某500强银行基于Zabbix高级特性的全栈自动化监控实践
Posted DBAplus社群
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了某500强银行基于Zabbix高级特性的全栈自动化监控实践相关的知识,希望对你有一定的参考价值。
本文根据蔡翔华老师在〖deeplus直播“运维监控谈:Prometheus与Zabbix的对比选型”〗线上分享演讲内容整理而成。(文末有获取本期PPT&回放的方式,不要错过)

蔡翔华
Zabbix认证专家
国内首批Zabbix认证专家,DevOps Master。活跃于Zabbix和DevOps的社区,参加《DevOps最佳实践》和《Zabbix官方手册》的翻译工作;
10年四大及银行IT基础架构经验,7年Zabbix和DevOps经验。
一、Zabbix适合的监控场景
时常会听到很多运维伙伴在争论,Prometheus和Zabbix哪一个更好?在我看来,脱离实际应用场景讨论技术的优劣其实是没有任何意义的。
在选择具体的监控平台之前,我们最先需要明确,我们监控的目标是什么?在我的理解中,监控分为两个维度:即监控的广度和监控的深度。
1)监控的广度
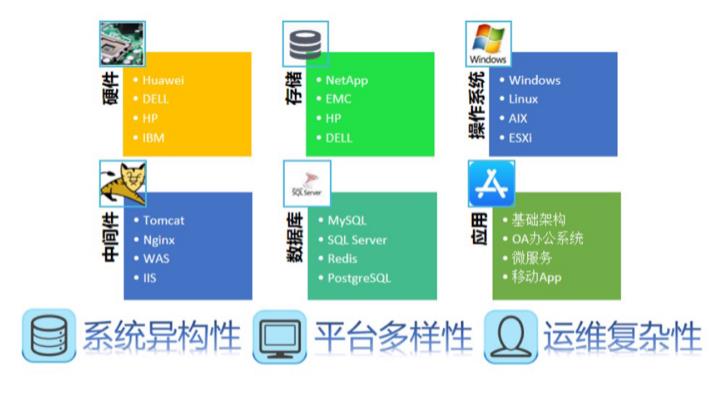
大家所需要监控的系统少则几种,多则几十种,比如需要监控硬件、存储、操作系统、中间件、数据库及应用等。
而在每一个平台中,又存在多种平台:比如我们有华为、戴尔、惠普、IBM的硬件服务器或者交换机,同时也会有Windows、Linux、Aix、ESXi等多种操作系统。
系统和平台维度的组合,意味着我们不仅仅要监控多个层级的监控,也意味着每个层级内部的需要监控的对象更精细化。因此系统异构性和平台的多样性构成了运维的复杂性。
综上,一个理想的监控平台应该支持基于各类系统,覆盖各类厂商和平台的监控。
2)监控的深度

相对的,监控目标需要考虑的另一维度是监控的深度。就监控深度而言,我们可以将其简单分成可用性监控、性能监控、日志监控和自定义监控这四大类。
