HashMap集合底层的数据结构以及HashMap集合的存储键值对数据的过程
Posted 杀手不太冷!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap集合底层的数据结构以及HashMap集合的存储键值对数据的过程相关的知识,希望对你有一定的参考价值。
HashMap集合底层的数据结构以及HashMap集合的存储键值对数据的过程
HashMap底层数据结构
HashMap底层数据结构是哈希表。
在JDK1.8之前HashMap由数组+链表数据结构组成的。
在JDK1.8及之后HashMap由数组+链表+红黑树数据结构组成的。
HashMap<String,Integer> hm=new HashMap<>();
当创建HashMap集合对象的时候,在jdk8前,构造方法中创建一个长度是16的Entry[] table,用来存储键值对数据
在jdk8以后不是在HashMap的构造方法底层创建数组了,是在第一次调用put方法时创建的数据,Node[] table如下图:
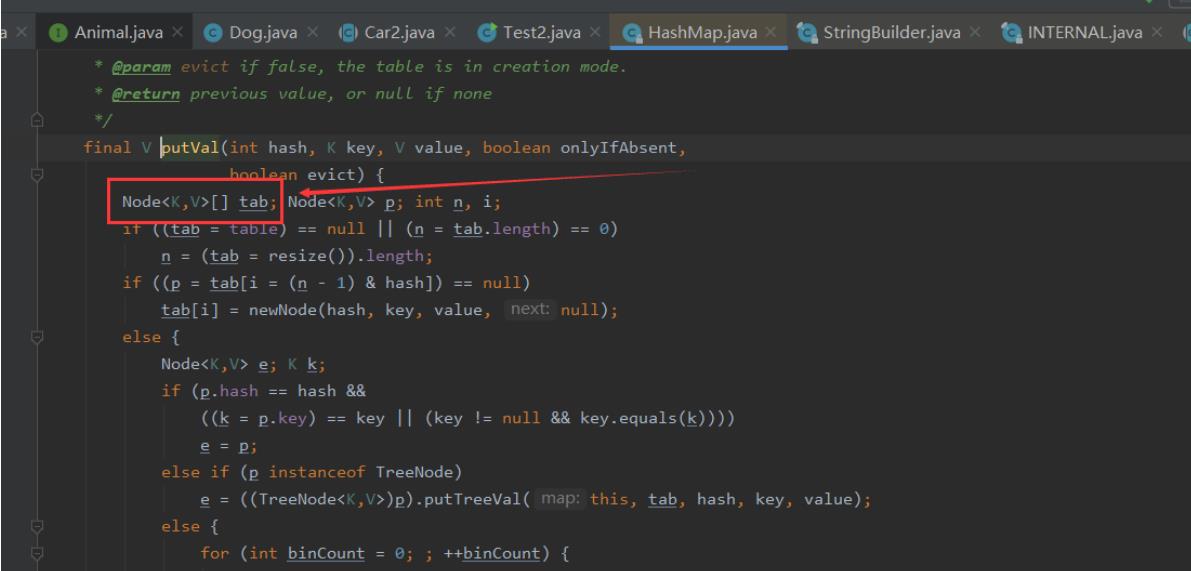
点击put方法的底层可以发现有一个Node[]数组,如下图:
HashMap集合中是怎样存储数据的?
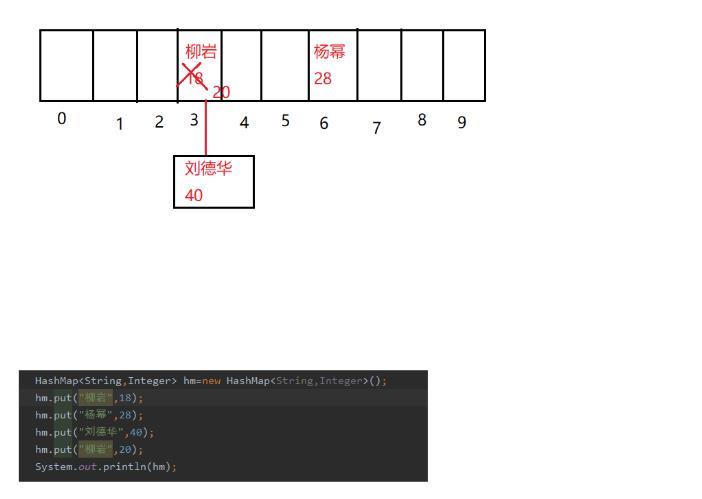
HashMap集合中是怎样存储数据的呢?如下图:
存储数据过程的介绍:
1.HashMap<String,Integer> hm=new HashMap<String,Integer>();
当创建HashMap集合对象的时候,在jdk8前,在构造方法中创建一个长度是16的Entry[] table数组用来存储数据。在jdk8及以后,就不是在HashMap的构造方法底层创建数组了,是在第一次调用put方法的时候创建数组,这个时候创建的是Node[] table数组用来存储键值对数据。
2.当向HashMap中存储键值对柳岩-18的时候,会先根据key代表的对象的hashCode()方法计算出hashCode值,然后结合Node[]数组的长度,根据某种算法计算出哈希值,其实也就是计算出数据在Node数组中存储的索引地址。如果此时计算出的索引地址在Node[]数组中没有存储数据,那么就把柳岩-18直接存储到数组中。举例:假设把柳岩-18存储到hashMap集合中的时候,计算出的索引地址是3.
3.向HashMap中存储键值对杨幂-28,假设此时计算出的索引值是6,发现Node[]数组索引是6的空间处没有存储数据,那么就把键值对杨幂-28直接存储在Node[]数组索引是6的地方。
4.接着向HashMap中存储键值对刘德华-40,这个时候假设key代表的对象刘德华的hashCode()计算出的值结合Node[]数组的长度计算出的索引值也是3,那么这个时候会让"刘德华"的hashCode值和"柳岩"的hashCode值比较,这里它们两个的hashCode值是不一致的,所以会在Node[]数组中索引值为3的空间处划出一个节点,用来存储刘德华-40,这种方法叫做拉链法。
5.最后向HashMap中存储柳岩-20,调用"柳岩"对象的hashCode方法结合Node[]数组长度计算出的索引值也是3,这个时候会让"柳岩"对象的hashCode值和Node[]数组中索引为3的所有的元素的hashCode值进行比较,如果都不相等,那么会在Node[]数组索引为3的空间处划出一个新的节点,用来存储柳岩-20;但是这里柳岩-20键值对中的"柳岩"的hashCode和柳岩-18中的"柳岩"的hashCode值是相同的,这个时候就会发生hash碰撞,然后会调用key代表的对象的equals方法比较这两个对象的内容是否相同,如果内容相同的话则会用新的value代替旧的value,如果内容不相同,那么柳岩-20会继续和索引值为3的其它元素比较hashCode值是否相同,如果都不相同则划出一个节点用来存储柳岩-20,如果相同则会根据equals方法比较二者内容是否相同,一直重复…
6.如果节点长度即链表长度大于阈值8并且数组长度大于64,则将链表变为红黑树。
以上是关于HashMap集合底层的数据结构以及HashMap集合的存储键值对数据的过程的主要内容,如果未能解决你的问题,请参考以下文章