玩转pandas取数_下
Posted 尤尔小屋的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了玩转pandas取数_下相关的知识,希望对你有一定的参考价值。
公众号:尤而小屋
作者: Peter
编辑:Peter
大家好,我是Peter~
这将是DataFrame数据筛选的最后一篇文章,重点介绍的是3对函数的使用:
- iloc和loc,最为重要,经常使用的一对函数
- at和iat
- any和all

重要学习资料:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html,pandas官网各种例子带你学习。
扩展阅读
Pandas取数的方法真的是五花八门,有很多的函数和技巧需要我们去掌握和自己平时积累。之前的2篇文章分别是:
模拟数据
本文中模拟了两份数据:
- 第一份的索引为字符类型
- 第二份的索引使用的是默认数值型
import pandas as pd
import numpy as np
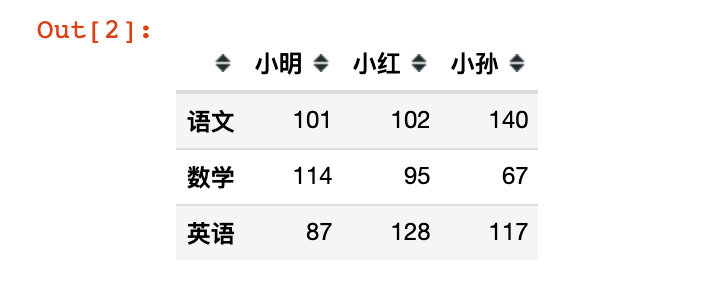
# 第一份模拟数据df0
df0 = pd.DataFrame(
[[101, 102, 140], [114, 95, 67], [87, 128, 117]],
index=['语文', '数学', '英语'],
columns=['小明', '小红',"小孙"])
df0
# 第二份模拟数df
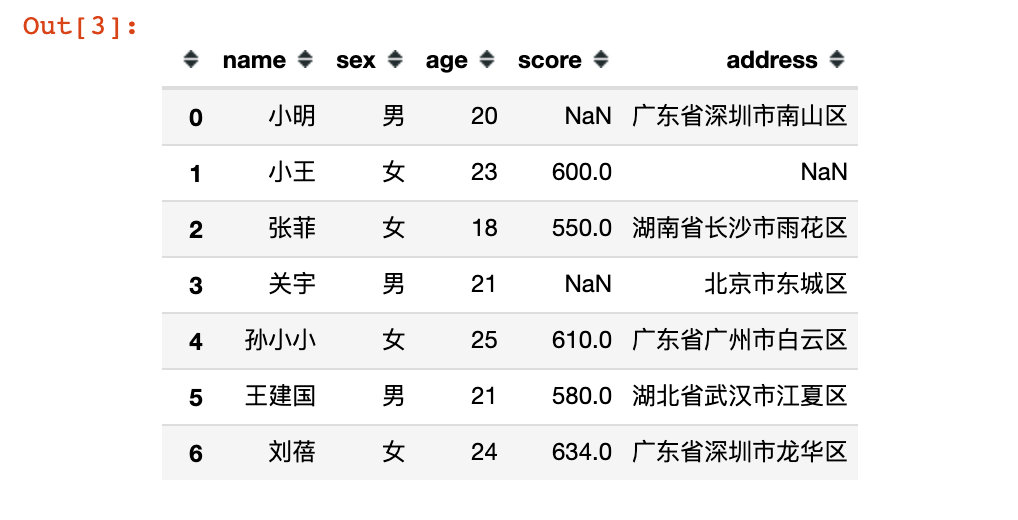
df = pd.DataFrame({
"name":['小明','小王','张菲','关宇','孙小小','王建国','刘蓓'],
"sex":['男','女','女','男','女','男','女'],
"age":[20,23,18,21,25,21,24],
"score":[np.nan,600,550,np.nan,610,580,634], # 缺失两条数据
"address":[
"广东省深圳市南山区",
np.nan, # 数据缺失
"湖南省长沙市雨花区",
"北京市东城区",
"广东省广州市白云区",
"湖北省武汉市江夏区",
"广东省深圳市龙华区"
]
})
df
iloc和loc
iloc是通过数值来进行筛选,loc是通过属性或者行索引名来进行筛选
