使用 Prometheus + Grafana 打造 TiDB 监控整合方案
Posted TiDB_PingCAP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用 Prometheus + Grafana 打造 TiDB 监控整合方案相关的知识,希望对你有一定的参考价值。
作者介绍:王天宜
Prometheus + Grafana 作为一套普适的监控系统广泛应用于各种应用环境中。
本文主要介绍能否将 TiDB + Prometheus 新搭建的监控系统,迁移到已有的监控系统的方案。
对资源比较紧张,高可用需求不强烈的用户,我们建议直接通过 Prometheus Label 进行集群的划分,做到 All in One 的 Prometheus 监控环境。对资源宽裕,高可用需求比较强烈的用户,可以考虑使用 Prometheus 多租户的解决方案。
Grafana 作为一个无状态的应用,如果有高可用的需求,可以考虑通过 Keepalived + Haproxy 的结构部署成高可用的架构。
从本文中,你将将了解到:
-
如何将不同的 TiDB 集群 Prometheus 监控平台整合到同一 Prometheus 平台中
-
如何通过 Grafana 查看 Prometheus 中的 metric
-
如何将不同集群的 cluster 标签注入到 Grafana dashboard 中
-
如何通过 Grafana HTTP API 批量将报表导入到 Grafana 中
-
如何解决大量指标数据造成的 Prometheus 性能问题
-
如何将 Prometheus 中的数据导入到关系型数据库中进行查询或指标分析
-
如何实现 Prometheus 的高可用和高租户
本文的思路导读:
-
我想做什么:将每个集群独立的 Prometheus + Grafana 整合到统一的平台,单一入口进行查询
-
Prometheus如何整合:使用独立的 Prometheus 拉取不同集群的 metric,通过 label 进行区分
-
Grafana 如何整合:需要将每一个 expr 都推入集群的标签信息加以隔离,生成新的报表,使用 Grafana HTTP API 批量导入报表
-
整合后可能带来的风险:Prometheus 数据量炸库,性能缓慢
-
怎么办:拆库!为什么刚合并的库要拆分?
-
拆分的目标:Prometheus 水平扩展,数据集中存储远程库
-
数据集中存储方案:使用 prometheus-postgresql-adapter + TimescaleDB 进行数据存储
-
数据集中存储有什么问题:Dashboard 的 expr 需要从 Timescale DB 中读取,原来的基于 PromSQL 的 expr 无法使用
-
如何解决 SQL 转换 PromSQL 的问题:在 Timescale 上再接一层 Prometheus 进行转换
-
Prometheus 的水平扩展和多租户方案:Thanos
有一些话要提前说一下:
-
作为一个长期奋斗于一线,到了二线三线也放不下一线的 DBA,我最关心三件事情(排名有先后):
-
饭碗拿的好:正确性,数据不能少
-
我想睡得早:稳定性,晚上不报警
-
安心去养老:查询是产品的问题,关我 DBA 什么事情
-
为此,作为一位非著名 DBA,我整理了一下 TiDB 监控整合方案的思路
-
本文是思路,不敢叫做方案
-
本息记录了,我拿出一个方案,再推翻这个方案的迭代过程
-
每个方案都有自己的独特性,所以没有最好的方案,只有最适用的方案
实验的集群环境
操作系统环境介绍
[root@r30 .tiup]# cat /etc/redhat-release
CentOS Stream release 8
[root@r30 .tiup]# uname -r
4.18.0-257.el8.x86_64
TiDB 集群环境介绍
作为实验环境,我们部署了两套 TiDB 集群,tidb-c1-v409,tidb-c2-v409。
在一台独立的机器上,我通过 TiUP 部署了一套集群 tidb-monitor 系统后,只保留 Grafana 与 Prometheus 组件。删除了其他的 TiDB 组件。这套 tidb-monitor 集群是为了模拟我们已有的监控平台,将 tidb-c1-v409 与 tidb-c2-v409 的监控迁移到 tidb-monitor 上。
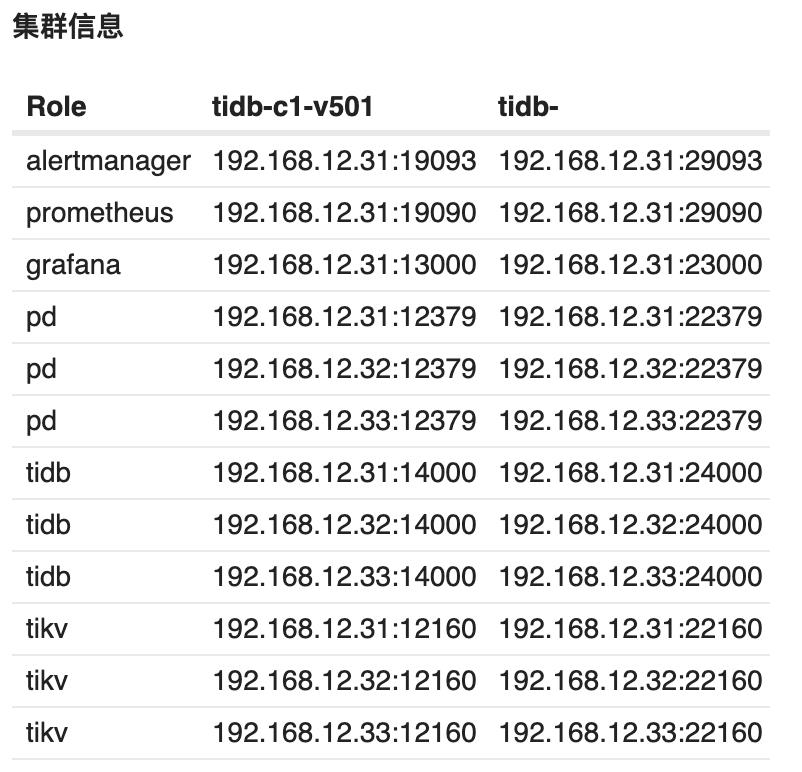
现行的 TiDB 监控框架概述
Prometheus 在 TiDB 中的应用
Prometheus 是一个拥有多维度数据模型的、灵活的查询语句的时序数据库。
Prometheus 作为热门的开源项目,拥有活跃的社区及众多的成功案例。
