知识追踪数据集介绍
Posted sereasuesue
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识追踪数据集介绍相关的知识,希望对你有一定的参考价值。
困扰了我很久的问题,可能是我喜欢知根知底。见到论文中提到的2009-2010,看到代码中是数据不太一样发出了疑问
常见论文数据集介绍

论文 Improving Knowledge Tracing via Pre-training Question Embeddings
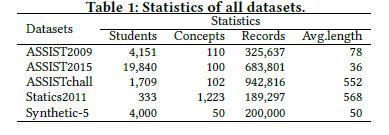
Convolutional Knowledge Tracing: Modeling Individualization in Student Learning Process
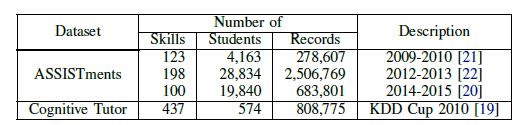
Deep Knowledge Tracing and Dynamic Student Classification for Knowledge Tracing
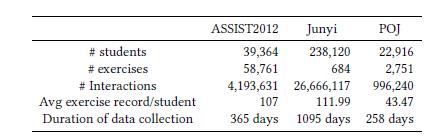
RKT : Relation-Aware Self-Attention for Knowledge Tracing
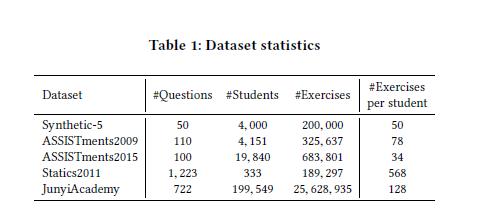
Knowledge Tracing with Sequential Key-Value Memory Networks
ASSISTment 2009-2010
https://sites.google.com/site/assistmentsdata/home/assistment-2009-2010-data描述
2009~2010学年收集的ASSISTment数据。完整数据集分为两个不同的文件,一个是所有技能构建者数据,一个是所有非技能构建者数据。
来自 <https://sites.google.com/site/assistmentsdata/home/assistment-2009-2010-data>
技能建设者数据也称为精通学习数据。此数据集来自技能构建者(精通学习)问题集,其中满足某个条件 (通常设置为连续正确回答3个问题)时,学生被视为掌握了技能 ,并且精通后不会再给出任何问题。
这是备受关注的数据集。单击下面的
该文件包含来自上述两个数据集的数据,此外,它还包含与问题集类型无关的数据。
您可以尝试将这些数据用于的可能研究问题。
RQ1:预测学生表现
教育数据挖掘领域多年来一直在建立学生模型以适合学生数据并预测学生表现。使用ASSISTment数据来预测学生的表现已经做了大量的研究。他们中的一些人正在预测学生的下一个表现,例如在论文中: “援助”模型:利用学生需要多少提示和尝试 ;其中一些是在一段时间间隔后预测学生的表现,例如在论文中: 使用学生建模来估计学生知识 保留。
RQ2:个性化
已经在个性化学生模型方面做出了努力。研究表明,通过个性化学生参数可以改进模型拟合。
以下是使用ASSISTment数据在该领域进行的一些工作示例:
RQ3:车轮旋转
车轮打转是指学生可能难以从问题集中学习技能的情况。如何检测车轮旋转在智能辅导系统中很有用。
有关更多详细信息,请参见以下文章: 旋转:未熟练掌握技能的学生
RQ4:群集
以前的工作已经显示了聚类学生在预测学生表现方面的一些好处。可以探索不同的聚类特征和不同的聚类方法,以更好地改进学生模型。
以下是使用 ASSISTment 数据完成的聚类工作的一些示例:
列标题(此列表是旧的,我们在此处对其中一些字段进行了更完整的描述)
子页面(3): 组合数据集 2009-10非技能构建
数据在这里:
https://drive.google.com/file/d/0B2X0QD6q79ZJUFU1cjYtdGhVNjg/view?usp=sharing
它是在这里举办的:
http://users.wpi.edu/~yutaowang/data/skill_builder_data.csv
更新:在上述链接的数据集中检测到重复的数据记录。可以在这里找到更正的版本:
该文件包含每个学生问题技能的一行(即,如果学生 S 回答具有两个技能的问题 P,则除技能标识符外,所有字段中将有两行具有重复值):
https://drive.google.com/file/d/0B3f_gAH-MpBmUmNJQ3RycGpJM0k/view?usp=sharing
该文件每个学生问题包含一行(即,如果学生S回答了具有两个技能的问题P,则这两个技能将被折叠为格式skill1_skill2并以单行表示):
https://drive.google.com/file/d/1NNXHFRxcArrU0ZJSb9BIL56vmUt5FhlE/view?usp=sharing
该文件包含ASSISTments的Skill-Builder问题集中的数据。
技能构建者问题集具有以下功能:
- 问题基于一项特定技能,一个问题可以具有多个技能标签。
- 学生必须连续回答三个正确的问题才能完成作业。
- 如果学生使用辅导(“提示”或“将这个问题分解为步骤”),问题将被标记为不正确;