iloc
直接指定数值,取出单行记录
# 1、使用数值
df1 = df.iloc[1] # 单个数值取出的行记录
df1
# 结果
name 小王
sex 女
age 23
score 600.0
address NaN
Name: 1, dtype: object
使用冒号表示全部
df1 = df.iloc[1,:] # :冒号表示全部
df1
# 结果
name 小王
sex 女
age 23
score 600.0
address NaN
Name: 1, dtype: object
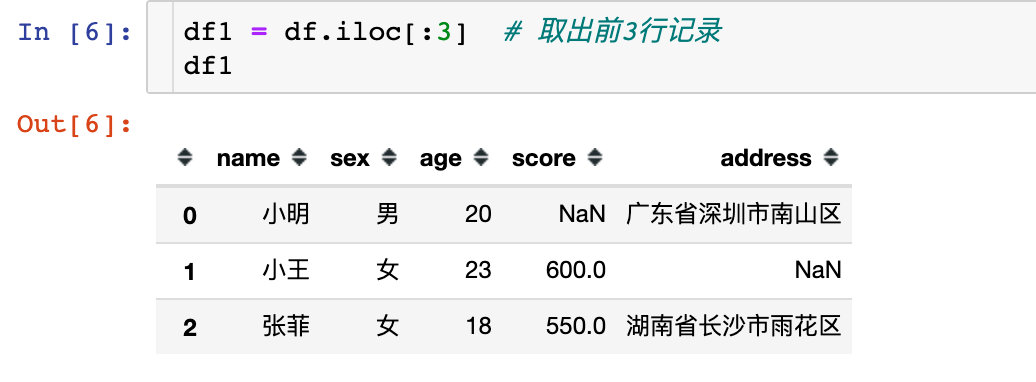
还可以使用切片来取数:
df1 = df.iloc[:3] # 取出前3行记录
df1
取出非连续的多行记录:
df2 = df.iloc[[1,2,4]] # 取出多行记录
df2
| name | sex | age | score | address | |
|---|---|---|---|---|---|
| 1 | 小王 | 女 | 23 | 600.0 | NaN |
| 2 | 张菲 | 女 | 18 | 550.0 | 湖南省长沙市雨花区 |
| 4 | 孙小小 | 女 | 25 | 610.0 | 广东省广州市白云区 |
# 2、取出行记录的部分列属性
df3 = df.iloc[2,0:2]
df3
# 结果
name 张菲
sex 女
Name: 2, dtype: object
# 列方向上使用切片,步长为2
df4 = df.iloc[2,0:5:2]
df4
# 结果
name 张菲
age 18
address 湖南省长沙市雨花区
Name: 2, dtype: object
# 行索引为2,列索引号为1 和 3
df5 = df.iloc[2,[1,3]]
df5
# 结果
sex 女
score 550.0
Name: 2, dtype: object
# 3、取出具体的值
df6 = df.iloc[2,4]
df6
# 结果
'湖南省长沙市雨花区'
在行和列方向上同时使用切片,还可以指定步长:
# 4、行和列方向同时使用切片
df7 = df.iloc[0:4,0:6:2]
df7
和原数据进行对比一下:
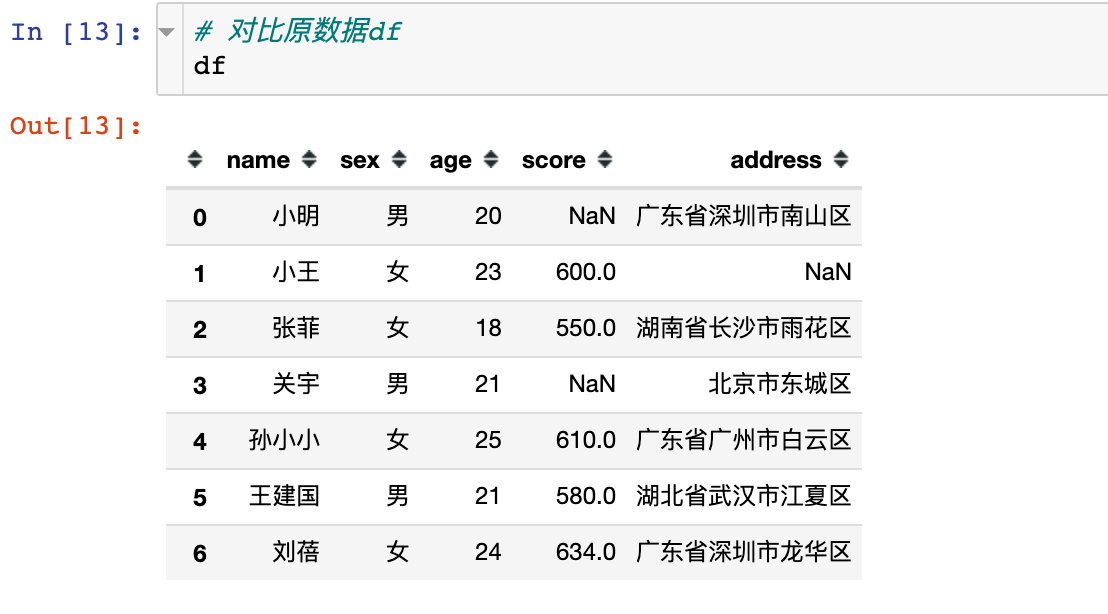
!!!一个非常有用的方法:np.r_,帮助我们取出非连续的列属性
