Elasticsearch玩转 Elasticsearch 7.8 的 SQL 功能
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch玩转 Elasticsearch 7.8 的 SQL 功能相关的知识,希望对你有一定的参考价值。

1.概述
转载并且补充:https://elasticsearch.cn/article/687‘
2.实战
2.1 构建数据
首先,我们创建一条数据:
POST twitter/doc/
{
"name":"medcl",
"twitter":"sql is awesome",
"date":"2018-07-27",
"id":123
}
2.2 RESTful下调用SQL
在 ES 里面执行 SQL 语句,有三种方式,第一种是 RESTful 方式,第二种是 SQL-CLI 命令行工具,第三种是通过 JDBC 来连接 ES,执行的 SQL 语句其实都一样,我们先以 RESTful 方式来说明用法。
RESTful 的语法如下:
POST /_xpack/sql?format=txt
{
"query": "SELECT * FROM twitter"
}
因为 SQL 特性是 xpack 的免费功能,所以是在 _xpack 这个路径下面,我们只需要把 SQL 语句传给 query 字段就行了,注意最后面不要加上 ; 结尾,注意是不要!
我们执行上面的语句,查询返回的结果如下:
date | id | name | twitter
------------------------+---------------+---------------+---------------
2018-07-27T00:00:00.000Z|123 |medcl |sql is awesome
ES 俨然已经变成 SQL 数据库了,我们再看看如何获取所有的索引列表:
POST /_xpack/sql?format=txt
{
"query": "SHOW tables"
}
返回如下:
name | type
---------------------------------+---------------
.kibana |BASE TABLE
.monitoring-alerts-6 |BASE TABLE
.monitoring-es-6-2018.06.21 |BASE TABLE
.monitoring-es-6-2018.06.26 |BASE TABLE
.monitoring-es-6-2018.06.27 |BASE TABLE
.monitoring-kibana-6-2018.06.21 |BASE TABLE
.monitoring-kibana-6-2018.06.26 |BASE TABLE
.monitoring-kibana-6-2018.06.27 |BASE TABLE
.monitoring-logstash-6-2018.06.20|BASE TABLE
.reporting-2018.06.24 |BASE TABLE
.triggered_watches |BASE TABLE
.watcher-history-7-2018.06.20 |BASE TABLE
.watcher-history-7-2018.06.21 |BASE TABLE
.watcher-history-7-2018.06.26 |BASE TABLE
.watcher-history-7-2018.06.27 |BASE TABLE
.watches |BASE TABLE
apache_elastic_example |BASE TABLE
forum-mysql |BASE TABLE
twitter
有点多,我们可以按名称过滤,如 twitt 开头的索引,注意通配符只支持 %和 _,分别表示多个和单个字符(什么,不记得了,回去翻数据库的书去!):
POST /_xpack/sql?format=txt
{
"query": "SHOW TABLES like 'twit%'"
}
POST /_xpack/sql?format=txt
{
"query": "SHOW TABLES like 'twitte_'"
}
上面返回的结果都是:
name | type
---------------+---------------
twitter |BASE TABLE
如果不加like会报错:【Elasticsearch】es SQL no_viable_alt_exception line 1:15: no viable alternative at input
如果要查看该索引的字段和元数据,如下:
POST /_xpack/sql?format=txt
{
"query": "DESC twitter"
}
返回:
column | type
---------------+---------------
date |TIMESTAMP
id |BIGINT
name |VARCHAR
name.keyword |VARCHAR
twitter |VARCHAR
twitter.keyword|VARCHAR
都是动态生成的字段,包含了 .keyword 字段。 还能使用下面的命令来查看,主要是兼容 SQL 语法。
POST /_xpack/sql?format=txt
{
"query": "SHOW COLUMNS IN twitter"
}
column | type | mapping
---------------+---------------+---------------
date |TIMESTAMP |datetime
id |BIGINT |long
name |VARCHAR |text
name.keyword |VARCHAR |keyword
twitter |VARCHAR |text
twitter.keyword|VARCHAR |keyword
另外,如果不记得 ES 支持哪些函数,只需要执行下面的命令,即可得到完整列表:
SHOW FUNCTIONS
返回结果如下,也就是当前6.3版本支持的所有函数,如下:
name | type
----------------+---------------
AVG |AGGREGATE
COUNT |AGGREGATE
MAX |AGGREGATE
MIN |AGGREGATE
SUM |AGGREGATE
STDDEV_POP |AGGREGATE
VAR_POP |AGGREGATE
PERCENTILE |AGGREGATE
PERCENTILE_RANK |AGGREGATE
SUM_OF_SQUARES |AGGREGATE
SKEWNESS |AGGREGATE
KURTOSIS |AGGREGATE
DAY_OF_MONTH |SCALAR
DAY |SCALAR
DOM |SCALAR
DAY_OF_WEEK |SCALAR
DOW |SCALAR
DAY_OF_YEAR |SCALAR
DOY |SCALAR
HOUR_OF_DAY |SCALAR
HOUR |SCALAR
MINUTE_OF_DAY |SCALAR
MINUTE_OF_HOUR |SCALAR
MINUTE |SCALAR
SECOND_OF_MINUTE|SCALAR
SECOND |SCALAR
MONTH_OF_YEAR |SCALAR
MONTH |SCALAR