- 学生将立即知道他们是否正确回答了问题;
- 如果学生自己无法解决问题,最后的提示会给学生答案;
- 当前, 此功能仅适用于数学问题集。
- try_count
- 学生尝试解决此问题的次数。
- ms_first_response
- 学生第一次响应的时间(以毫秒为单位)。
- tutor_mode
- 导师、测试模式、前测或后测
- answer_type
- 选择_1:多项选择(单选按钮)
- 代数:数学计算字符串(文本框)
- fill_in:简单的字符串比较答案(文本框)
- open_response:记录学生的回答,但他们的回答总是被标记为正确
- sequence_id
- 问题集的内容 ID。分配相同问题集的不同作业将具有相同的序列 ID。
- student_class_id
- 类ID。
- 位置
- 课堂作业页面上的作业位置。
- problem_set_type
- 线性 - 学生按预定顺序完成所有问题。
- 随机 - 学生完成所有问题,但每个学生都以不同的随机顺序呈现问题。
- 掌握 - 随机顺序;并且学生必须通过连续纠正一定数量的问题(默认为3个)来“掌握”问题集,然后才能继续。
- base_sequence_id
- 这是为了说明是否已复制序列。这将指向原始副本,如果尚未复制,则与sequence_id相同。
- 技能ID
- 与问题相关的技能的ID。
- 对于技能构建器数据集,同一数据记录的不同技能位于不同的行中。这意味着,如果学生回答一项多技能问题,则该记录将重复多次,并且每次重复都将使用一项多技能标记。
- 对于非技能生成器数据集,同一数据记录的不同技能在同一行中,用逗号分隔。
- 技能名称
- 与问题相关的技能名称。
- 对于技能构建器数据集,同一数据记录的不同技能位于不同的行中。这意味着,如果学生回答一项多技能问题,则该记录将重复多次,并且每次重复都将使用一项多技能标记。
- 对于非技能生成器数据集,同一数据记录的不同技能在同一行中,用逗号分隔。
- Teacher_id
- 分配问题的老师的 ID。
- 学校 ID
- 分配问题的学校的 ID。
- hint_count
- 学生尝试解决此问题的次数。
- hint_total
- 关于此问题的可能提示数。
- overlay_time
- 学生重叠时间的时间(以毫秒为单位)。
- template_id
- ASSISTment的模板 ID 。具有相同模板ID的助手有相似的问题。
- answer_id
- 多项选择题的答案ID。
- answer_text
- 填写问题的答案文本。
- 第一个动作
- 第一个动作的类型:尝试或请求提示。
- bottom_hint
- 学生是否要求所有提示。
- 机会
- 学生必须练习此技能的机会数量。
- 对于技能构建者数据集,同一数据记录中不同技能的机会位于不同的行中。这意味着如果学生回答了一个多技能问题,该记录将被复制多次,并且每个重复都被标记为多技能之一和相应的机会计数。
- 对于非技能构建者数据集,同一数据记录中不同技能的机会在同一行中,并用逗号分隔。
- 机会_原始
- 学生必须练习此技能的机会数量仅计算原始问题。
- 对于技能构建器数据集,同一数据记录的不同技能的原始机会位于不同的行中。这意味着如果学生回答了一个多技能问题,这个记录会被复制几次,每个重复都被标记为多技能之一和相应的原始机会计数。
- 对于非技能构建者数据集,同一数据记录的不同技能的原始机会在同一行中,用逗号分隔。
-
子页面(3): 组合数据集 2009-10非技能构建
数据在这里:
https://drive.google.com/file/d/0B2X0QD6q79ZJUFU1cjYtdGhVNjg/view?usp=sharing
它是在这里举办的:
http://users.wpi.edu/~yutaowang/data/skill_builder_data.csv
更新:在上述链接的数据集中检测到重复的数据记录。可以在这里找到更正的版本:
该文件包含每个学生问题技能的一行(即,如果学生 S 回答具有两个技能的问题 P,则除技能标识符外,所有字段中将有两行具有重复值):
https://drive.google.com/file/d/0B3f_gAH-MpBmUmNJQ3RycGpJM0k/view?usp=sharing
该文件每个学生问题包含一行(即,如果学生S回答了具有两个技能的问题P,则这两个技能将被折叠为格式skill1_skill2并以单行表示):
https://drive.google.com/file/d/1NNXHFRxcArrU0ZJSb9BIL56vmUt5FhlE/view?usp=sharing
该文件包含ASSISTments的Skill-Builder问题集中的数据。
技能构建者问题集具有以下功能:
- 问题基于一项特定技能,一个问题可以具有多个技能标签。
- 学生必须连续回答三个正确的问题才能完成作业。
- 如果学生使用辅导(“提示”或“将这个问题分解为步骤”),问题将被标记为不正确;
- 学生将立即知道他们是否正确回答了问题;
- 如果学生自己无法解决问题,最后的提示会给学生答案;
- 当前, 此功能仅适用于数学问题集。
以上是关于知识追踪数据集介绍的主要内容,如果未能解决你的问题,请参考以下文章