DEMO.
// 此时主线程将阻塞直到有协程接收这个数据. Go 的调度器开始调度协程接收通道 channel 的数据
// 但是由于没有协程接受,没有协程是可被调度的。所有协程都进入休眠状态,即是主程序阻塞了。
fmt.Println("main stop")
}
/*
报错
main start
fatal error: all goroutines are asleep - deadlock! //所有协程都进入休眠状态,死锁
goroutine 1 [chan send]:
main.main()
*/
6.3 关闭通道
package main
import "fmt"
func RushChan(c chan string) {
<- c
fmt.Println("1")
<- c
fmt.Println("2")
}
func main() {
fmt.Println("main start")
c := make(chan string, 1)
go RushChan(c)
c <- "Demo1"
close(c)
/*
不能向一个关了的channel发信息
main start
panic: send on closed channel
*/
c <- "Demo2"
//close(c)
/*
close 放这里的话可以
main start
1
2
Main Stop
*/
fmt.Println("Main Stop")
}
- 第一个操作
c <- "Demo2"将阻塞协程直到有其他协程从此通道中读取数据,因此 greet 会被调度器调度执行。 - 第一个操作
<-c是非阻塞的 因为现在通道c有数据可读。 - 第二个操作
<-c将被阻塞因为通道c已经没数据可读. - 此时
main协程将被激活并且程序执行close(c)关闭通道操作。
6.4 缓冲区
c := make(chan Type, n)
- 当缓冲区参数不是 0 的时候。协程将不会阻塞除非缓冲区被填满。
- 当缓冲区满了之后,想要再往缓冲区发送数据只有等到有其他协程从缓冲区接收数据, 此时的发送协程是阻塞的。
- 有一点需要注意, 读缓冲区的操作是渴望式读取,意味着一旦读操作开始它将读取缓冲区所有数据,直到缓冲区为空。
- 原理上来说读操作的协程将不会阻塞直到缓冲区为空。
package main
import "fmt"
func RushChan(c chan string) {
for {
val ,_ := <-c
fmt.Println(val)
}
}
func main() {
fmt.Println("Main Start")
c := make(chan string, 1)
go RushChan(c)
c <- "Demo1" //结果1
//c <- "Demo2" //结果2
fmt.Println("Main Stop")
}
/*
结果1:
Main Start
Main Stop
*/
/*
结果2:
Main Start
Join
Mike
Main Stop
*/
- 由于这是一个缓冲的通道,当我只有
c <- Demo1的时候,这里面只是满了,但是是不会阻塞的。所以子协程接受到了这个数据Demo1,但是由于是非阻塞,所以主线程没有被阻塞,并没有等子协程完成就结束了,结果1就是这样出现了。 - 当加多一个
c <- Demo2的时候,这时就要等缓冲区空了,也就是等有协程把Demo1读取,所以就会导致主线程阻塞,此时的结果就是结果2了。
package main
import "fmt"
func RushChan(c chan string) {
for {
val ,_ := <-c
fmt.Println(val)
}
}
func main() {
c := make(chan int,3)
c <- 1
c <- 2
c <- 3
close(c)
for elem := range c {
fmt.Println(elem)
}
}
- 这里虽然关闭了通道,但是其实数据不仅在通道里面,数据还在缓冲区中的,我们依然可以读取到这个数据。
6.5 通道的长度和容量
和切片类似,一个缓冲通道也有长度和容量。
通道的长度是其内部缓冲队列未读的数据量,而通道的容量是缓冲区可最大盛放的数据量。
我们可以使用 len 函数去计算通道的长度,使用 cap 函数去获得通道的容量。和切片用法神似
package main
import "fmt"
func RushChan(c chan string) {
for {
val ,_ := <-c
fmt.Println(val)
}
}
func main() {
c := make(chan int,3)
c <- 1
c <- 2
fmt.Println("长度: ",len(c))
fmt.Println(<-c)
fmt.Println("长度: ",len(c))
fmt.Println(<-c)
fmt.Println("长度: ",len(c))
fmt.Println("容量: ",cap(c))
}
/*
结果:
长度: 2
1
长度: 1
2
长度: 0
容量: 3
*/
- 这个 c 通道容量为 3,但只盛放了 2 个数据。Go 就不用去阻塞主线程去调度其他协程。
- 你也可以在主线程中去读取这些数据,因为虽然通道没有放满,也不会阻止你去从通道读取数据。
6.6 单向通道
目前为止,我们已经学习到可以双向传递数据的通道,或者说,我们可以对通道做读操作和写操作。但是事实上我们也可以创建单向通道。比如只读通道只允许读操作,只写通道只允许写操作。
单向通道也可以使用 make 函数创建,不过需要额外加一个箭头语法。
roc := make(<-chan int)
soc := make(chan<- int)
在上面的程序中, roc 是一个只读通道,<- 在 chan 关键词前面。 soc is 只写通道,<- 在 chan 关键词后面。 他们也算不同的数据类型。
但是单向通道有什么作用呢 ?