Prometheus 提供了多个组件供用户使用。目前,TiDB 使用了以下组件:
-
Prometheus Server:用于收集和存储时间序列数据
-
Client 代码库:用于定制程序中需要的 Metric
-
Alertmanager:用于实现报警机制
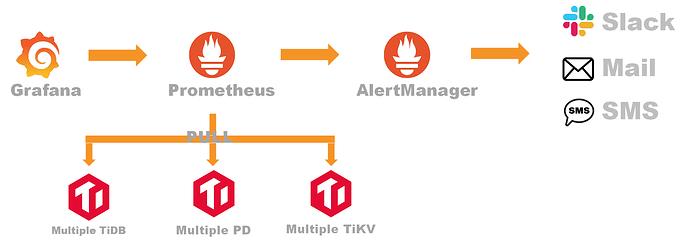
Grafana 在 TiDB 中的应用
Grafana 是一个开源的 metric 分析及可视化系统。
TiDB 使用 Grafana 来展示 TiDB 集群各组件的相关监控,监控项分组如下图所示:
Prometheus & Grafana 存在的问题
随着集群数量的增加,部分用户可能存在以下的需求:
-
多套 TiDB 集群无法共享一套监控集群
-
Prometheus 本身不具有高可用性随着数据量的增长
-
Prometheus 的查询速度会降低
于此,我们考虑是否可以整合不同集群的 Prometheus 和 Grafana,做到多集群共用一套建监控系统。
Prometheus 的整合方案
Prometheus 简介
TiDB 使用开源时序数据库 Prometheus 作为监控和性能指标信息存储方案,使用 Grafana 作为可视化组件进行信息的展示。Prometheus 狭义上是软件本身,即 prometheus server,广义上是基于 prometheus server 为核心的各类软件工具的生态。除 prometheus server 和 grafana 外,Prometheus 生态常用的组件还有 alertmanager、pushgateway 和非常丰富的各类 exporters。prometheus server 自身是一个时序数据库,相比使用 mysql 做为底层存储的 zabbix 监控,拥有非常高效的插入和查询性能,同时数据存储占用的空间也非常小。如果要使用 prometheus server 接收推送的信息,数据源和 prometheus server 中间需要使用 pushgateway。
Prometheus 监控生态非常完善,能监控的对象非常丰富。详细的 exporter 支持对象可参考官方介绍 exporters列表 。Prometheus 可以监控的对象远不止官方 exporters 列表中的产品,有些产品原生支持不在上面列表,如 TiDB; 有些可以通过标准的 exporter 来监控一类产品,如 snmp_exporter; 还有些可以通过自己写个简单的脚本往 pushgateway 推送;如果有一定开发能力,还可以通过自己写 exporter 来解决。同时有些产品随着版本的更新,不需要上面列表中的 exporter 就可以支持,比如 ceph。随着容器和 kurbernetes 的不断落地,以及更多的软件原生支持 Prometheus,相信很快 Prometheus 会成为监控领域的领军产品。
Prometheus 架构介绍
Prometheus 的架构图如下:
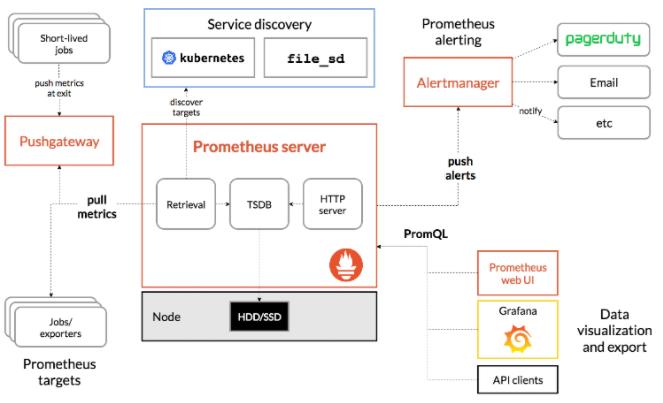
Prometheus 生态中 prometheus server 软件用于监控信息的存储、检索,以及告警消息的推送,是 Prometheus 生态最核心的部分。Alertmanger 负责接收 prometheus server 推送的告警,并将告警经过分组、去重等处理后,按告警标签内容路由,通过邮件、短信、企业微信、钉钉、webhook 等发送给接收者。大部分软件在用 Prometheus 作为监控时还需要部署一个 exporter 做为 agent 来采集数据,但是有部分软件原生支持 Prometheus,比如 TiDB 的组件,在不用部署 exporter 的情况下就可以直接采集监控数据。PromQL 是 Prometheus 数据查询语言,用户可以通过 prometheus server 的 web UI,在浏览器上直接编写 PromQL 来检索监控信息。也可以将 PromQL 固化到 grafana 的报表中做动态的展示,另外用户还可以通过 API 接口做更丰富的自定义功能。Prometheus 除了可以采集静态的 exporters 之外,还可要通过 service discovery 的方式监控各种动态的目标,如 kubernetes 的 node,pod,service 等。除 exporter 和 service discovery 之外,用户还可以写脚本做一些自定义的信息采集,然后通过 push 的方式推送到 pushgateway,pushgateway 对于 prometheus server 来说就是一个特殊的 exporter,prometheus server 可以像抓取其他 exporters 一样抓取 pushgateway 的信息。
Promethes 的 Label 使用规则
