零基础入门CV - 街景字符编码识别 用yolov3和yolov3_tiny教程
Posted 星代码119
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了零基础入门CV - 街景字符编码识别 用yolov3和yolov3_tiny教程相关的知识,希望对你有一定的参考价值。
一、从官方依次下载文件并解压:
对于新手稍微提一下,这个数据集是通过下载下来的链接下载的。直接输入网址,打开既开始下载!.json文件不是下载,是复制。点开链接,创建一个.json文件,复制到里面即可。(我也不知道为啥,反正我下载的时候就这样)

我们会发现训练集为30000张图片,验证集为10000张图片。
注意:(.json文件不是下载,是复制。点开链接,创建一个.json文件,复制到里面即可)
数据集下载好,首先要把.json文件转换为我们所需要的的txt文件。

为了防止图片不连续,这里先生成图片的序号(名称):
代码:
import os
train_file=open('D:\\competition\\mchar_train/train.txt','w')
for _,_,train_files in os.walk('D:/competition/mchar_train/mchar_train'):
continue
i = 0
for file in train_files:
print(file.split('.')[0])
i = i + 1
train_file.write(file.split('.')[0]+'\\n')
print(i)
会在指定文件夹下生成一个train.txt文件
然后运行:
import os
import cv2
import json
def process(dict1,shape,image_path):
annotation = image_path
for i in range(len(dict1['left'])):
xmin = str(int(dict1['left'][i]))
xmax = str(int(dict1['left'][i]+dict1['width'][i]))
ymin = str(int(dict1['top'][i]))
ymax = str(int(dict1['top'][i]+dict1['height'][i]))
annotation += ' ' + ','.join([xmin, ymin, xmax, ymax, str(int(dict1['label'][i]))])
return annotation
#修改相对应的路径即可
f = open(
"D:/competiton/mchar/mchar_train.json",
encoding='utf-8')
data = json.load(f)
with open('D:\\competition\\mchar_train/train.txt', 'r') as f:
txt = f.readlines()
image_inds = [line.strip() for line in txt]
with open('D:/competition/mchar_train//voc_train.txt', 'a') as f:
for i in image_inds:
print('D:/competition/mchar_train/mchar_train'+'/'+i+'.png')
img = cv2.imread(r'D:/competition/mchar_train/mchar_train'+'/'+i+'.png')
shape = img.shape
image_path = 'D:/competition/mchar_train/mchar_train'+'/'+i+'.png'
i = i+'.png'
f.write(process(data[i],shape,image_path)+'\\n')
f.close()
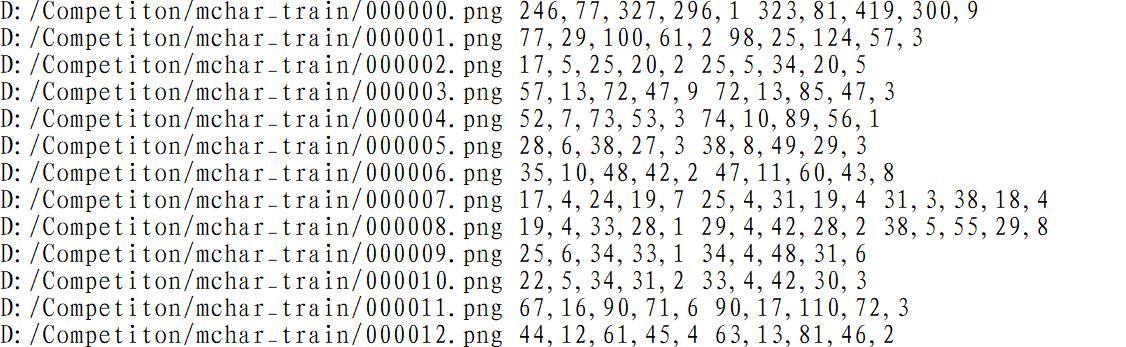
结果如下:
二、训练模型
其实做到这一步就可以了,但是为了新手更好的入门,这里还是把训练过程介绍一下(这里是针对的yolov3_tiny,我实在yolov3的基础上改的,几乎流程一样)。
yolov3代码来源:https://github.com/YunYang1994/tensorflow-yolov3
yolov3_tiny代码来源为:https://download.csdn.net/download/qq_40214464/19159417
在保存的文件夹就会有voc_train.txt,直接复制到dataset文件下:
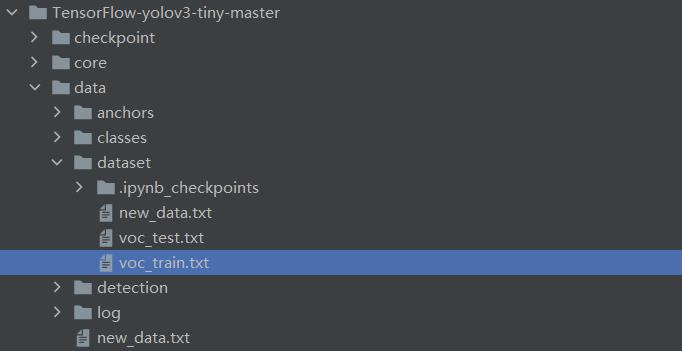
这里是打比赛,按道理应该把val的数据集也转换过来,我觉得没必要,如果真要转换过来,你到不如,直接转换成训练集,一起训练。怎么转换就不说了,如果需要,请在下方留言。其实完全不用测试集的哈。
首先运行 ,获得锚框,由于yolov3_tiny只需要6个锚框,所以选择后6个锚框,复制到tiny
,获得锚框,由于yolov3_tiny只需要6个锚框,所以选择后6个锚框,复制到tiny
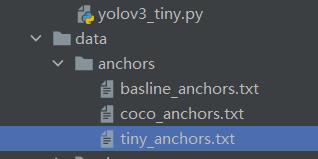
然后把对应的类别改了
点击训练即可!