# 5、取出不连续的行列数据,使用np.r_
df8 = df.iloc[:, np.r_[0,2:4]]
df8
| name | age | score | |
|---|---|---|---|
| 0 | 小明 | 20 | NaN |
| 1 | 小王 | 23 | 600.0 |
| 2 | 张菲 | 18 | 550.0 |
| 3 | 关宇 | 21 | NaN |
| 4 | 孙小小 | 25 | 610.0 |
| 5 | 王建国 | 21 | 580.0 |
| 6 | 刘蓓 | 24 | 634.0 |
df9 = df.iloc[np.r_[0,2:4],:]
df9
| name | sex | age | score | address | |
|---|---|---|---|---|---|
| 0 | 小明 | 男 | 20 | NaN | 广东省深圳市南山区 |
| 2 | 张菲 | 女 | 18 | 550.0 | 湖南省长沙市雨花区 |
| 3 | 关宇 | 男 | 21 | NaN | 北京市东城区 |
loc
使用的行索引名或者列属性直接来取数
# 1、取出单个列
df10 = df.loc[:,"name"]
df10
0 小明
1 小王
2 张菲
3 关宇
4 孙小小
5 王建国
6 刘蓓
Name: name, dtype: object
# 2、取数多个列
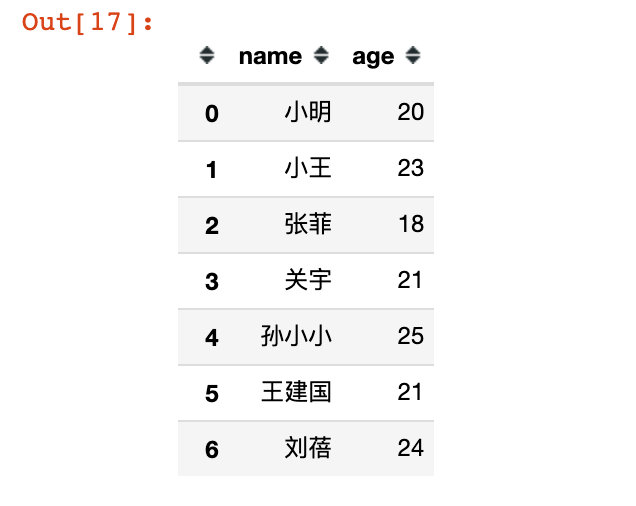
df11 = df.loc[:,["name","age"]]
df11
# 3、使用数值,取出第一行,索引为0
df12 = df.loc[0]
df12
name 小明
sex 男
age 20
score NaN
address 广东省深圳市南山区
Name: 0, dtype: object
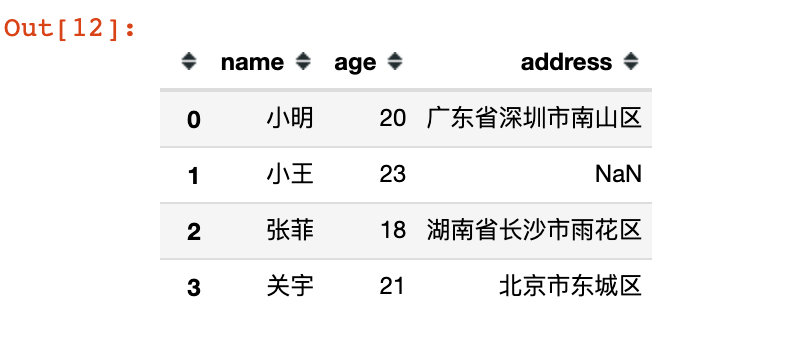
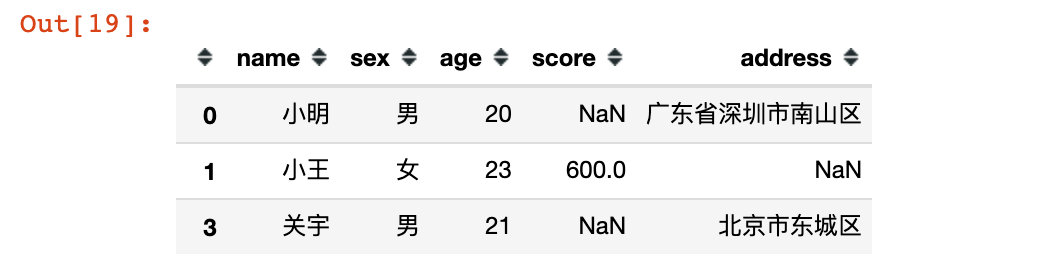
# 4、取出索引为0,1,3的行记录,此时列字段是全部保留
df13 = df.loc[[0,1,3]]
df13
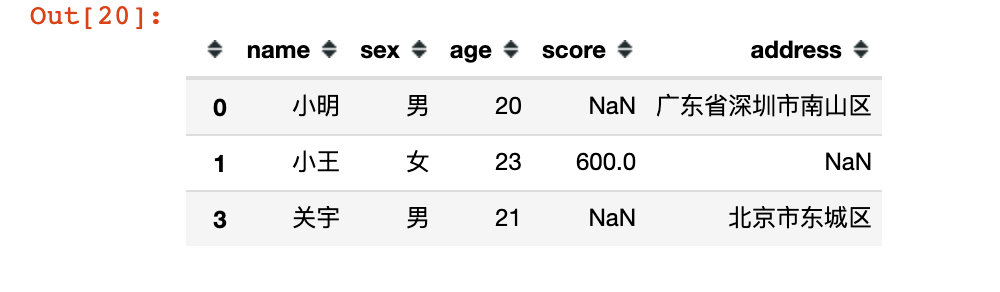
# 使用冒号:,表示全部列,效果同上
df14 = df.loc[[0,1,3],:]
df14
