Redis架构原理及应用实践
Posted 架构师学习路线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis架构原理及应用实践相关的知识,希望对你有一定的参考价值。
一.Redis简介
Redis 是完全开源免费的,是一个高性能的key-value类型的内存数据库。整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。
Redis的出色之处不仅仅是性能,Redis最大的魅力是支持保存多种数据结构,此外单个value的最大限制是1GB,因此Redis可以用来实现很多有用的功能,比方说用List来做FIFO双向链表,实现一个轻量级的高性 能消息队列服务,用他的Set可以做高性能的tag系统等等。另外Redis也可以对存入的Key-Value设置expire时间。
总结来说,使用Redis的好处如下:
1.速度快,因为数据存在内存中,读的速度是 110000 次 /s, 写的速度是 81000 次 /s;
2.支持丰富数据类型,支持string,list,set,sorted set,hash;
3.支持事务,操作都是原子性,对数据的更改要么全部执行,要么全部不执行,事务中任意命令执行失败,其余命令依然被执行。也就是说 Redis 事务不保证原子性,也不支持回滚;事务中的多条命令被一次性发送给服务器,服务器在执行命令期间,不会去执行其他客户端的命令请求。
4.丰富的特性:可用于缓存,消息(支持 publish/subscribe 通知),按key设置过期时间,过期后将会自动删除,具体淘汰策略有:
4.1.volatile-lru:从已经设置过期时间的数据集中,挑选最近最少使用的数据淘汰
4.2.volatile-ttl:从已经设置过期时间的数据集中,挑选即将要过期的数据淘汰
4.3.volatile-random:从已经设置过期时间的数据集中,随机挑选数据淘汰
4.4.allkeys-lru:从所有的数据集中,挑选最近最少使用的数据淘汰
4.5.allkeys-random:从所有的数据集中,随机挑选数据淘汰
4.6.no-enviction:禁止淘汰数据
具体过期键的策略有:定时删除(缓存过期时间到就删除,创建timer耗CPU),惰性删除(获取的时候检查,不获取一直留在内存,对内存不友好),定期删除(CPU和内存的折中方案)
5.支持数据持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用;
6.支持数据的备份,即 master - slave 模式的数据备份。
Redis的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
二.Redis的数据类型
Redis 支持 5 中数据类型:string(字符串),hash(哈希),list(列表),set(集合),zset(sorted set:有序集合)。
string
string 是 redis 最基本的数据类型。一个 key 对应一个 value。string 是二进制安全的。也就是说 redis 的 string 可以包含任何数据。比如 jpg 图片或者序列化的对象。string 类型是 redis 最基本的数据类型,string 类型的值最大能存储 512 MB。
