恋上数据结构与算法 —— 布隆过滤器
Posted Johnny*
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了恋上数据结构与算法 —— 布隆过滤器相关的知识,希望对你有一定的参考价值。
Bloom Filter(布隆过滤器)。
布隆过滤器是一个很长的二进制向量和映射函数。
用途
布隆过滤器可以用于检索一个元素是否在一个集合中。
优点是空间效率和查询时间都会远远超过一般的算法,缺点是有一定的误识别率(针对存在的情况)和删除困难。
实现
布隆过滤器由二进制位和映射函数(Hash函数)组成。
Hash函数: 每个元素经过哈希函数处理后都能生成一个索引位置。
二进制位: 经过hash函数所映射过来的相应索引为会 被置为1.
实现过程
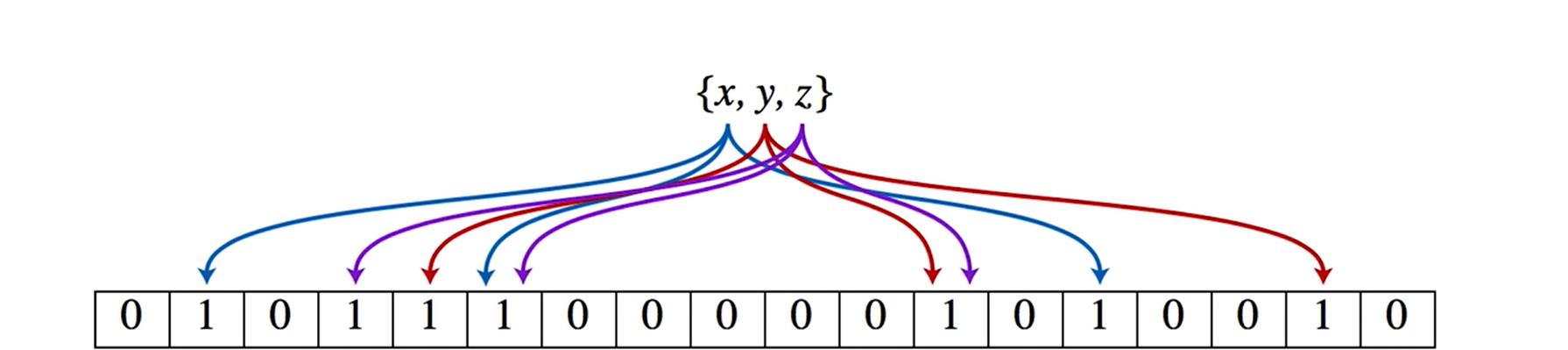
布隆过滤器的插入值操作:
- 待插入的值经过映射函数映射后,得到对应下标。
- 在位数组中相应位置就要置为1。
判断某个元素是否在布隆过滤器中的操作:
- 当有值要判断在不在布隆过滤器中,只需经过 相同的映射计算,得到的下标。
- 如果对应下标位置有为值0的情况,那么该数一定不再布隆过滤器中,如果都是1,则可能存在布隆过滤器中。
出现误判的原因:
不同的字符串可能哈希出来的位置相同(可以适当增加位数组大小或者调整我们的哈希函数来降低概率),如下图所示,B就被误判了。
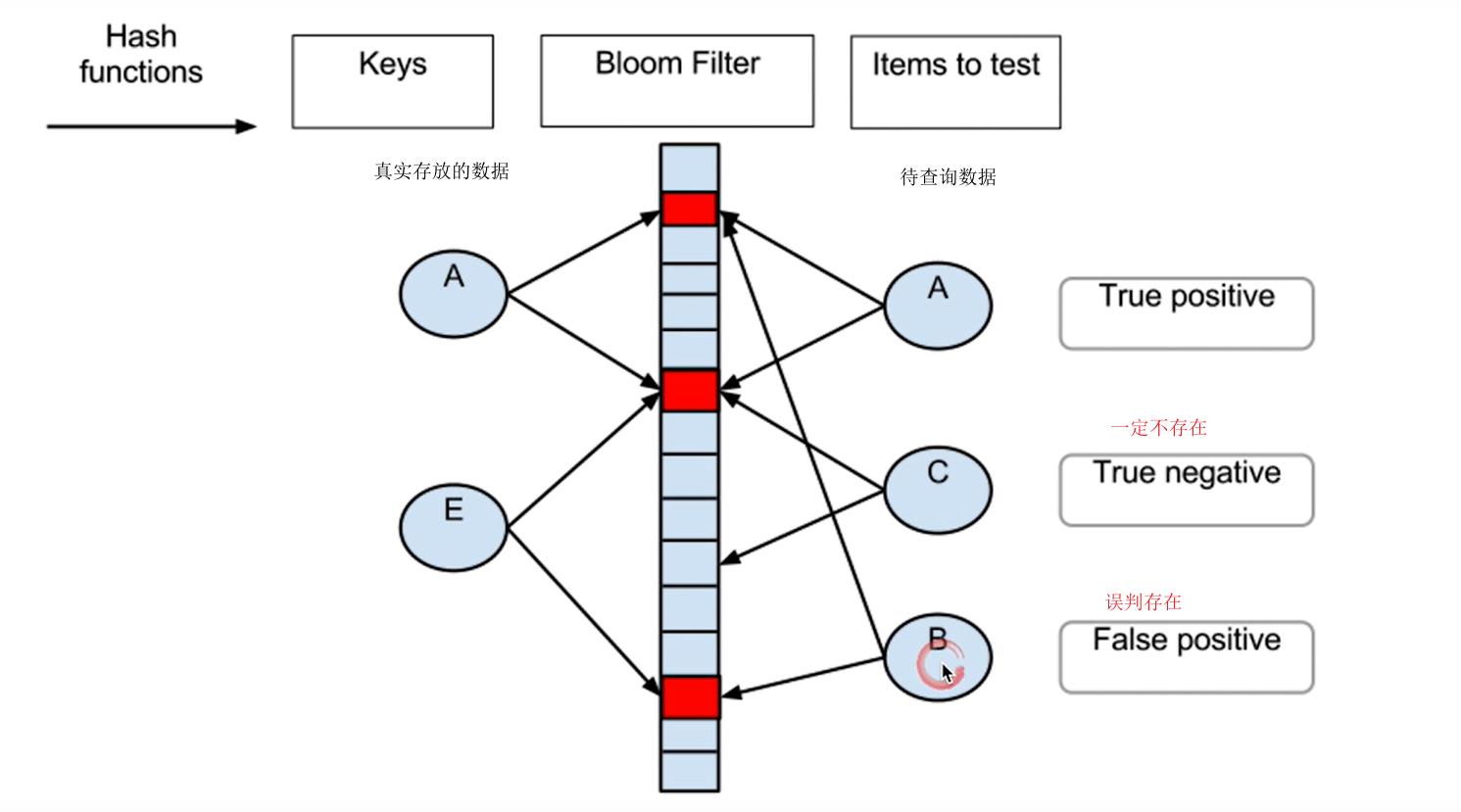
布隆过滤器的误判率
误判率受3个因素影响: 二进制位的个数m、哈希函数的个数k、数据规模n

应用
比特币
分布式系统
复杂度分析
添加、查询的时间复杂度都是O(k),k是哈希函数的个数。
空间复杂度为O(m),m是二进制位数。
代码实现
package filter;
public class BloomFilter<T> {
private long[] bits;
//二进制位的个数
private long bitSize;
//哈希函数个数
private int hashSize;
/**
* 传入误判率(p)和数据规模(n)
* 计算所需的二进制向量长度(filterSize)和哈希函数个数(hashSize),从而构造出布隆过滤器
* @param p 误判率
* @param n 数据规模
*/
public BloomFilter(double p, long n){
if( p <= 0 || p >= 1 || n <= 0) throw new IllegalArgumentException("Wrong argument!");
double ln2 = Math.log(2);
bitSize = (long) (- (n * Math.log(p)) / (ln2 * ln2));
hashSize = (int) (bitSize / n * ln2);
// 1个long型整数有 Long.SIZE位
bits = new long[(int) ((bitSize + Long.SIZE - 1) / Long.SIZE)];
// System.out.println( bitSize + " "+ hashSize);