# 5、取出部分行和部分列
df15 = df.loc[[0,1,3],["name","sex","score"]]
df15
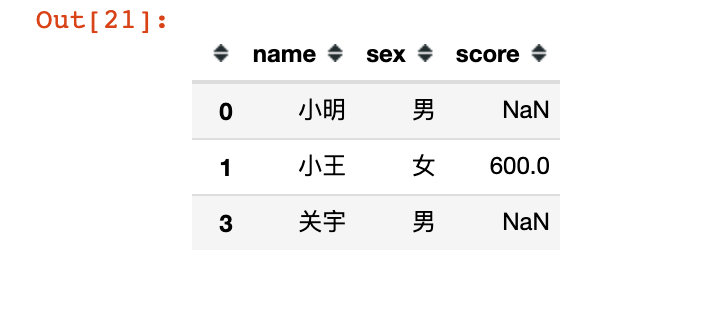
# 6、!!!使用索引切片:同时包含起止位置
df16 = df.loc[0:3]
df16
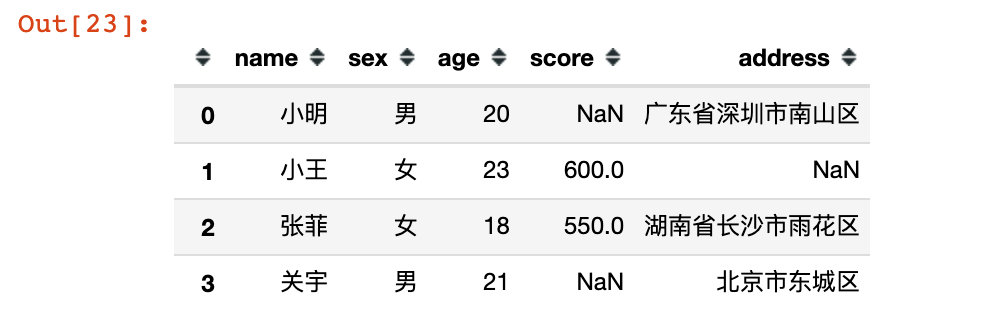
df.loc[:] # 表示所有数据
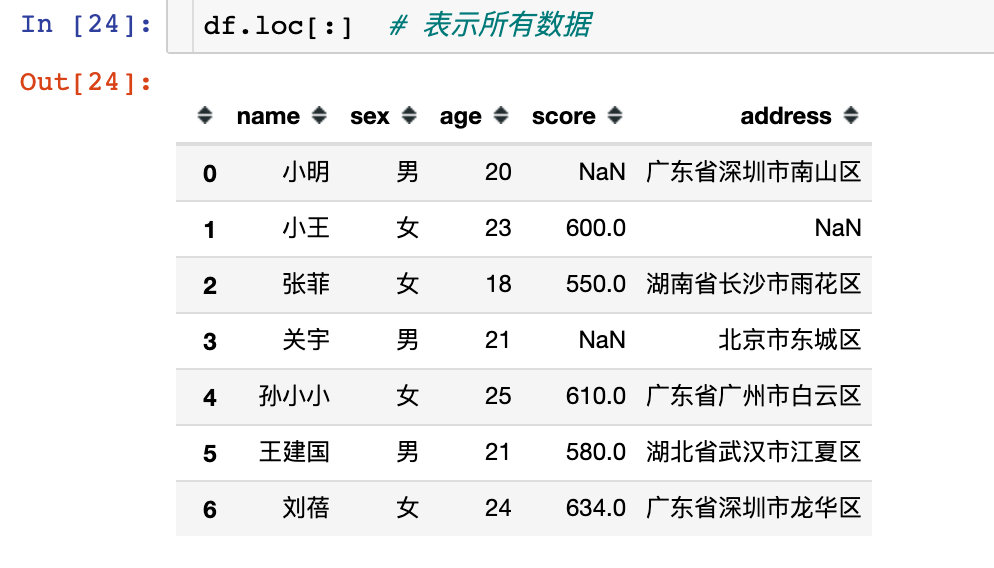
# 7、列筛选的时候,必须有行元素
# 所有行的name和score两列
df17 = df.loc[:,["name","score"]]
df17
| name | score | |
|---|---|---|
| 0 | 小明 | NaN |
| 1 | 小王 | 600.0 |
| 2 | 张菲 | 550.0 |
| 3 | 关宇 | NaN |
| 4 | 孙小小 | 610.0 |
| 5 | 王建国 | 580.0 |
| 6 | 刘蓓 | 634.0 |
# 所有行的age及后面全部列
df18 = df.loc[:,"age":]
df18
| age | score | address | |
|---|---|---|---|
| 0 | 20 | NaN | 广东省深圳市南山区 |
| 1 | 23 | 600.0 | NaN |
| 2 | 18 | 550.0 | 湖南省长沙市雨花区 |
| 3 | 21 | NaN | 北京市东城区 |
| 4 | 25 | 610.0 | 广东省广州市白云区 |
| 5 | 21 | 580.0 | 湖北省武汉市江夏区 |
| 6 | 24 | 634.0 | 广东省深圳市龙华区 |
# 8、部分行,age及其后面的全部列
# 谨记:包含起止位置,这是和python切片不同的地方
df19 = df.loc[1:3,"age":]
df19
| age | score | address | |
|---|---|---|---|
| 1 | 23 | 600.0 | NaN |
| 2 | 18 | 550.0 | 湖南省长沙市雨花区 |
| 3 | 21 | NaN | 北京市东城区 |
# 9、针对非数值型行索引的取数
df20 = df0.loc["语文"]
df20
小明 101