YEAR |SCALAR
WEEK_OF_YEAR |SCALAR
WEEK |SCALAR
ABS |SCALAR
ACOS |SCALAR
ASIN |SCALAR
ATAN |SCALAR
ATAN2 |SCALAR
CBRT |SCALAR
CEIL |SCALAR
CEILING |SCALAR
COS |SCALAR
COSH |SCALAR
COT |SCALAR
DEGREES |SCALAR
E |SCALAR
EXP |SCALAR
EXPM1 |SCALAR
FLOOR |SCALAR
LOG |SCALAR
LOG10 |SCALAR
MOD |SCALAR
PI |SCALAR
POWER |SCALAR
RADIANS |SCALAR
RANDOM |SCALAR
RAND |SCALAR
ROUND |SCALAR
SIGN |SCALAR
SIGNUM |SCALAR
SIN |SCALAR
SINH |SCALAR
SQRT |SCALAR
TAN |SCALAR
SCORE |SCORE
同样支持通配符进行过滤:
POST /_xpack/sql?format=txt
{
"query": "SHOW FUNCTIONS like 'S__'"
}
结果:
name | type
---------------+---------------
SUM |AGGREGATE
SIN |SCALAR
那如果要进行模糊搜索呢,Elasticsearch 的搜索能力大家都知道,强!在 SQL 里面,可以用 match 关键字来写,如下:
POST /_xpack/sql?format=txt
{
"query": "SELECT SCORE(), * FROM twitter WHERE match(twitter, 'sql is') ORDER BY id DESC"
}
SCORE() | date | id | name | twitter
---------------+------------------------+---------------+---------------+---------------
0.5753642 |2018-07-27T00:00:00.000Z|123 |medcl |sql is awesome
最后,还能试试 SELECT 里面的一些其他操作,如过滤,别名,如下:
POST /_xpack/sql?format=txt
{
"query": "SELECT SCORE() as score,name as myname FROM twitter as mytable where name = 'medcl' OR name ='elastic' limit 5"
}
结果如下:
score | myname
---------------+---------------
0.2876821 |medcl
或是分组和函数计算:
POST /_xpack/sql?format=txt
{
"query": "SELECT name,max(id) as max_id FROM twitter as mytable group by name limit 5"
}
结果如下:
name | max_id
---------------+---------------
medcl |123.0
2.2.11 转换
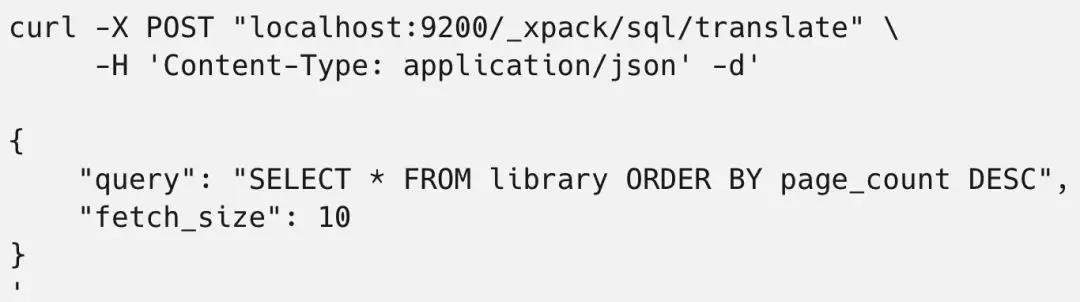
可以转换成如下

SQL-CLI下的使用
上面的例子基本上把 SQL 的基本命令都介绍了一遍,很多情况下,用 RESTful 可能不是很方便,那么可以试试用 CLI 命令行工具来执行 SQL 语句,妥妥的 SQL 操作体验。
切换到命令行下,启动 cli 程序即可进入命令行交互提示界面,如下:
[lcc@lcc ~/soft/es/elasticsearch-7.8.0]$ ./bin/elasticsearch-sql-cli
future versions of Elasticsearch will require Java 11; your Java version from [/Library/Java/JavaVirtualMachines/jdk1.8.0_241.jdk/Contents/Home/jre] does not meet this requirement
asticElasticE
ElasticE sticEla
sticEl ticEl Elast
lasti Elasti tic
cEl ast icE
icE as cEl
icE as cEl
icEla las El
sticElasticElast icElas
las last ticElast
El asti asti stic
El asticEla Elas icE
El Elas cElasticE ticEl cE
Ela ticEl ticElasti cE
las astic last icE
sticElas asti stic
icEl sticElasticElast
icE sticE ticEla
icE sti cEla
icEl sti Ela
cEl sti cEl
Ela astic ticE
asti ElasticElasti
ticElasti lasticElas
ElasticElast
SQL
7.8.0
sql>
当你看到一个硕大的ES,表示 SQL 命令行已经准备就绪了,查看一下索引列表,不,数据表的列表:
sql> show tables;
name | type | kind
------------------------------+---------------+---------------
.apm-agent-configuration |TABLE |INDEX
.apm-custom-link |TABLE |INDEX
.async-search |TABLE |INDEX
.kibana |VIEW |ALIAS
.kibana-event-log-7.8.0 |VIEW |ALIAS
.kibana-event-log-7.8.0-000001|TABLE |INDEX
各种操作妥妥的,上面已经测试过的命令就不在这里重复了,只是体验不一样罢了。
如果要连接远程的 ES 服务器,只需要启动命令行工具的时候,指定服务器地址,如果有加密,指定 keystone 文件,完整的帮助如下:
[lcc@lcc ~/soft/es/elasticsearch-7.8.0]$ ./bin/elasticsearch-sql-cli --help
future versions of Elasticsearch will require Java 11; your Java version from [/Library/Java/JavaVirtualMachines/jdk1.8.0_241.jdk/Contents/Home/jre] does not meet this requirement
Elasticsearch SQL CLI
Non-option arguments:
uri
Option Description
------ -----------
-b, --binary <Boolean> Disable binary communication. Enabled by default.