hash
Redis hash 是一个键值对(key - value)集合。Redis hash 是一个 string 类型的 key 和 value 的映射表,hash 特别适合用于存储对象。并且可以像数据库中一样只对某一项属性值进行存储、读取、修改等操作。
list
Redis 列表是简单的字符串列表,按照插入顺序排序。我们可以网列表的左边或者右边添加元素。list 就是一个简单的字符串集合,和 Java 中的 list 相差不大,区别就是这里的 list 存放的是字符串。list 内的元素是可重复的。可以做消息队列或最新消息排行等功能。
set
redis 的 set 是字符串类型的无序集合。集合是通过哈希表实现的,因此添加、删除、查找的复杂度都是 O(1)。redis 的 set 是一个 key 对应着多个字符串类型的 value,也是一个字符串类型的集合,和 redis 的 list 不同的是 set 中的字符串集合元素不能重复,但是 list 可以。利用唯一性,可以统计访问网站的所有独立 ip。
Zset
redis zset 和 set 一样都是字符串类型元素的集合,并且集合内的元素不能重复。不同的是 zset 每个元素都会关联一个 double 类型的分数。redis 通过分数来为集合中的成员进行从小到大的排序。zset 的元素是唯一的,但是分数(score)却可以重复。可用作排行榜等场景。
三.redis适用场景
1.会话缓存(Session Cache)
最常用的一种使用Redis的情景是会话缓存(session cache)。用Redis缓存会话比其他存储(如Memcached)的优势在于:Redis提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的购物车信息全部丢失,大部分人都会不高兴的。
2.队列
Reids在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得Redis能作为一个很好的消息队列平台来使用。Redis作为队列使用的操作,就类似于本地程序语言(如Python)对 list 的 push/pop 操作。
3.全页缓存
大型互联网公司都会使用Redis作为缓存存储数据,提升页面相应速度。即使重启了Redis实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降。
4.排行榜/计数器
Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单。
四.Redis高可用架构
1.持久化
Redis 是内存型数据库,为了保证数据在断电后不会丢失,需要将内存中的数据持久化到硬盘上。Redis提供了两种持久化的方式,分别是RDB(Redis DataBase)和AOF(Append Only File)。
RDB
简而言之,就是在不同的时间点,将redis存储的数据生成快照并存储到磁盘等介质上,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本。如果系统发生故障,将会丢失最后一次创建快照之后的数据。如果数据量大,保存快照的时间会很长。
AOF