小红 102
小孙 140
Name: 语文, dtype: int64
# 10、注意两个方括号取出的是DataFrame数据,单个括号是Series型数据
df0.loc[["语文"]]
| 小明 | 小红 | 小孙 | |
|---|---|---|---|
| 语文 | 101 | 102 | 140 |
df0.loc[["语文","英语"]]
| 小明 | 小红 | 小孙 | |
|---|---|---|---|
| 语文 | 101 | 102 | 140 |
| 英语 | 87 | 128 | 117 |
# 11、取出部分行和列数据
df21 = df0.loc[["语文","英语"],"小明"]
df21
语文 101
英语 87
Name: 小明, dtype: int64
df0.loc[["语文","英语"],["小明","小孙"]]
| 小明 | 小孙 | |
|---|---|---|
| 语文 | 101 | 140 |
| 英语 | 87 | 117 |
# 12、直接使用行索引名来取数
df0.loc[["语文","英语"]]
| 小明 | 小红 | 小孙 | |
|---|---|---|---|
| 语文 | 101 | 102 | 140 |
| 英语 | 87 | 128 | 117 |
两者对比
df.loc[[1,2]]
| name | sex | age | score | address | |
|---|---|---|---|---|---|
| 1 | 小王 | 女 | 23 | 600.0 | NaN |
| 2 | 张菲 | 女 | 18 | 550.0 | 湖南省长沙市雨花区 |
df.iloc[[1,2]]
| name | sex | age | score | address | |
|---|---|---|---|---|---|
| 1 | 小王 | 女 | 23 | 600.0 | NaN |
| 2 | 张菲 | 女 | 18 | 550.0 | 湖南省长沙市雨花区 |
# 指定我们需要的列属性名
df.loc[[1,2],["name","score"]]
| name | score | |
|---|---|---|
| 1 | 小王 | 600.0 |
| 2 | 张菲 | 550.0 |
# 取出第1和2行,0和3列
df.iloc[[1,2],np.r_[0,3]]