可用性监控:它的状态是一个布尔型,即只有1或者0。比方说,一个服务是处于停止状态还是运行状态,一个端口是up还是down,根据可用性监控我们可以获知监控对象是否处于正常状态;
日志监控:不管是可用性监控还是性能监控,都基于一定的轮询周期进行采样,在两个采样点之间的监控其实是缺失的,因此在两个采样点之间可能会遗漏一些异常监控数据。通过日志监控,可以记录下每一个操作或者行为,确保监控的完整性。常用的日志监控会分为安全日志、系统日志、应用日志和操作日志等;
自定义的监控:顾名思义,根据我们自身的情况去定义一些符合我们监控需求的监控指标。比如订单数、网络设备流量的聚合运算等等。
一个理想的监控平台应该支持不同的监控深度和方式,从可用性监控、性能监控、日志监控到自定义监控。

综合监控的广度和监控的深度这两点,为我们进行监控平台的选型提供了一个思路和依据:
当我们的环境中只有Windows的服务器时,显然微软的System Center更合适,它不仅能比其他平台更快的发现问题,并有完善的知识库提供具体的解决方案。
不过,通常情况下我们的环境中还充满了网络设备、linux、存储等其他监控对象。这个时候使用System Center去监控可能就比较难以实施了,即使能实施,仍然会存在较高的成本或者技术局限性。同样Solarwind更加适合网络设备的监控。
那么有没有一个产品可以兼具监控的广度和监控的深度呢?经过各种评估和试用,我们认为Zabbix可能是在目前兼顾监控广度和深度的最合适的监控平台。
刚才也提到了Zabbix和Prometheus孰优孰劣一直是大家争议的热点,接下来我们对这两者在不同维度做一些简单的比较。
1)UI方面
① Zabbix 5.0
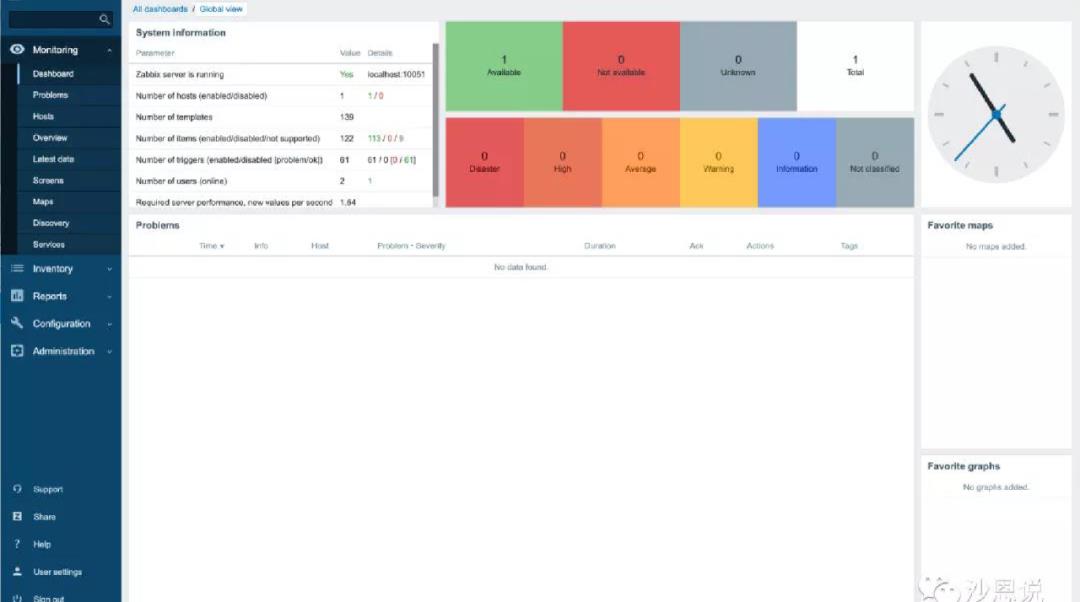
Zabbix一直被吐槽的最多的一点就是它的UI。
的确,在Zabbix早些的版本比如1.8,2.2中,它的UI并没有那么友善和好看。但是官方团队始终在不断迭代和完善UI,5.0的UI已经非常现代化,而且图形图表的展现也更丰富多彩。