使用单向通道可以 提高程序的类型安全性, 使得程序不容易出错。
但是假如你在一个协程中只需要读操作某通道,但是在主线程中却需要读写操作这个通道该怎么办呢?
幸运的是 Go 提供了一个简单的语法去把双向通道转化为单向通道。
package main
import "fmt"
func greet(roc <-chan string) {
fmt.Println("Hello " + <-roc ,"!")
}
func main() {
fmt.Println("Main Start")
c := make(chan string)
go greet(c)
c <- "Demo"
fmt.Println("Main Stop")
}
/*
结果
Main Start
Hello Demo !
Main Stop
*/
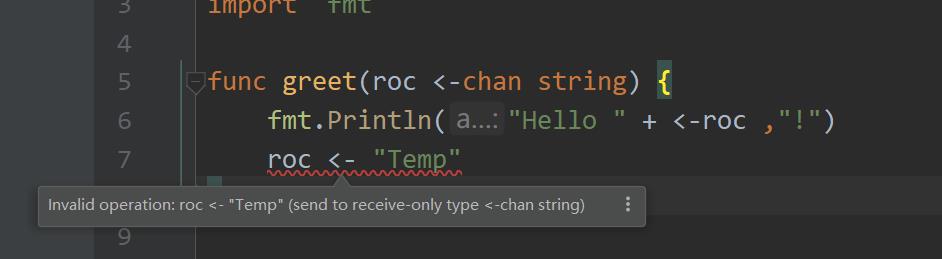
我们修改 greet 协程函数,把参数 c 类型从双向通道改成单向接收通道。
现在我们只能从通道中读取数据,通道上的任何写入操作将会发生错误:
“invalid operation: roc <- “Temp” (send to receive-only type <-chan string)”.
6.7 Select
select 和 switch 很像,它不需要输入参数,并且仅仅被使用在通道操作上。
Select 语句被用来执行多个通道操作的一个和其附带的 case 块代码。
6.7.1 原理
让我们来看下面的例子,讨论下其执行原理
package main
import (
"fmt"
"time"
)
var start time.Time
func init() {
start = time.Now()
}
func service1(c chan string) {
time.Sleep(3 * time.Second)
c <- "Hello from service 1"
}
func service2(c chan string) {
time.Sleep(5 * time.Second)
c <- "Hello from service 2"
}
func main() {
fmt.Println("main start", time.Since(start))
chan1 := make(chan string)
chan2 := make(chan string)
go service1(chan1)
go service2(chan2)
select {
case res := <-chan1:
fmt.Println("Response form service 1", res, time.Since(start))
case res := <-chan2:
fmt.Println("Response form service 2", res, time.Since(start))<以上是关于值得收藏你想知道的并发都在这里传统并发与Go并发的主要内容,如果未能解决你的问题,请参考以下文章