三、准换为我们需要的.csv文件
代码:
import cv2
import os,glob
import shutil
import numpy as np
import tensorflow as tf
import core.utils as utils
from core.config_tiny import cfg
from core.yolov3_tiny import YOLOV3
import matplotlib.pyplot as plt
import pandas as pd
class YoloTest(object):
def __init__(self):
self.input_size = cfg.TEST.INPUT_SIZE
self.anchor_per_scale = cfg.YOLO.ANCHOR_PER_SCALE
self.classes = utils.read_class_names(cfg.YOLO.CLASSES)
self.num_classes = len(self.classes)
self.anchors = np.array(utils.get_anchors(cfg.YOLO.ANCHORS, is_tiny=True))
self.score_threshold = cfg.TEST.SCORE_THRESHOLD
self.iou_threshold = cfg.TEST.IOU_THRESHOLD
self.moving_ave_decay = cfg.YOLO.MOVING_AVE_DECAY
self.annotation_path = cfg.TEST.ANNOT_PATH
self.weight_file = cfg.TEST.WEIGHT_FILE
self.write_image = cfg.TEST.WRITE_IMAGE
self.write_image_path = cfg.TEST.WRITE_IMAGE_PATH
self.show_label = cfg.TEST.SHOW_LABEL
with tf.name_scope('input'):
self.input_data = tf.placeholder(dtype=tf.float32, name='input_data')
self.trainable = tf.placeholder(dtype=tf.bool, name='trainable')
model = YOLOV3(self.input_data, self.trainable)
self.pred_mbbox, self.pred_lbbox = model.pred_mbbox, model.pred_lbbox
self.saver = tf.train.Saver()
self.sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True))
self.saver.restore(self.sess, self.weight_file)
def predict(self, image_path,df_submit):
imageDir = os.path.abspath(image_path)
# 通过glob.glob来获取第一个文件夹下,所有'.jpg'文件
imageList = glob.glob(os.path.join(imageDir, '*.png'))
imgs_num = len(imageList)
for item in imageList:
image_path = item
image = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR)
image_name = image_path.split("\\\\")[-1]
org_image = np.copy(image)
org_h, org_w, _ = org_image.shape
image_data = utils.image_preporcess(image, [self.input_size, self.input_size])
image_data = image_data[np.newaxis, ...]
pred_mbbox, pred_lbbox = self.sess.run([self.pred_mbbox, self.pred_lbbox],
feed_dict={
self.input_data: image_data,
self.trainable: False
}
)
pred_bbox = np.concatenate([np.reshape(pred_mbbox, (-1, 5 + self.num_classes)),
np.reshape(pred_lbbox, (-1, 5 + self.num_classes))], axis=0)
bboxes = utils.postprocess_boxes(pred_bbox, (org_h, org_w), self.input_size, self.score_threshold)
bboxes = utils.nms(bboxes, self.iou_threshold)
b = np.array(bboxes)
p = []
if b.shape[0]==0:
c = [2]
xin = [2]
else:
c = b[:, 5]
x_min = b[:,1]
num = len(x_min)
for i in range(num):
wh = np.argmin(x_min)
p.append(c[wh])
x_min= np.delete(x_min, [wh])
c = np.delete(c, [wh])
c = np.array(p)
#image = utils.draw_bbox(image, bboxes, show_label=self.show_label)
# plt.imshow(image)
# plt.show()
test_label_pred = []
for x in c:
test_label_pred.append(str(int(x)))
a = '\\t'
i=len(test_label_pred)-1
while i+1:
a = a + test_label_pred[i]
i = i-1
n = []
n.append(a)
df_submit['file_code'] = n
df_submit['file_name'] = image_name
df_submit.to_csv('D:/Competiton/test_A_sample_submit.csv', mode='a',header=False,index=None)
if __name__ == "__main__":
img_dir = "D:/Competiton/mchar_test_a"
df_submit = pd.read_csv('D:/Competiton/test_A_sample_submit.csv')
YoloTest().predict(img_dir ,df_submit)
以上是关于零基础入门CV - 街景字符编码识别 用yolov3和yolov3_tiny教程的主要内容,如果未能解决你的问题,请参考以下文章