同时Zabbix 90%以上的配置管理操作都可以通过Zabbix的Web端实现,仅有一部分基础配置需要通过配置文件处理。这样有一个很大的好处:所有的维护都会有统一的入口,而且只要通过简单的点击、拖拽操作就可以完成,大大提升了运维团队的效率。
② Prometheus
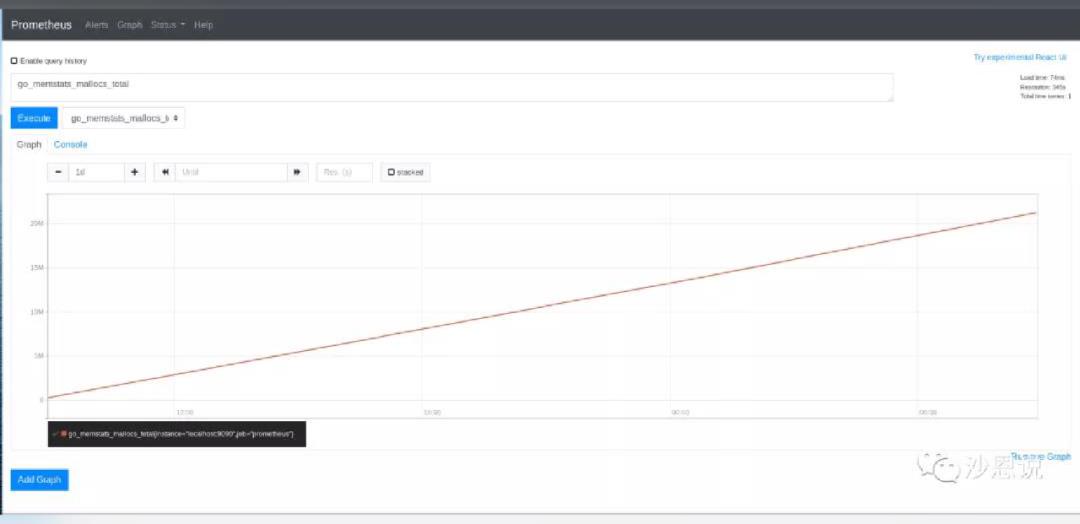
Prometheus的界面相对比较基础,提供类似SQL的查询界面,可以简单查询某些指标。大家更常用的是Grafana作为Prometheus的前端。Zabbix本身也可以把Grafana作为前端,但就原生的UI进行对比,Prometheus稍微简单了点。
同时,Prometheus绝大多数的操作和维护都通过配置文件进行。对上大批量监控对象的维护,必须要依赖于第三方的配置管理工具,因此运维复杂度会比Zabbix更高。
2)架构方面
① Zabbix
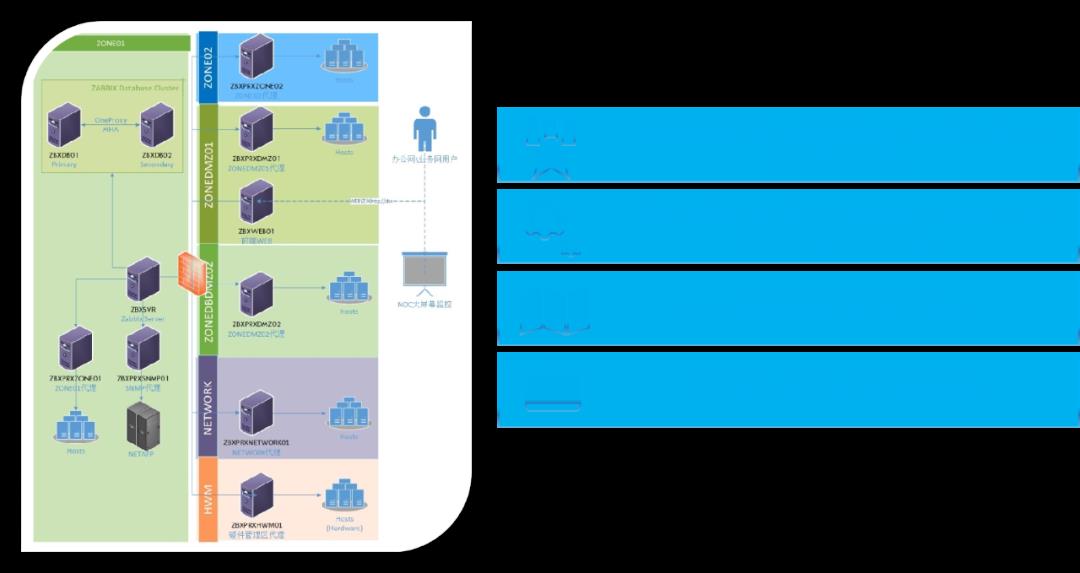
Zabbix是一个分布式的监控系统。在很多公司内部,尤其是金融机构,会存在多个网络区域,每个区域之间进行了隔离。
Zabbix支持在每个网络区域内部署一个Zabbix Proxy,即Zabbix的代理服务器,这个服务器的职责是收集当前区域的监控对象的监控数据。
同时Zabbix Proxy会和Zabbix Server打通,把收集到的数据提供给Zabbix Server进行后续处理,比如触发告警。我们也会把web端部署在一个用户可以访问的区域,这样做的好处是用户可以在正常的办公环境而不是机房中访问Zabbix。
对于Zabbix使用的数据库,使用one proxy或者mycat方式,能够提高它的高可用性,同时也确保数据库的主从分离。这种架构的好处在于从库作为读库提供给其他系统访问,比如CMDB或者报表系统,同时不会影响主库的性能。
由于Zabbix各个组件进行了分离,防火墙上只需要打通一些必要的网络通路,不需要把所有监控主机的端口都像Zabbix Server暴露,从而提升了安全性。
② Prometheus
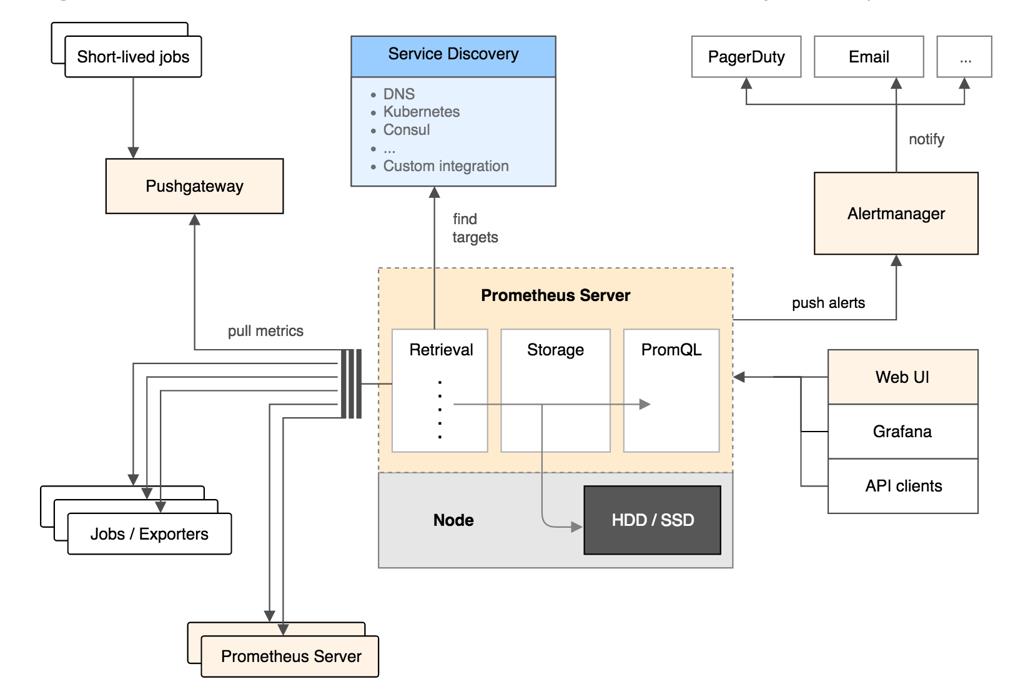
