什么是桶排序,它和希尔排序的区别是什么?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是桶排序,它和希尔排序的区别是什么?相关的知识,希望对你有一定的参考价值。
桶排序 (Bucket sort)或所谓的箱排序,是一个排序算法,工作的原理是将数组分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。桶排序是鸽巢排序的一种归纳结果。当要被排序的数组内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。但桶排序并不是 比较排序,他不受到 O(n log n) 下限的影响。希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因DL.Shell于1959年提出而得名。
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
区别就是桶排序要求数据的长度必须完全一样,而希尔排序是非稳定排序算法。 参考技术A
废话不说了,我把代码以及说明贴给你
#ifndef Bucket_Sort_H#define Bucket_Sort_H
#include<math.h>
#include"Quick_Sort.h"
#define Multi 10
/***************************************************************************
函数说明:桶排序
参数说明:A(输入的无序数组),Size(数组A的长度)
说明:桶排序假设输入是由一个随机过程产生,该过程将元素均匀而独立的分布在[0,1)中;
以线性时间运行,即算法的时间复杂度为Theta(n),当然空间复杂度将是Theta(square(n))
****************************************************************************/
template<typename T> void Bucket_Sort(T *A, int Size)
T * Bucket_array[10];
for (int i = 0; i < Size; i++)
Bucket_array[i] = new T[sizeof(T)*(Size+1)];//生成一个(Size+1)*(Size+1)的矩阵
for (int i = 0; i < Size; i++)
Bucket_array[i][0] = 0;//首位用来放置元素个数
for (int j = 0; j < Size; j++)
int Num = (int)(Multi*A[j]);
int index = ((int)(Bucket_array[Num][0]))+1;
Bucket_array[Num][index] = A[j];
Bucket_array[Num][0]++;
for (int k = 0; k < Size; k++)
Quick_Sort(Bucket_array[k], 1, Bucket_array[k][0]);
for (int i = 0, j = 0; i < Size; i++)
for (int k = 1; k <= Bucket_array[i][0]; k++)
A[j++] = Bucket_array[i][k];
Bucket_array[i][0] = 0;//归零
for (int i = 0; i <10; i++)//十个连续的数组空间,0~9
delete[] Bucket_array[i];
#endif
#ifndef Shell_Sort_H
#define Shell_Sort_H
/*
平均时间复杂度:希尔排序的时间复杂度和其增量序列有关系,这涉及到数学上尚未解决的难题;不过在某些序列中复杂度可以为O(n1.3);
空间复杂度:O(1)
稳定性:不稳定
*/
template<typename T>void shellInsert(T *pArrayData, int Interval, int pArrayNum)
for (int i = Interval; i <= pArrayNum; i++)
int j = i - Interval;
T temp = pArrayData[i]; //记录要插入的数据
while (j >= 0 && pArrayData[j] > temp) //从后向前,找到比其小的数的位置
pArrayData[j + Interval] = pArrayData[j]; //向后挪动
j -= Interval;
if (j != i - Interval) //存在比其小的数
pArrayData[j + Interval] = temp;
template<typename T> void Shell_Sort(T *pArrayData,int pArrayNum)
int Interval = pArrayNum;//跳跃的间隔
bool flag = 0;
while ((Interval >= 1)&&!flag)
if (Interval < 5)
Interval = 1;
flag=1;
else
Interval = (int)((Interval * 5 - 1) / 11);/* 间隔序列中的数字互质通常被认为很重要:也就是说,除了1之外它们没有公约数。
这个约束条件使每一趟排序更有可能保持前一趟排序已排好的效果。希尔最初以N/2为间隔的低效性就是归咎于它没有遵守这个准则。*/
shellInsert(pArrayData, Interval, pArrayNum);
#endif
漫画:什么是桶排序?
第一时间关注程序猿(媛)身边的故事
作者
小灰
已获原作者授权,如需转载,请联系原作者。