| name | score | |
|---|---|---|
| 1 | 小王 | 600.0 |
| 2 | 张菲 | 550.0 |
at和iat
at
at函数类似于loc,但是at函数取出的仅仅是一个值
df22 = df.at[4,"sex"]
df22
'女'
df.at[2,"name"]
'张菲'
df0
| 小明 | 小红 | 小孙 | |
|---|---|---|---|
| 语文 | 101 | 102 | 140 |
| 数学 | 114 | 95 | 67 |
| 英语 | 87 | 128 | 117 |
# 同时指定索引和列名
df23 = df0.at['语文','小孙']
df23
140
# at、loc连用
df.loc[1].at['age']
23
df
| name | sex | age | score | address | |
|---|---|---|---|---|---|
| 0 | 小明 | 男 | 20 | NaN | 广东省深圳市南山区 |
| 1 | 小王 | 女 | 23 | 600.0 | NaN |
| 2 | 张菲 | 女 | 18 | 550.0 | 湖南省长沙市雨花区 |
| 3 | 关宇 | 男 | 21 | NaN | 北京市东城区 |
| 4 | 孙小小 | 女 | 25 | 610.0 | 广东省广州市白云区 |
| 5 | 王建国 | 男 | 21 | 580.0 | 湖北省武汉市江夏区 |
| 6 | 刘蓓 | 女 | 24 | 634.0 | 广东省深圳市龙华区 |
# 列名为name的第4个元素
df.name.at[4]
'孙小小'
iat
和iloc一样,仅仅支持对数字索引操作
df24 = df.iat[2,4]
df24
'湖南省长沙市雨花区'
df.loc[2].iat[4]
'湖南省长沙市雨花区'
df.iloc[2].iat[4]
'湖南省长沙市雨花区'
any和all
- any:如果至少有一个为True,则为True
- all:需要所有结果为True,才会为True
当传入的axis=1,会按照行进行查询;axis=0表示按照列查询
在Series数据的比较
# 两个False通过any结果为False
pd.Series([False, False]).any() # False