Prometheus 根据 Label 区分不同的 Metric
在主机中可以添加不同的 Label,可以用于区分相同名称不同集群的 metric,也可以用于聚合相同集群的不同 metric:
## modify prometheus.conf
static_configs:
- targets: ['localhost:9090']
labels:
cluster: cluster_1
## check prometheus configuration file
./promtool check config prometheus.yml
## reconfig the prometheus
kill -hup <prometheus_pid>
## get the cpu source aggregation
sum(process_cpu_seconds_total{cluster='cluster_1'})
可以通过标签停止或保留数据采集:
## stop the metric collection for the jobs with the label cpu_metric_collection_drop
scrape_configs:
- job_name: 'cpu_metric_collection'
static_configs:
- targets: ['localhost:9090']
relabel_configs:
- action: drop
source_labels: ['cpu_metric_collection_drop']
## keep the metric collection for the jobs with the label cpu_metric_collection_keep
scrape_configs:
- job_name: 'cpu_metric_collection'
static_configs:
- targets: ['localhost:9090']
relabel_configs:
- action: keep
source_labels: ['cpu_metric_collection_keep']
Prometheus 的 relabel 操作
在 Prometheus 监控体系中,标签 Label 是一个极为重要的参数。在一个集中、复杂的监控环境中,我们可能无法控制正在监控的资源以及他们的指标数据。重新定义监控的标签可以在复杂的环境中,有效的控制和管理数据指标。在 Prometheus 拉取 exportor 的数据后,会对数据标签进行编辑,也允许用户通过 relabel_configs 参数处理标签,包括修改、添加以及删除不必要的标签。
# The source labels select values from existing labels. Their content is concatenated
# using the configured separator and matched against the configured regular expression
# for the replace, keep, and drop actions.
[ source_labels: '[' <labelname> [, ...] ']' ]
# Separator placed between concatenated source label values.
[ separator: <string> | default = ; ]
# Label to which the resulting value is written in a replace action.
# It is mandatory for replace actions. Regex capture groups are available.
[ target_label: <labelname> ]
# Regular expression against which the extracted value is matched.
[ regex: <regex> | default = (.*) ]
# Modulus to take of the hash of the source label values.
[ modulus: <int> ]
# Replacement value against which a regex replace is performed if the
# regular expression matches. Regex capture groups are available.
[ replacement: <string> | default = $1 ]