总体而言,Prometheus的架构和Zabbix有很多相似之处:
Prometheus使用各种Exporter进行监控,Exporter的功能类似于Zabbix的Agent,负责收集监控对象端的数据;
Prometheus的AlertManager类似于Zabbix的Action,可以进行报警触发,比如发送短信和邮件。
存在不同的一点是:Prometheus使用的数据库是TSDB时序数据库,Zabbix使用的是mysql或者PgSQL的关系型数据库。TSDB在存储监控的性能会优于传统关系型数据库,因此Zabbix也开始尝试性的支持TSDB作为后端的数据存储。
在监控平台的选型时,也需要评估数据库是否是监控的瓶颈,当性能和压力尚不能成为监控平台的瓶颈时,TSDB时序数据库的优势并不会十分明显。
以上是Zabbix和Prometheus在不同几个方面的对比,那也希望这些对比能为大家在监控平台选型时,提供一定的参考依据。
在我所处的环境中,由于我们需要监控很多不同类型的设备和平台,因此选择了Zabbix作为统一监控平台。依托Zabbix的一些特性,也大大提升了自动化监控的水平。
3)Zabbix的高级特性
① 开源免费,社区支持
很多的软件虽然开源,但会有商业版和社区版区分,比如mysql、puppet等。商业版本会要求用户付费,但同时会提供更完善和更高级的功能。
而Zabbix本身不仅开源,而且不存在商业版和社区版之分,官方保持着定期版本更新的频率,在每一个新版本中也会修复问题或改善用户体验。同时,Zabbix除了原厂团队以外,也会有社区的支持,在中国也有活跃的用户社区,以及每年定期的Zabbix大会等活动。
② 分布式,高可用
Zabbix本身也是分布式高可用的,这也很好的解决了单点的问题。
③ 低级别发现,自动发现
这是Zabbix全栈自动化监控中最不可或缺的两个特性:
低级别发现
低级别发现能帮助我们发现一台设备上所有的监控对象。
试想一个场景,我们有100台服务器,每台服务器上至少有2块硬盘,最多有20块硬盘。如果我们要监控这些磁盘的iops、剩余磁盘空间1、磁盘队列长度等10个指标,需要怎么去添加监控?