pd.Series([True, False]).any() # True
pd.Series([True, False]).all() # False
# any:是否跳过空值
pd.Series([np.nan]).any() # False
pd.Series([np.nan]).any(skipna=False) # True
# all:是否跳过空值
pd.Series([np.nan]).all() # True
pd.Series([np.nan]).all(skipna=False) #True
在DataFrame的比较
df0
| 小明 | 小红 | 小孙 | |
|---|---|---|---|
| 语文 | 101 | 102 | 140 |
| 数学 | 114 | 95 | 67 |
| 英语 | 87 | 128 | 117 |
# 1、取出待查询的数据
df0.loc[:,["小明","小红"]]
| 小明 | 小红 | |
|---|---|---|
| 语文 | 101 | 102 |
| 数学 | 114 | 95 |
| 英语 | 87 | 128 |
# 2、进行比较
df0.loc[:,["小明","小红"]] >= 100
| 小明 | 小红 | |
|---|---|---|
| 语文 | True | True |
| 数学 | True | False |
| 英语 | False | True |
any
# 3、使用any函数筛选
df0[(df0.loc[:,["小明","小红"]] >= 100).any(1)]
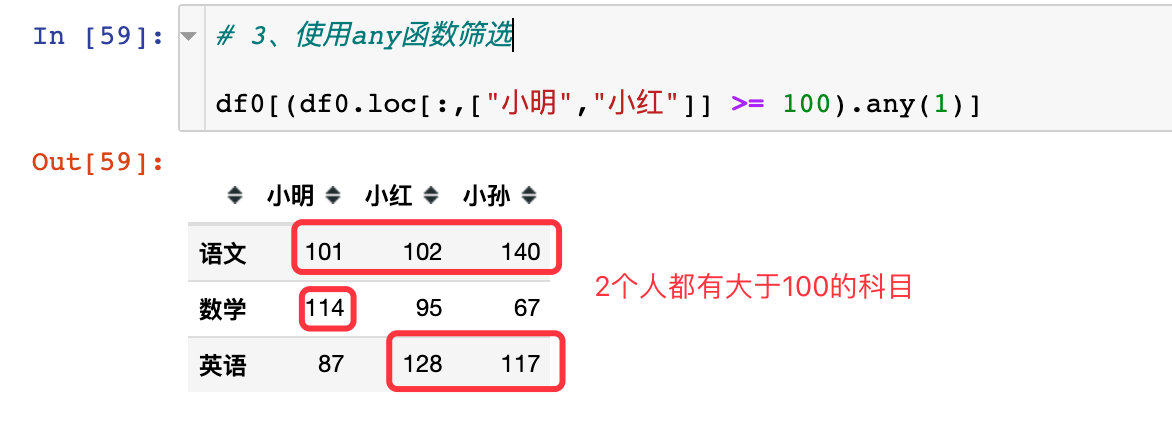
all
只有语文同时满足3个人都大于100
# 4、使用all函数筛选:只有语文满足3个人同时大于100
df0[(df0.loc[:,["小明","小红"]] >= 100).all(1)]

总结
本文通过模拟的数据介绍了pandas的3对函数使用。其中loc和iloc函数是十分常用和实用的函数,自己经常会使用。至此,pandas的数据筛选部分已经全部介绍完成。
当然介绍的方法只是pandas丰富取数技巧中的部分,还有很多的函数和方法需要读者自己平时去学习和积累,希望介绍的方法对大家有所帮助。
从下一篇文章开始,将会介绍Pandas中的各种操作技巧。
以上是关于玩转pandas取数_下的主要内容,如果未能解决你的问题,请参考以下文章