————— 第二天 —————







————————————






让我们先来回顾一下计数排序:
计数排序需要根据原始数列的取值范围,创建一个统计数组,用来统计原始数列中每一个可能的整数值所出现的次数。
原始数列中的整数值,和统计数组的下标是一一对应的,以数列的最小值作为偏移量。比如原始数列的最小值是90, 那么整数95对应的统计数组下标就是 95-90 = 5。
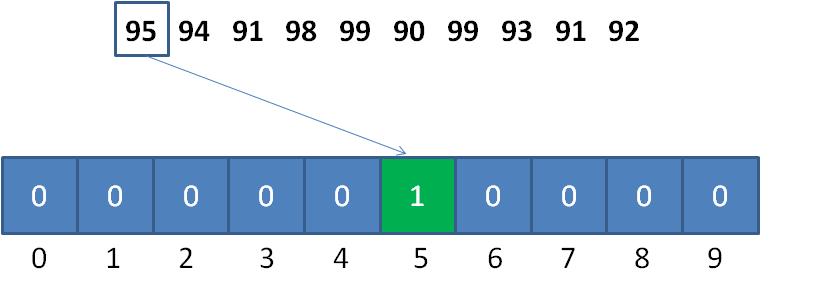
那么,桶排序当中所谓的“桶”,又是什么概念呢?
每一个桶(bucket)代表一个区间范围,里面可以承载一个或多个元素。桶排序的第一步,就是创建这些桶,确定每一个桶的区间范围:
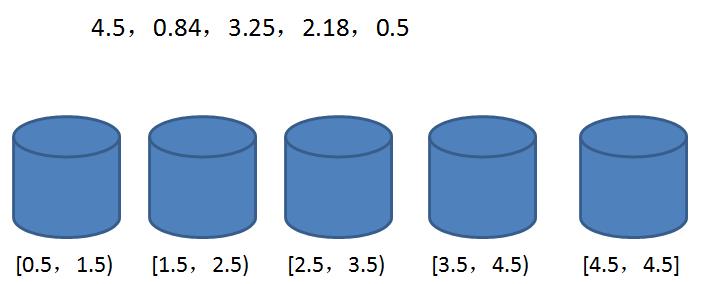
具体建立多少个桶,如何确定桶的区间范围,有很多不同的方式。我们这里创建的桶数量等于原始数列的元素数量,除了最后一个桶只包含数列最大值,前面各个桶的区间按照比例确定。
区间跨度 = (最大值-最小值)/ (桶的数量 - 1)
第二步,遍历原始数列,把元素对号入座放入各个桶中:

第三步,每个桶内部的元素分别排序(显然,只有第一个桶需要排序):

第四步,遍历所有的桶,输出所有元素:
0.5,0.84,2.18,3.25,4.5
到此为止,排序结束。


public static double[] bucketSort(double[] array){
//1.得到数列的最大值和最小值,并算出差值d
double max = array[0];
double min = array[0];
for(int i=1; i<array.length; i++) {
if(array[i] > max) {
max = array[i];
}
if(array[i] < min) {
min = array[i];
}
}
double d = max - min;
//2.初始化桶
int bucketNum = array.length;
ArrayList<LinkedList<Double>> bucketList = new ArrayList<LinkedList<Double>>(bucketNum);
for(int i = 0; i < bucketNum; i++){
bucketList.add(new LinkedList<Double>());
}
//3.遍历原始数组,将每个元素放入桶中
for(int i = 0; i < array.length; i++){
int num = (int)((array[i] - min) * (bucketNum-1) / d);
bucketList.get(num).add(array[i]);
}
//4.对每个通内部进行排序
for(int i = 0; i < bucketList.size(); i++){
//JDK底层采用了归并排序或归并的优化版本
Collections.sort(bucketList.get(i));
}
//5.输出全部元素
double[] sortedArray = new double[array.length];
int index = 0;
for(LinkedList<Double> list : bucketList){
for(double element : list){
sortedArray[index] = element;
index++;
}
}
return sortedArray;
}
public static void main(String[] args) {
double[] array = new double[] {4.12,6.421,0.0023,3.0,2.123,8.122,4.12, 10.09};
double[] sortedArray = bucketSort(array);
System.out.println(Arrays.toString(sortedArray));
}
代码中,所有的桶保存在ArrayList集合当中,每一个桶被定义成一个链表(LinkedList<Double>),这样便于在尾部插入元素。
定位元素属于第几个桶,是按照比例来定位:
(array[i] - min) * (bucketNum-1) / d
同时,代码使用了JDK的集合工具类Collections.sort来为桶内部的元素进行排序。Collections.sort底层采用的是归并排序或Timsort,小伙伴们可以简单地把它们当做是一种时间复杂度 O(nlogn)的排序。


假设原始数列有n个元素,分成m个桶(我们采用的分桶方式 m=n),平均每个桶的元素个数为n/m。
下面我们来逐步分析算法复杂度:
第一步求数列最大最小值,运算量为n。
第二步创建空桶,运算量为m。
第三步遍历原始数列,运算量为n。
第四步在每个桶内部做排序,由于使用了O(nlogn)的排序算法,所以运算量为 n/m * log(n/m ) * m。
第五步输出排序数列,运算量为n。
加起来,总的运算量为 3n+m+ n/m * log(n/m ) * m = 3n+m+n(logn-logm) 。
去掉系数,时间复杂度为:
O(n+m+n(logn-logm))
至于空间复杂度就很明显了:
空桶占用的空间 + 数列在桶中占用的空间 = O(m+n)。





有关计数排序的知识,可以看看这一篇漫画:
- The End -
点击文末阅读全文,看『程序人生』其他精彩文章推荐
「若你有原创文章想与大家分享,欢迎投稿。」
加编辑微信ID,备注#投稿#:
程序 丨 druidlost
小七 丨 duoshangshuang
推荐阅读:
print_r('点个赞吧');
var_dump('点个赞吧');
NSLog(@"点个赞吧!")
System.out.println("点个赞吧!");
console.log("点个赞吧!");
print("点个赞吧!");
printf("点个赞吧!
");
cout << "点个赞吧!" << endl;
Console.WriteLine("点个赞吧!");
fmt.Println("点个赞吧!")
Response.Write("点个赞吧");
alert(’点个赞吧’)以上是关于什么是桶排序,它和希尔排序的区别是什么?的主要内容,如果未能解决你的问题,请参考以下文章