换了一个角度来实现持久化,那就是将redis执行过的所有写指令记录下来,在下次redis重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。将写命令添加到 AOF 文件(append only file)末尾。
使用 AOF 持久化需要设置同步选项,从而确保写命令同步到磁盘文件上的时机。这是因为对文件进行写入并不会马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘。选项同步频率always每个写命令都同步,eyerysec每秒同步一次,no让操作系统来决定何时同步,always 选项会严重减低服务器的性能,everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器几乎没有任何影响。no 选项并不能给服务器性能带来多大的提升,而且会增加系统崩溃时数据丢失的数量。随着服务器写请求的增多,AOF 文件会越来越大。Redis 提供了一种将 AOF 重写的特性,能够去除 AOF 文件中的冗余写命令。
其实RDB和AOF两种方式也可以同时使用,在这种情况下,如果redis重启的话,则会优先采用AOF方式来进行数据恢复,这是因为AOF方式的数据恢复完整度更高。如果你没有数据持久化的需求,也完全可以关闭RDB和AOF方式,这样的话,redis将变成一个纯内存数据库。
2.复制
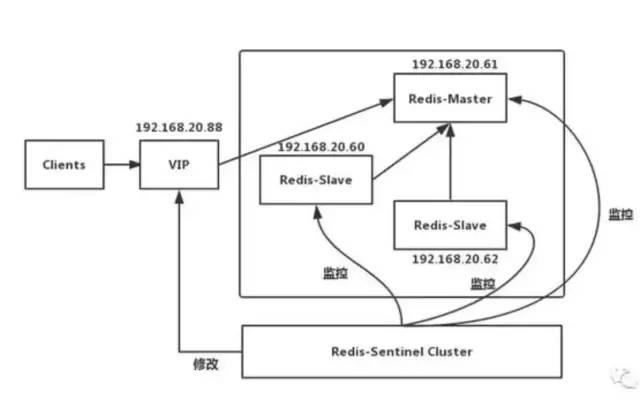
Redis为了解决单点数据库问题,会把数据复制多个副本部署到其他节点上,通过复制,实现Redis的高可用性,实现对数据的冗余备份,保证数据和服务的高度可靠性。Redis有主从和主备两种方式解决单点问题,主备(keepalived)模式下主机备机对外提供同一个虚拟IP,客户端通过虚拟IP进行数据操作,正常期间主机一直对外提供服务,宕机后VIP自动漂移到备机上。主从模式下当Master宕机后,通过选举算法(Paxos、Raft)从slave中选举出新Master继续对外提供服务,主机恢复后以slave的身份重新加入,此模式下可以使用读写分离,如果数据量比较大,不希望过多浪费机器,还希望在宕机后,做一些自定义的措施,比如报警、记日志、数据迁移等操作,推荐使用主从方式,因为和主从搭配的一般还有个管理监控中心(哨兵)。
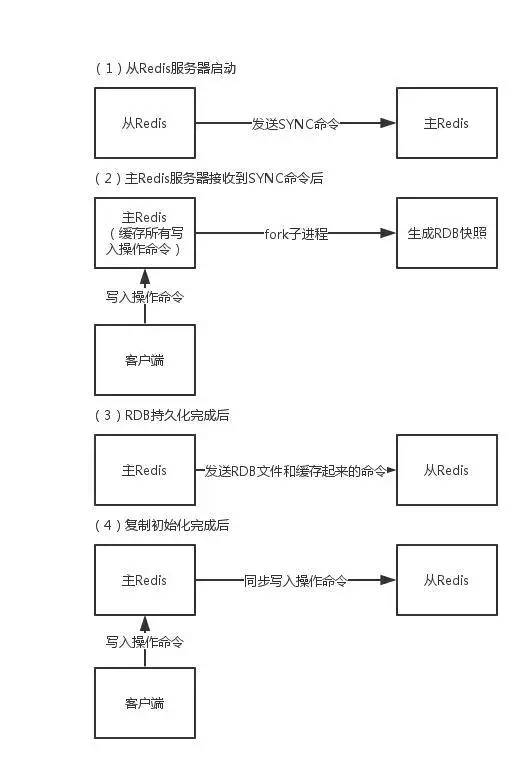
①从数据库向主数据库发送sync(数据同步)命令。
②主数据库接收同步命令后,会保存快照,创建一个RDB文件。
③当主数据库执行完保持快照后,会向从数据库发送RDB文件,而从数据库会接收并载入该文件。
④主数据库将缓冲区的所有写命令发给从服务器执行。
⑤以上处理完之后,之后主数据库每执行一个写命令,都会将被执行的写命令发送给从数据库。可以同步发送也可以异步发送,同步发送可以不用每台都同步,可以配置一台master,一台slave,同时这台salve又作为其他slave的master。异步方式无法保证数据的完整性,比如在异步同步过程中主机突然宕机了,也称这种方式为数据弱一致性。
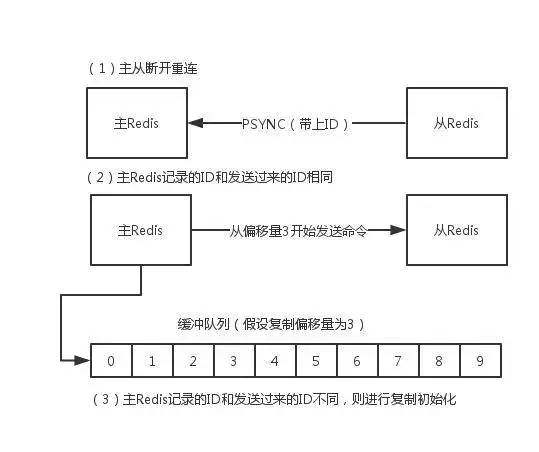
注意:在Redis2.8之后,主从断开重连后会根据断开之前最新的命令偏移量进行增量复制。
3.哨兵