# Action to perform based on regex matching.
[ action: <relabel_action> | default = replace ]
在以上的例子中,<relabel_action> 可以包含以下的集中操作:
-
replace:使用replacement的值替换被regex正则匹配到source_label;
-
keep:保留被匹配到的标签的metric,删除未被匹配到标签的 metric;
-
drop:删除被匹配到的标签的metric,保留未被匹配到标签的metric;
-
hashmod:将target_label设置成source_label的modulus配置的hash值;
-
labelmap:将regex匹配到的所有标签的名称配置成新的标签,值配置成新标签的值;
-
labeldrop:将符合规则的标签删除,保留未被匹配的标签;
-
labelkeep:将符合规则的标签保留,删除未被匹配的标签。
通过以上对 Prometheus Label 的介绍,我们可以考虑使用 Label 这种特性,来标记区分不同的 TiDB 集群。
通过 Label 来区分 TiDB 中不同的集群信息
修改 Prometheus 的配置文件的几种方案
以 tidb 这个 job 为例,我们来完成一个最基本的配置。修改 tidb job 主要有两种思路:
-
创建一个 tidb job,使用 relabel_configs 给这个 job 分别打上两个标签,tidb-c1-v409 与 tidb-c2-v409
-
创建两个 tidb job,job-tidb-c1-v409 与 job-tidb-c2-v409
方案一:创建 tidb job,通过 relabel_configs 区分不同的 cluster
## The first way - create one job for tidb, and distinguish different clusters by relabel_configs operation
- job_name: "tidb"
honor_labels: true # don't overwrite job & instance labels
static_configs:
- targets:
- '192.168.12.31:12080'
- '192.168.12.32:12080'
- '192.168.12.33:12080'
- '192.168.12.31:22080'
- '192.168.12.32:22080'
- '192.168.12.33:22080'
relabel_configs:
- source_labels: [ '__address__' ]
regex: '(.*):12080'
target_label: 'cluster'
replacement: 'tidb-c1-v409'
- source_labels: [ '__address__' ]
regex: '(.*):22080'
target_label: 'cluster'
replacement: 'tidb-c2-v409'
在上面的配置中:
-
‘address’ 表示 targets 过滤出来的地址,在这个例子中,可以过滤出六个值,192.168.12.3{1,2,3}:{1,2}2080;
-
regex 表示通过正则表达式将上面 source_labels 过滤出来的结果进行匹配;
-
target_label 表示将标签 address 重命名为 cluster;
-
replacement 表示将正则表达式匹配出来的结果重命名为 tidb-c1-v409 或者 tidb-c2-v409;
-
重新加载 prometheus 配置文件,在 prometheus 的 GUI 页面,status -> targets 里面可以看到以下的结果。
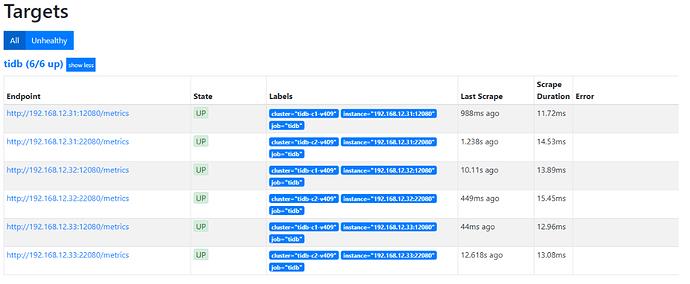
方案二:创建不同的 job 以区分不同的 cluster
## The second way - create two jobs for different clusters
- job_name: "tidb-c1-v409"
honor_labels: true # don't overwrite job & instance labels
static_configs:
- targets:
- '192.168.12.31:12080'
- '192.168.12.32:12080'
- '192.168.12.33:12080'
labels:
cluster: tidb-c1-v409
- job_name: "tidb-c2-v409"
honor_labels: true # don't overwrite job & instance labels
static_configs:
- targets:
- '192.168.12.31:22080'
- '192.168.12.32:22080'
- '192.168.12.33:22080'
labels:
cluster: tidb-c2-v409
在上面的配置中:
-
job_name 可以作为区分两个不同 cluster 的标识;
-
针对不同的 job,target 里面只配置独立的集群 endpoints 信息;
-
通过 labels 打一个集群的标签;
-
重新加载 prometheus 配置文件,在 prometheus 的 GUI 页面,status -> targets 里面可以看到以下的结果。
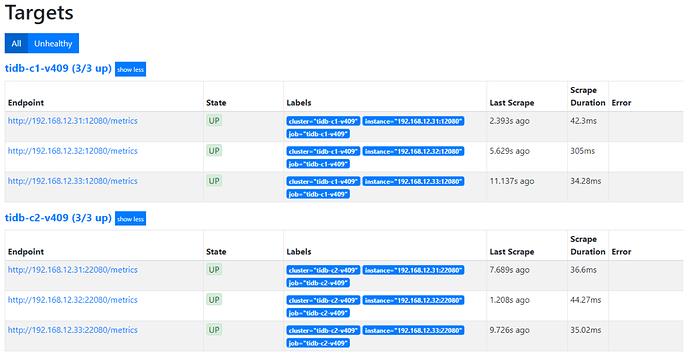
很难比较两种方案的优劣,第一种方案减少了 job 数量,但是增加了 job 里面 label 的数量。第二种方案,减少了 job 里面 label 的数量,但是增加了 job 的数量。就好像计算 2 * 3 * 4,很难比较是 (2 * 3) * 4 好一些还是 2 * (3 * 4) 好一些。
Prometheus 配置文件的修改案例
使用第一种方案,通过 relabel_configs 进行集群的区分。
针对于 blackbox_exporter,由于两套集群部署上有机器的交集,实际的生产环境中,从节省资源的角度上考虑,只起一个 blackbox_exporter 就可以了。
在改实验环境中,可以参考 prometheus-example 。
当我们重新家在 Prometheus 服务后,可以在 Prometheus 的 web GUI 中的 status -> target 中查看所有的 job 是否都是 UP 的状态。
随机检查一个 metric,例如 pd_regions_status,可以看到 cluster 标签有两个值,tidb-c1-v409 与 tidb-c2-v409。
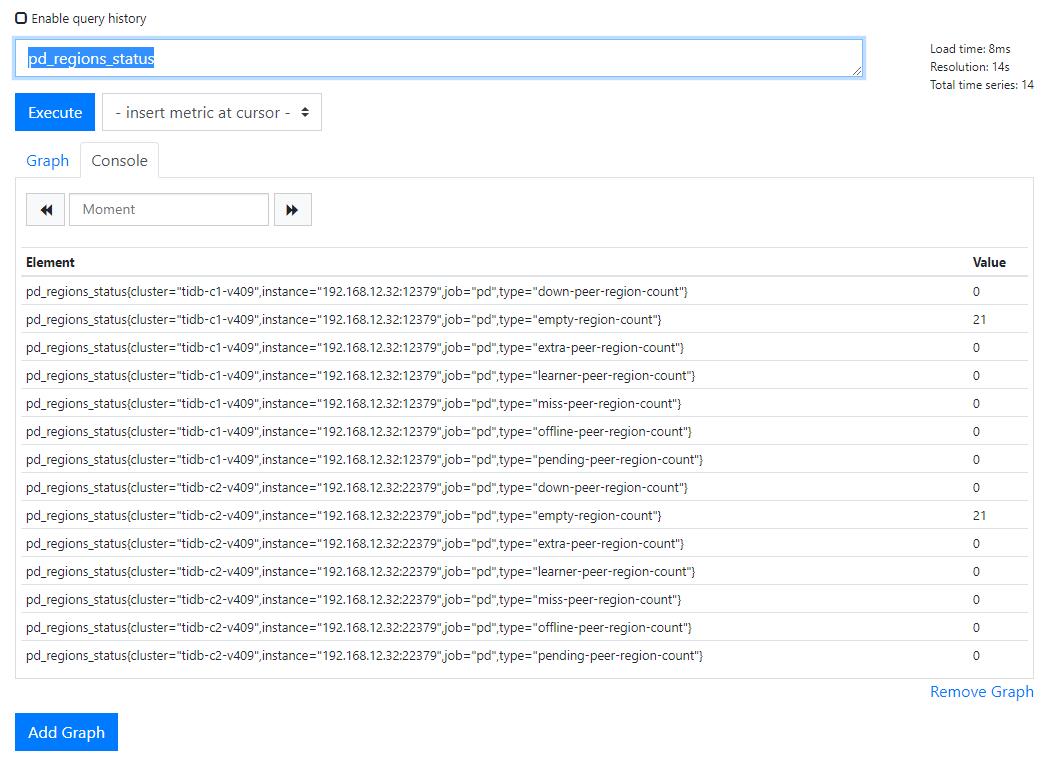
Grafana 整合方案
在 Grafana 中查看 Datasource 的信息
因为在 Prometheus 已经把所有的 metric 整合到同一个 Prometheus 中,所以需要在 Grafana 中配置这个 Prometheus。
查看 Grafana 中的报表
以 overview 报表为例,发现报表的显示有一点异常。两个集群的信息混到了一起,没有办法区分。 本例中,tidb-c1-v409 与 tidb-c2-v409 分别有三个 TiDB 节点,但在 overview dashboard 中,这留个节点信息被混在一起。
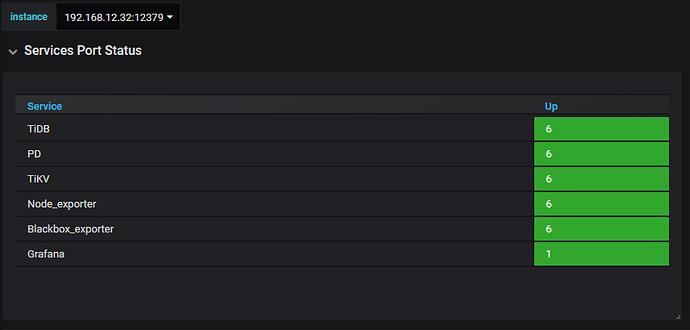
我们以 overview dashboard -> service port status 为例,分析一下报表的定义打开 service port status 的定义,可以查看到 tidb 的公式为 count(probe_success{group="tidb"} == 1)
发现缺少 cluster 的信息,手动推进 cluster 信息,
count(probe_success{cluster="tidb-c1-v409", group="tidb"} == 1)
修改后可以正常显示 tidb-c1-v409 的 TiDB 节点信息。

将 cluster 的信息推入到 dashboard 中
通过手工推入 cluster 的信息,我们可以验证 dashboard 可以正常显示。
以下的逻辑,可以试用脚本推入 cluster 信息到 dashboard 中:
-
通过 curl -s http://192.168.12.34:9090/api/v1/targets 命令可以查看到所有的 metric 的 url遍历这些 url,获得到所有的 metric
-