常规的做法是,我在每1台服务器上,根据服务器实际的磁盘数量,为每一块磁盘添加监控,如果平均每台10块磁盘,那么就是要增加100*10*10个监控项,总计10000个监控项。不止于此,还要继续为这10000个监控项配置触发器和告警规则。
而在Zabbix中,我们只需创建一个模版,定义低级别发现的规则,并将这个模版同这100台需要监控的服务器关联即可。Zabbix会根据服务器上实际的磁盘数量自动生成对应的监控项,大大提升了添加监控的效率,同时也减少了手动添加监控的纰漏。
自动发现
它能帮助我们快速发现网络内的设备,并按规则识别出它的类型,将其和指定的模版进行关联。
④ 全栈级监控
就像刚才所介绍的,Zabbix在监控的广度和深度之间做了一个比较好的权衡,它是一个全栈级的监控平台。从底层的硬件、操作系统、中间件、数据库,到上层的应用、业务,都可以纳入到Zabbix的监控范围中。
实现了通过一个统一的监控平台,覆盖所有监控对象不同层次监控的需求,同时降低了维护多套监控平台的成本和所需要的知识积累,方便上手。
⑤ 可定制,与DevOps流水线集成
Zabbix本身也是一个开放的系统。提供了丰富的API,这些API几乎可以实现界面上所有的功能,可以同企业内部的DevOps持续交付流水线进行集成,提升整体自动化的水平。
二、Zabbix全栈自动化监控实践案例
接下来,我们来讨论下Zabbix这些高级特性在实际使用场景中的最佳实践案例。
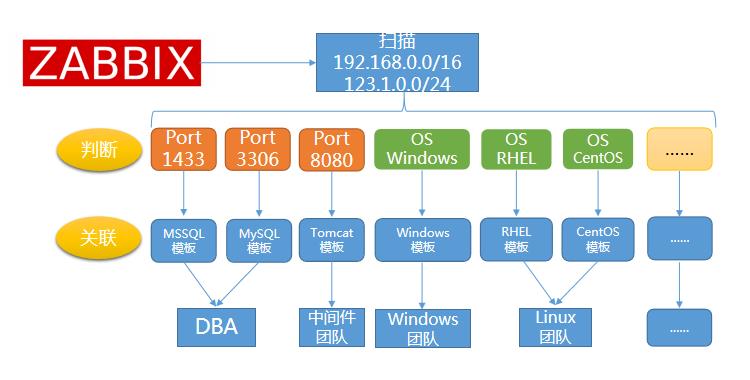
首先来看下我们是如何通过自动发现特性实现监控的自动添加的:
我们会在Zabbix中配置自动发现规则,比如我们对制定的网段进行扫描。当我们发现网段中某个IP的1433端口是打开的,我们基本上可以推断它上面运行着微软的SqlServer服务。
因此,我们通过已经配置好的规则,将发现的这个开放着1433端口的IP和SqlServer模版进行关联。SqlServer的模版是我们预先定制好的对于微软数据库的监控模版,通过自动发现,我们能达到两个目的:
所有的微软数据库都被监控到了;
所有被监控的数据库使用了同一套监控基线,实现了标准化监控。
同样的,我们也可以通过定制不同的规则,来添加不同类型的监控,比如3306是mysql的监控等。除了关联模版,我们会把监控对象添加到不同的组中,确保每个组关联了对应的运维人员。这样做的好处在于,我们不需要频繁的更新告警策略,而当故障发生的时候,对应的管理员也能第一时间收到告警。
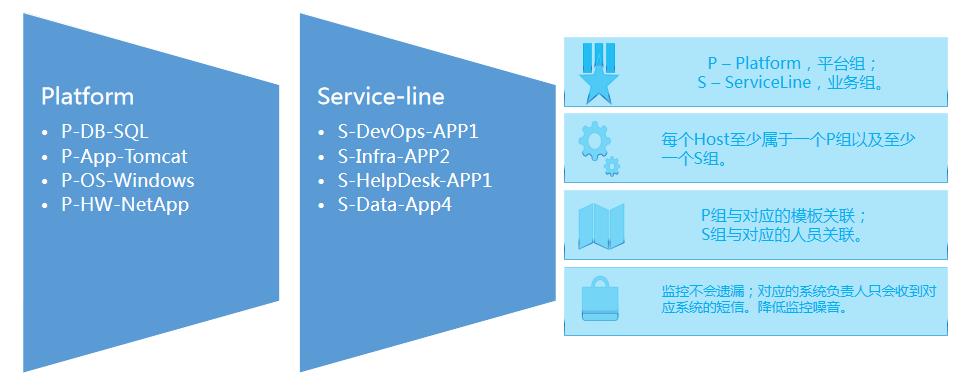
刚才提到了组的概念,我们在实际应用中,一个监控对象属于两个组,即一个P组(平台组)和一个S组(业务组)。
IT运维人员的视角和业务人员的视角存在差异性,通常一个组织内会雇佣不同角色的IT专业人员,比如windows管理员,linux管理员,DBA等。