}
/**
* 往布隆过滤器中增加数据
* @param value
* @return
*/
public boolean put(T value) {
int hash = value.hashCode();
int hash1 = hash >>> 16; //取无符号高16位
boolean result = false;
for(int i = 1; i <= hashSize; i ++){
int combinedHash = hash + (hash1 * i);
//计算的hash值可能为负数
if( combinedHash < 0) combinedHash = ~ combinedHash;
// System.out.println(combinedHash);
//计算索引
int index = (int) (combinedHash % bitSize);
if( set(index) ) result = true;
}
return result;
}
private boolean set(int index) {
//把bits数组的每一个元素看成一个桶
//首先计算落在哪个桶中
int i = index / Long.SIZE;
//然后计算在这个桶的第几位
int j = index % Long.SIZE;
//保存这个桶的值
long value = bits[i];
int bitValue = (1 << j );//1
bits[i]|= bitValue;
//只当i桶第j位为0时 也就是没有哈希冲突时返回true
return (value & bitValue) == 0;
}
/**
* 判断是否在布隆过滤器中
* @param value
* @return
*/
public boolean contains(T value){
int hash = value.hashCode();
int hash1 = hash >>> 16; //取无符号高16位
boolean result = false;
for(int i = 1; i <= hashSize; i ++){
int combinedHash = hash + (hash1 * i);
//计算的hash值可能为负数
if( combinedHash < 0) combinedHash = ~ combinedHash;
//计算索引
int index = (int) (combinedHash % bitSize);
if( !get(index) ) return false;
}
return true;
}
/**
* 判断index位是否为1
* @param index
* @return
*/
private boolean get(int index) {
int i = index / Long.SIZE;
//然后计算在这个桶的第几位
int j = index % Long.SIZE;
int bitValue = (int) ((bits[i] >> j) & 1);
return bitValue == 1;
}
}
以上是关于恋上数据结构与算法 —— 布隆过滤器的主要内容,如果未能解决你的问题,请参考以下文章