遍历所有的 metric 信息,在报表中一个一个推入 cluster 信息,以 overview.json 为例
-
对于 “expr”: “node_memory_MemAvailable_bytes” 这样本身没有选项的公式,直接推入 cluster 信息变为 “expr”: “node_memory_MemAvailable_bytes{cluster=“tidb-c1-v409”}”
-
对于 “expr”: “\\ncount(probe_success{group=“tidb”} == 1)” 这样本身已经有了选项的公式,添加 cluster 信息变为 “expr”: “\\ncount(probe_success{cluster=“tidb-c1-v409”,group=“tidb”} == 1)”
可以参考脚本 tidb_dashboard_inject_cluster.sh 1
运行 tidb_dashboard_inject_cluster.sh 脚本进行 cluster 信息注入,注意每次需要重新复制原始的 dashboard 文件夹然后运行脚本:
[root@r34 ~]# rm -rf dashboards && cp -r dashboards-bak/ dashboards && ./tidb_dashboard_inject_cluster.sh "tidb-c1-v409" "/root/dashboards" "192.168.12.34:9090"
检查注入后的脚本:
[root@r34 dashboards]# cat overview.json | grep expr | grep -v tidb-c1-v409
"expr": "sum(increase(tidb_server_execute_error_total[1m])) by (type)",
"expr": "sum(rate(tikv_channel_full_total[1m])) by (instance, type)",
"expr": "sum(rate(tikv_server_report_failure_msg_total[1m])) by (type,instance,store_id)",
这几个在 /tmp/tidb-metirc 中都没有出现过,可以手动更改一下。因为并没有获取到 metric,prometheus 也没有这个 metric,所以改不改不是那么重要。
将重定义的报表导入到 Grafana 中
可以难过过脚本 import-dashboard.sh 批量的将 dashboard 通过 Grafana API 导入到 Grafana 中。
详细的过成与原理可以参考 【SOP 系列 14】如何多个 TiDB 集群共用一个 Grafana。
指标整合后所引入的新问题
通过以上的操作,我们已经可以做到将不同集群的 Prometheus 和 Grafana 整合到同一 Prometheus + Grafana 监控平台。这样做有什么风险:
-
整合过程中可能要引入新的 bug - 这是无法避免的,要想定制化,就要容忍 bug。在后期运维中只会越来越好
-
大量的 metric 信息可能会造成
-
Prometheus 的性能问题Prometheus 和 Grafana 还没有高可用
不仅仅是 TiDB 的监控,包括 Kubernetes 的监控再也,也采用了一套集群一套监控的方式进行 metric 的采集。由于Prometheus 本身只支持单机部署,并不支持集群部署方式,我们无法高可用或者水平扩容。Prometheus 的数据存储能力也受限于单机的磁盘容量。在 All in One 的场景中,Prometheus 采集的数据量太大,消耗了大量的资源,可能无法达到最佳的性能。拆分 Prometheus 势在必行。
但是实际环境中,为了节约资源,为了方便运维,很多企业是像上文的方式,将多个不同的集群监控整合到一个监控平台中。多快好省这种理念在监控平台上很难实现。多就不能快,好久不能省。
解决性能问题可以从以下的几个方面来考虑:
-
删除那些使用率低,占用空间高的低性价比指标
-
缩减 Prometheus 存储的历史记录的保留策略
-
将 Prometheus 的数据流入到数仓中
-
使用联邦的方式进行数据汇总
处理性价比较低的指标
针对于那些使用率低,占用空间很高的指标来说,如果业务需求可以满足,那么应当尽早的删除他们。这样的低性价比指标,很有可能会造成 Prometheus 的 OOM。可以通过以下的报警规则找到占用大量空间的指标,如果使用率不高,可以在 relabel_config 中使用 drop 命令删除掉。