DBA会负责所有数据库相关的运维工作,而且不在乎这个数据库属于那个应用系统,因此所有的数据库服务器,比如所有的mysql,都会放到一个叫做P-DB-MySql的组中,这个组所有的告警会发送给指定的DBA而不是Windows管理员,同时会和对应的mysql监控模版进行关联。这样做的收益在于DBA只会收到他们所负责系统的告警,同时监控也实现了标准化。
而业务人员关注的是整体业务应用是否正常运行。比如一个登陆系统,它可能有前端的tomcat中间件,还有一台mysql存放着用户登录信息,底层跑着一台HP的服务器。那么我们会把这三个监控对象放在一个叫做S-Department1-Login的组中。这样做的好处在于,一旦一个监控对象出现任何问题,我们可以第一时间知道它影响什么系统。
通过P组和S组的结合,我们可以在监控告警不被遗漏的同时,最大限度降低监控噪音,同时也能直观知晓当前的问题会对那些业务造成影响。

Zabbix支持非常多的告警方式,这点类似于Prometheus的AlertManager。
首先我们会对报警进行分级,Zabbix原生提供了5种级别的告警,即Disaster,High,Warning,Average和Info。我们使用了其中的三种,并给出了这三种级别告警的定义:
Disaster:触发后需要立即处理,如不处理会直接影响生产系统的告警;
Warning:触发后需要尽快处理,短期不处理不会直接影响生产系统;
Info:提示性的告警。
不同级别的报警会对应不同的策略,比如Disaster告警会发送给IT负责人和系统管理员;Warning告警只会发送给系统管理员;Info不会发送告警,但会在监控大屏上展现。具体的告警分级和策略可以根据企业内部的实际情况和监控需求进行定制。
对于告警的呈现方式,主要有邮件、短信和监控大屏等几种,多渠道的告警确保了我们的告警不会被遗漏。
同时我们也会对报警内容进行精细化的定制,包含报警状态(problem或者ok)、具体的问题、出现问题的服务器和IP、问题具体的值等信息。
此外,我们还会在内容中补充该告警对应系统负责人姓名和联系方式,方便我们7x24小时的NOC第一时间联系到相应运维人员处理故障,降低故障时间。
在我们的监控大屏上,也会展现出当前每个系统状态,并显示出具体的问题有哪些,用红色标示出Disaster级别报警,Warning级别的则是黄色。
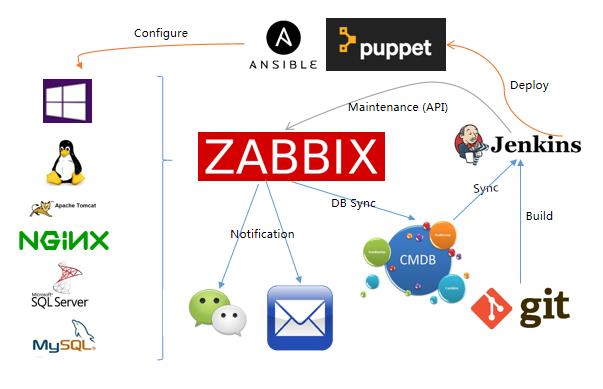
在前面的分享中提到了Zabbix提供了api。基于Zabbix的api,我们将其融入到了DevOps的持续交付流水线。
当持续集成平台Jenkins从版本控制系统git上拉去代码进行构建后,通过ansible等配置管理工具进行应用发布的同时,会调用Zabbix api将对应的主机放入维护模式,从而避免应用发布时的监控噪音。