哨兵是Redis集群架构中非常重要的一个组件,哨兵的出现主要是解决了主从复制出现故障时需要人为干预的问题。
1.Redis哨兵主要功能
(1)集群监控:负责监控Redis master和slave进程是否正常工作
(2)消息通知:如果某个Redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员
(3)故障转移:如果master node挂掉了,会自动转移到slave node上
2.Redis哨兵的高可用
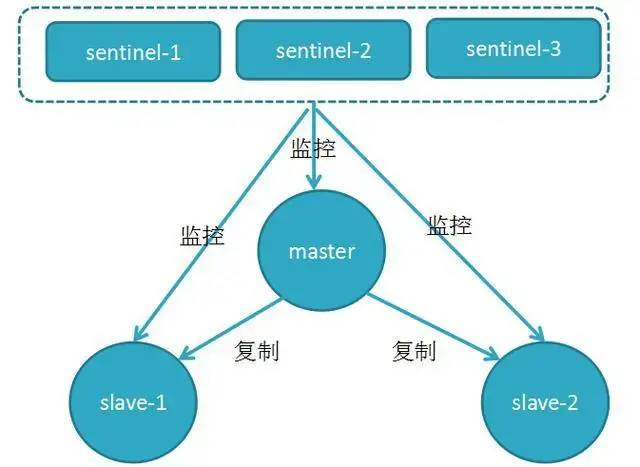
原理:当主节点出现故障时,由Redis Sentinel自动完成故障发现和转移,并通知应用方,实现高可用性。哨兵机制建立了多个哨兵节点(进程),共同监控数据节点的运行状况。同时哨兵节点之间也互相通信,交换对主从节点的监控状况。每隔1秒每个哨兵会向整个集群:Master主服务器+Slave从服务器+其他Sentinel(哨兵)进程,发送一次ping命令做一次心跳检测。这个就是哨兵用来判断节点是否正常的重要依据,涉及两个新的概念:主观下线和客观下线。一个哨兵节点判定主节点down掉是主观下线,只有半数哨兵节点都主观判定主节点down掉,此时多个哨兵节点交换主观判定结果,才会判定主节点客观下线。基本上哪个哨兵节点最先判断出这个主节点客观下线,就会在各个哨兵节点中发起投票机制Raft算法(选举算法),最终被投为领导者的哨兵节点完成主从自动化切换的过程。
4.集群
至少部署两台Redis服务器构成一个小的集群,主要有2个目的:
高可用性:在主机挂掉后,自动故障转移,使前端服务对用户无影响。
读写分离:将主机读压力分流到从机上。
可在客户端组件上实现负载均衡,根据不同服务器的运行情况,分担不同比例的读请求压力。
、
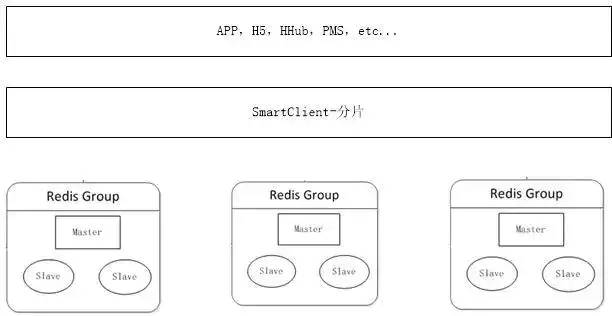
缓存数据量不断增加时,单机内存不够使用,需要把数据切分不同部分,分布到多台服务器上。可在客户端对数据进行分片,数据分片算法详见一致性Hash详解、虚拟桶分片。
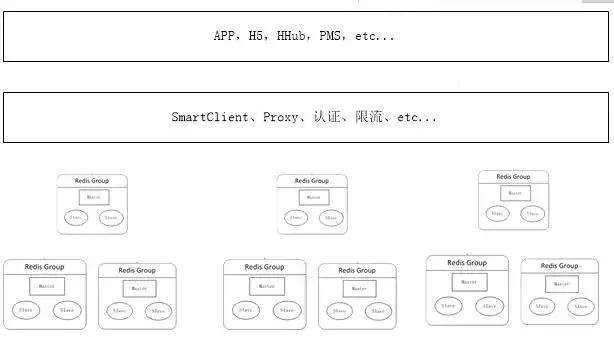
当数据量持续增加时,应用可根据不同场景下的业务申请对应的分布式集群。这块最关键的是缓存治理这块,其中最重要的部分是加入了代理服务(Codis和Twemproxy)。应用通过代理访问真实的Redis服务器进行读写,这样做的好处是避免越来越多的客户端直接访问Redis服务器难以管理,而造成风险,在代理这一层可以做对应的安全措施,比如限流、授权、分片,避免客户端越来越多的逻辑代码,不但臃肿升级还比较麻烦。代理这层无状态的,可任意扩展节点,对于客户端来说,访问代理跟访问单机Redis一样。
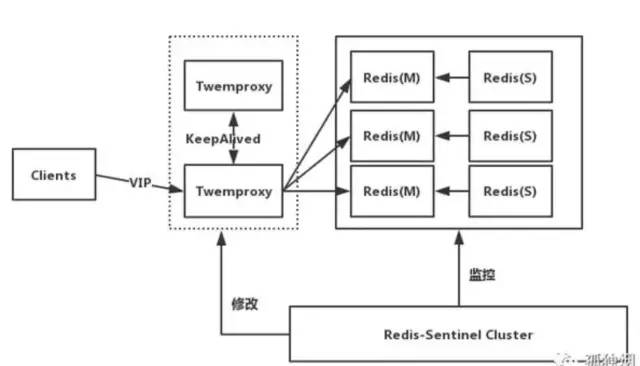
Redis Cluster是Redis官网给出的集群架构
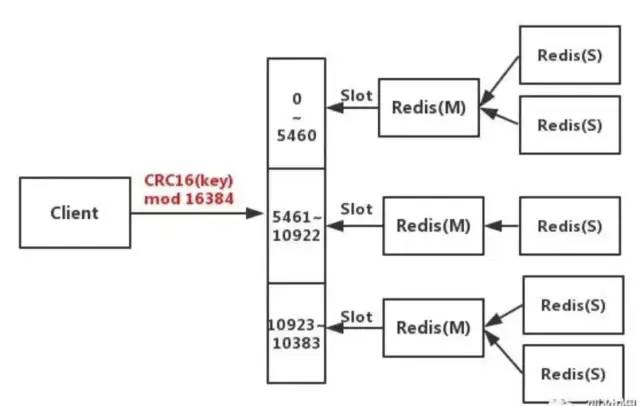
客户端与Redis节点直连,不需要中间Proxy层,直接连接任意一个Master节点,根据公式HASH_SLOT=CRC16(key) mod 16384,计算出映射到哪个分片上,然后Redis会去相应的节点进行操作
具有如下优点:
(1)无需Sentinel哨兵监控,如果Master挂了,Redis Cluster内部自动将Slave切换Master
(2)可以进行水平扩容
(3)支持自动化迁移,当出现某个Slave宕机了,那么就只有Master了,这时候的高可用性就无法很好的保证了,万一Master也宕机了,咋办呢?针对这种情况,如果说其他Master有多余的Slave ,集群自动把多余的Slave迁移到没有Slave的Master 中。
缺点:
(1)批量操作是个坑,不同的key会划分到不同的slot中,因此直接使用mset或者mget等操作是行不通的。如果执行的key数量比较少,就不用mget了,就用串行get操作。如果真的需要执行的key很多,就使用Hashtag保证这些key映射到同一台Redis节点上。
(2)资源隔离性较差,容易出现相互影响的情况。
五.Redis高并发及热key解决之道
1.并发设置key及分布式锁
Redis是一种单线程机制的nosql数据库,基于key-value,数据可持久化落盘。由于单线程所以Redis本身并没有锁的概念,多个客户端连接并不存在竞争关系,但是利用jedis等客户端对Redis进行并发访问时会出现问题。比如多客户端同时并发写一个key,一个key的值是1,本来按顺序修改为2,3,4,最后是4,但是顺序变成了4,3,2,最后变成了2。使用分布式锁防止并发设置Key的原理及代码见:使用Redis实现分布式锁及其优化,另外一种方式是使用消息队列,把并行读写进行串行化。
2.热key问题
热key问题说来也很简单,就是瞬间有几十万的请求去访问redis上某个固定的key,从而压垮缓存服务的情情况。其实生活中也是有不少这样的例子。比如XX明星结婚。那么关于XX明星的Key就会瞬间增大,就会出现热数据问题。那么如何发现热KEY呢:
1.凭借业务经验,进行预估哪些是热key
2.在客户端进行收集
3.在Proxy层做收集
4.用redis自带命令(monitor命令、hotkeys参数)
5.自己抓包评估
解决方案:
1.利用二级缓存,比如利用ehcache,或者一个HashMap都可以。在你发现热key以后,把热key加载到系统的JVM中。
2.备份热key,不要让key走到同一台redis上。我们把这个key,在多个redis上都存一份。可以用HOTKEY加上一个随机数(N,集群分片数)组成一个新key。
3.热点数据尽量不要设置过期时间,在数据变更时同步写缓存,防止高并发下重建缓存的资源损耗。可以用setnx做分布式锁保证只有一个线程在重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可。
3.缓存穿透
缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,但是出于容错的考虑,如果从存储层查不到数据则不写入缓存层。缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。造成缓存穿透的基本有两个。第一,业务自身代码或者数据出现问题,第二,一些恶意攻击、爬虫等造成大量空命中,下面我们来看一下如何解决缓存穿透问题。解决缓存穿透的两种方案:
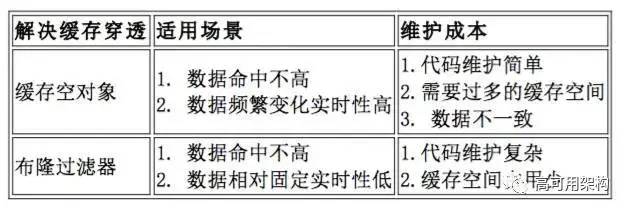
1)缓存空对象
缓存空对象会有两个问题:
第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间 ( 如果是攻击,问题更严重 ),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为 5 分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
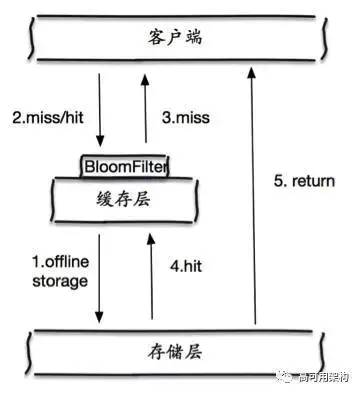
2)布隆过滤器拦截
如下图所示,在访问缓存层和存储层之前,将存在的 key 用布隆过滤器提前保存起来,做第一层拦截。如果布隆过滤器认为该用户 ID 不存在,那么就不会访问存储层,在一定程度保护了存储层。有关布隆过滤器的相关知识,可以参考: 布隆过滤器,可以利用 Redis 的 Bitmaps 实现布隆过滤器,GitHub 上已经开源了类似的方案,读者可以进行参考:redis bitmaps实现布隆过滤器
缓存空对象和布隆过滤器方案对比
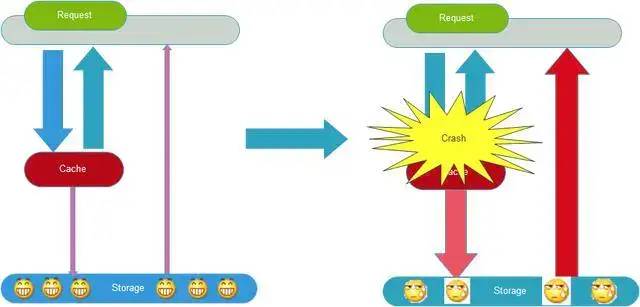
4.缓存雪崩
数据未加载到缓存中,或者缓存同一时间大面积的失效,从而导致所有请求都去查数据库,导致数据库CPU和内存负载过高,甚至宕机。
可以从以下几个方面防止缓存雪崩:
1)保证缓存层服务高可用性
和飞机都有多个引擎一样,如果缓存层设计成高可用的,即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务,例如前面介绍过的 Redis Sentinel 和 Redis Cluster 都实现了高可用。
2)Redis备份和快速预热
Redis备份保证master出问题切换为slave迅速能够承担线上实际流量,快速预热保证缓存及时被写入缓存,防止穿透到库。
3)依赖隔离组件为后端限流并降级
无论是缓存层还是存储层都会有出错的概率,可以将它们视同为资源。作为并发量较大的系统,假如有一个资源不可用,可能会造成线程全部 hang 在这个资源上,造成整个系统不可用。降级在高并发系统中是非常正常的:比如推荐服务中,如果个性化推荐服务不可用,可以降级补充热点数据,不至于造成前端页面是开天窗。
在实际项目中,我们需要对重要的资源 ( 例如 Redis、 mysql、 Hbase、外部接口 ) 都进行隔离,让每种资源都单独运行在自己的线程池中,即使个别资源出现了问题,对其他服务没有影响。但是线程池如何管理,比如如何关闭资源池,开启资源池,资源池阀值管理,这些做起来还是相当复杂的,这里推荐一个 Java 依赖隔离工具Hystrix(https://github.com/Netflix/Hystrix),如下图所示。
4)提前演练
在项目上线前,演练缓存层宕掉后,应用以及后端的负载情况以及可能出现的问题,在此基础上做一些预案设定。
5.缓存预热
缓存预热就是系统上线前,将相关的缓存数据直接加载到缓存系统。这样就可以避免上线后在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
原文:https://www.jianshu.com/p/6c970eb652d5


想要获取学习实战、高并发、架构 、笔试面试资料 请扫码咨询+薇薇微信
以上是关于Redis架构原理及应用实践的主要内容,如果未能解决你的问题,请参考以下文章