count by (\\_\\_name\\_\\_)({\\_\\_name\\_\\_=~".+"}) > 10000
Prometheus 的拆分问题
我们刚才做了什么:把不同的集群信息整合到一个监控平台中。我们要做什么:把一个监控平台的数据拆分到多个 Prometheus 中。
进行 Prometheus 的拆分,可以从以下的几个维度进行考虑:
-
从业务维度进行拆分
-
对超大的业务进行分片
从业务维度进行拆分
从业务维度进行拆分,这种方式刚好和我们的目标是相反的。如果这样拆分的话,那么我什么都不做就挺好的。
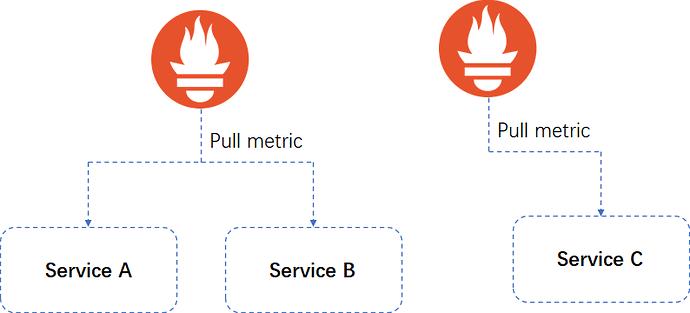
对超大的业务做分片
当业务及其复杂,或者历史数据要长时间保留的时候,可以考虑将业务进行分片,将一个大的业务拆分成多个 group。在这种情况下,我们拆都来不及,更没有必要进行数据整合。
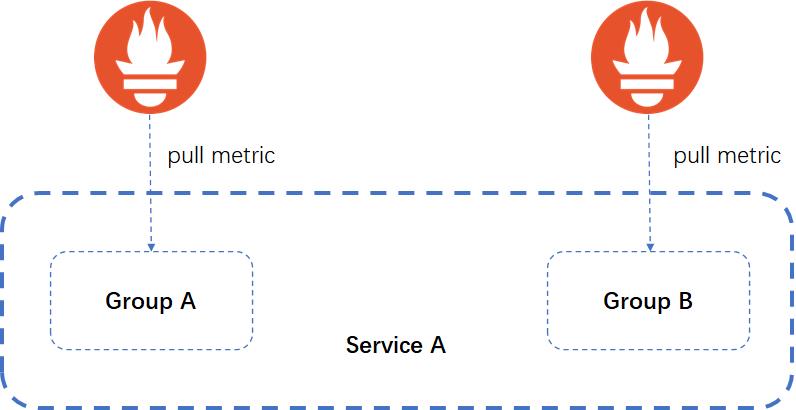
在拆与整合之间进行权衡与妥协
整合的话,可能会带来性能的问题。为了解决性能问题,我们有将 Prometheus 拆分开。To be or not to be, it is a question。假设我们采取一种混合的模式进行妥协:
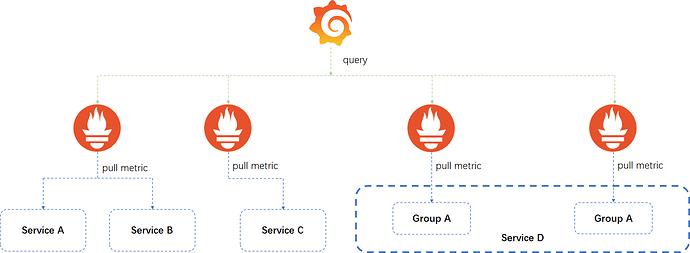
那么可能会引入新的问题,我们的查询可能来自于不同的 datasource。在一个 dashboard 中,我们无法对不能的 dashboard 中进行聚合查询。为了解决这个问题,大体上有两种方案:
-
Prometheus 联邦查询
-
每个业务线都有自己的 Prometheus 监控系统,这个 Prometheus 可能要监控多个子系统
-
由一个中心的 Prometheus server 聚合多个业务线的 Prometheus
-
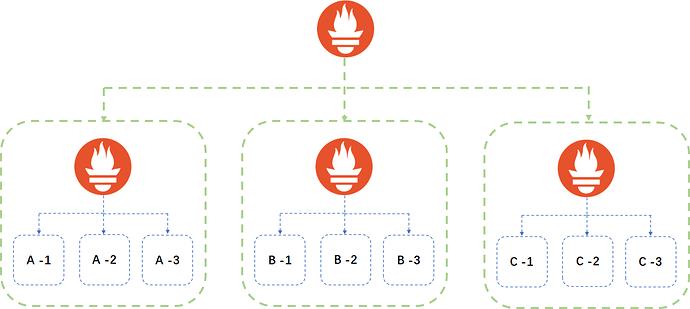
-
数据的集中式存储将
-
Prometheus 中的数据定期导入到数仓中,Prometheus 只保留短时间内的数据
-
把 Prometheus 只当做一个 adapter,不进行数据存储,采集后的数据直接汇总到数据库中
-
Prometheus 本身就是一个时序数据库,可以使用其他的库替代,如 InfluxDB(开源版本不支持高可用)或者 TimescaleDB
-
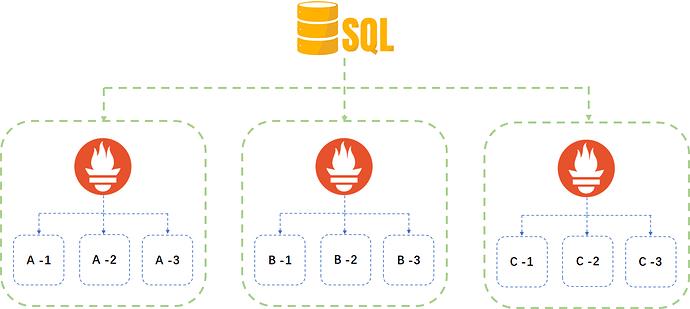
将 Prometheus 的数据集中存储
Prometheus + Grafana 这一套监控系统,本质上和数仓的模式非常类似,都是数据库 + 报表展示的模式。
Grafana也是一个支持多种数据源的报表工具,除了 Prometheus,我们还可以将数据存储在 PostgreSQL 或 MySQL 这样的关系型数据库中。
我们有两种方案将 metric 导入到数据库中:
-
直接通过程序将 metirc 抽取到数据库中;
-
通过 Prometheus 和相关的 adapter 将数据抽取到数据库中:增加了一层中间件,组件多,但工作量少。
将 Prometheus 的数据导入到 PostgreSQL 中
TimescaleDB 作为一款基于 PostgreSQL 的开源时序数据库,本身和 Prometheus 是非常类似的。
相比于 Prometheus,有着更优的查询速度,高可用性及水平扩展行。SQL 语句相比于 PromSQL 来说对运维人员更友好。Timescale 本身提供了插件 prometheus-postgresql-adapter,相比于其他的三方工具,稳定高效易维护。
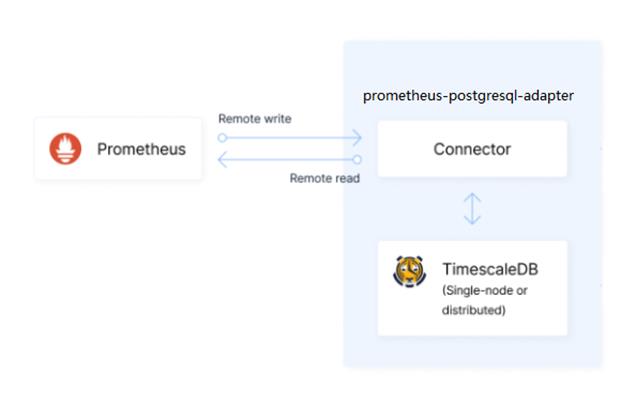
更多 prometheus-postgresql-adapter 的安装步骤,可以参考 prometheus-postgresql-adapter installation
在 prometheus-postgresql-adapter 上更进一步
我们已经可以做到将 Prometheus 的元数据存储到 PostgreSQL 中,那么如何通过 Grafana 进行报表展示? 我们有两条路可以选择:
-
直接使用 PostgreSQL 作为 Grafana 的数据源 - 架构简单,改动工作量巨大;