同时Zabbix也会通过基础信息的收集,为CMDB配置管理数据库提供数据。当告警的时候调用微信、邮件等平台的接口进行告警触发。通过和其他平台的集成,形成完整的持续交付闭环。
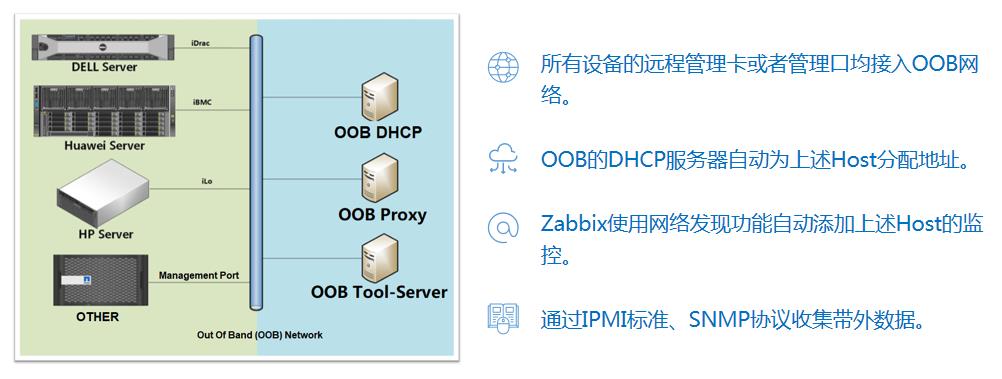
当物理服务器数量大幅上升后,硬件巡检问题是最烧脑的难题。硬件故障存在着随机性。
大多数的组织内部通过定期人工巡检的方式观察硬件是否有故障。而一些组织会通过服务器自带的带外管理平台,HP的iLo,华为的iBMC和戴尔的iDrac等平台,进行带外管理。
当一个机房里面有多种服务器的时候,如果只是依靠这些平台,除了昂贵的license授权,管理成本也非常高昂。即使这些问题解决了,那么那些只支持SNMP的网络设备、存储怎么办呢?
来看看Zabbix是如何解决的:
收集到的带外数据可以作为CMDB配置管理数据库中重要的硬件信息。
通过Zabbix的带外管理大大节约了带外管理平台的授权费用,也降低了带外管理的成本,实现了统一带外管理的目标。
以上就是Zabbix在落地过程中的案例和最佳实践。
三、总结
如果我们只是在Prometheus和Zabbix中选择,应该如何选择一个合适的监控平台?

我的建议是:
当环境是一个纯容器的环境,毫无疑问Prometheus是更适合的选择,Prometheus是天生为容器化平台打造的监控系统;
而当我们环境很复杂,有各种操作系统、硬件、中间件、数据库等,那么Zabbix是更适合的监控平台,Zabbix兼顾了监控的深度和广度,实现了统一监控平台的目的;
当整个环境中又有容器、又有其他的系统,而又希望之用一套监控系统,那么Zabbix更合适,因为Zabbix的最新版本中已经强化了容器化监控的功能;
当然,有余力的话,也可以使用两台监控系统互相补足。
Zabbix有简单易用的UI,自带的Graph和Screen也可以满足企业级的展现需求。90%以上的配置可以通过Web端统一操作和实现,这一点比强依赖于配置文件的Prometheus要更为方便。
当然,如果对于Zabbix的原生UI不满意,仍然可以和Prometheus一样,接入Grafana,大大降低了二次开发的成本。基于平台组和业务组的双维度分组,也使得Zabbix可以在同一组织内为不同团队提供更个性化的展现。
Zabbix的开源、免费等特性使得越来越多的企业,尤其是自研能力不是那么强的中小企业快速实现全栈级监控。Zabbix几乎可以覆盖80%甚至更多的监控需求,它的高级特性也大大减少了人工介入,提升了自动化能力,并可以其他系统和平台进行持续集成。
目前Zabbix的社区非常活跃,拥有丰富的学习资源,大大降低了学习成本。也欢迎大家积极反馈在使用Zabbix中碰到的问题或者改善建议给到我或者Zabbix社区,我们也希望通过不断的迭代和优化使其成为更加优秀的监控平台。
↓点这里可回看本期直播
以上是关于某500强银行基于Zabbix高级特性的全栈自动化监控实践的主要内容,如果未能解决你的问题,请参考以下文章