-
在 PostgreSQL 上再接一层,使用 PromQL 来读取 PostgreSQL 中的数据 - 架构复杂,基本没有什么改动工作量
目前,prometheus-postgresql-adapter 项目已经被 Promscale 项目取代。 相比于 prometheus-postgresql-adapter,Promscale 更方便于使用 TimescaleDB + PostgreSQL 作为 Prometheus 的远程存储。
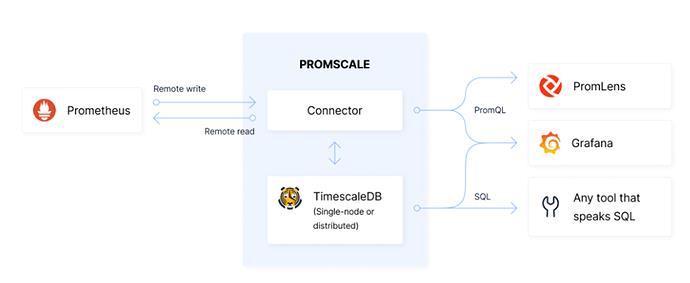
Promscale 为我们提供了以下特性:
-
SQL 和 PromQL 双引擎查询分析 metric
-
PostgreSQL 提供了持久化的存储能力与性能,可以用于历史数据分析
-
数据的高可用性
-
ACID 特性
-
Timescale DB 提供了水平扩展性
Prometheus 的多租户与高可用解决方案
Thanos 与 Cortex 都是 Prometheus 的高可用及多租户的解决方案。并且双双进入 CNCF 孵化器项目。
Cortex 被构建为可扩展,且易于使用的方案,可用于 Prometheus 监控和长期存储,Cortex 多租户的特性,可以在单个集群将不同的 Prometheus 来源隔离,使不授信的各方共享一套集群。Thanos 是一种易于安装的解决方案,可以在用户的 Prometheus 上执行实例,过渡到具有长期存储功能的监控系统中。
Thanos 与 Cortex 都是很好的 Prometheus 多租户与高可用解决方案,但本文选用了 Thanos 方案:
-
Thanos 中所有的组件都是无状态的(stateless)
-
监控数据和集群状态被持久化到对象存储 OSS
-
支持 Prometheus 的高可用部署
-
文档健全,用户量相对于其他方案更多
Thanos 功能与组件
Sidecar:
-
作为 Prometheus 运行 Pod 中的 Sidecar 容器
-
作为 Prometheus 的数据块(chunks)上传到对象存储(OSS)
-
支持多种对象存储(OSS),如 Aliyun、腾讯云、S3、Google 云存储、Azure 存储
-
可无缝集成在 Prometheus operator 中进行部署
Store:
-
从对象存储(OSS)中检索块(chunks),以便查询长周期的监控指标
-
基于时间的分区查询
-
基于标签的分区查询
Compact:
- 为 OSS 中的监控数据创建降采样快(Downsampled chunks),以加快长周期范围内的数据查询
Query:
-
作为 PromQL 查询入口,代替 Prometheus 查询
-
消除来自于不同数据源(多个 Store)的重复数据
-
支持部分响应
Rule:
-
一个简化版本的 Prometheus(主要使用 rule 功能,不抓取数据,不做 PromQL 解析查询)
-
以 Prometheus 2.0 存储格式将结果写入 OSS
-
主要作为 Rule 的存储节点(通过 StoreAPI 将 TSDB 块上传到 OSS)
Bucket:
- 监事对象存储 Bucket 中存储的监控数据
Thanos 的 docker-compose 案例
以下项目为 TiDB 对接 Thanos 的 docker-compose 实现:tidb-thanos-quick-start
搭建 Thanos 的 docker-compose 环境需要以下的 image:
-
prom/prometheus:v2.24.1
-
minio/minio:RELEASE.2020-05-01T22-19-14Z
-
prom/node-exporter:v0.18.1
-
prom/alertmanager:v0.21.0
-
grafana/grafana:7.3.7
在这个 docker compose 中,创建了两套 prometheus 监控,分别用来承接两套 tidb 系统的监控。 我们可以单独的部署两无监控的 tidb 集群,通过 docker compose 中的 prometheus 来回收 metric 的信息。这样一来,我们可以在 query 组件中同时查到两套集群的监控。甚至可以加以对比。
以上是关于使用 Prometheus + Grafana 打造 TiDB 监控整合方案的主要内容,如果未能解决你的问题,请参考以下文章