Accepts 'true' or 'false' values. (default: true)
-c, --check <Boolean> Enable initial connection check on startup (default:
true)
-d, --debug Enable debug logging
-h, --help Show help
-k, --keystore_location Location of a keystore to use when setting up SSL. If
specified then the CLI will prompt for a keystore
password. If specified when the uri isn't https then
an error is thrown.
-s, --silent Show minimal output
-v, --verbose Show verbose output
JDBC 对接
JDBC 对接的能力,让我们可以与各个 SQL 生态系统打通,利用众多现成的基于 SQL 之上的工具来使用 Elasticsearch,我们以一个工具来举例。
和其他数据库一样,要使用 JDBC,要下载该数据库的 JDBC 的驱动,我们打开: https://www.elastic.co/downloads/jdbc-client
只有一个 zip 包下载链接,下载即可。
然后,我们这里使用 DbVisualizer 来连接 ES 进行操作,这是一个数据库的操作和分析工具,DbVisualizer 下载地址是:https://www.dbvis.com/。
下载安装启动之后的程序主界面如下图:
我们如果要使用 ES 作为数据源,我们第一件事需要把 ES 的 JDBC 驱动添加到 DbVisualizer 的已知驱动里面。我们打开 DbVisualizer 的菜单【Tools】-> 【Driver Manager】,打开如下设置窗口:
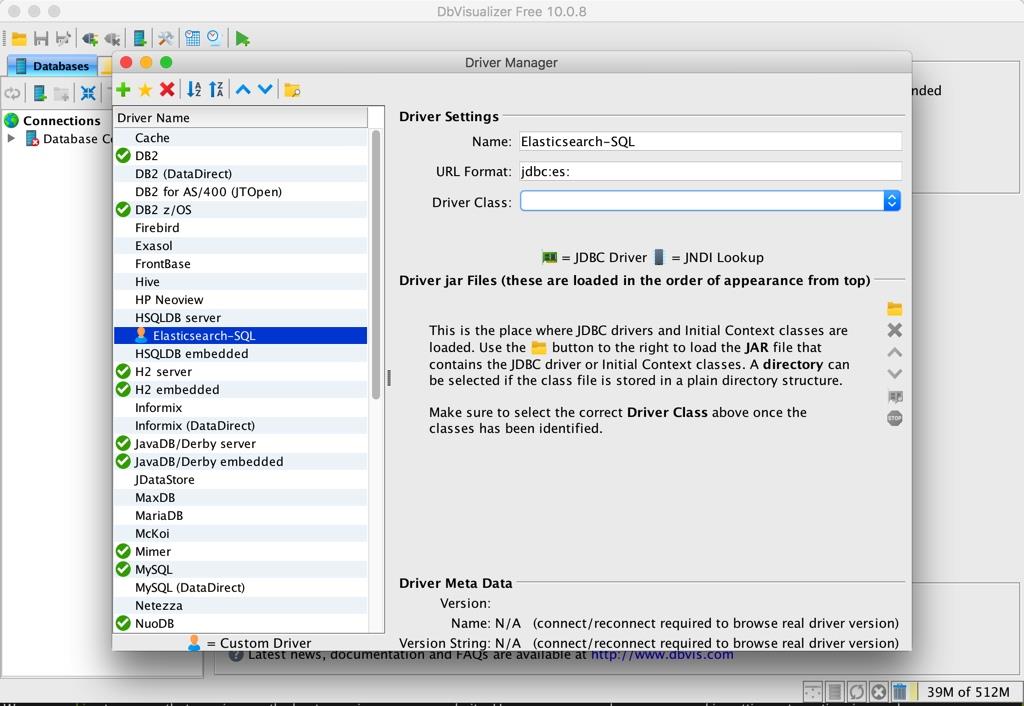
点击绿色的加号按钮,新增一个名为 Elasticsearch-SQL 的驱动,url format 设置成 jdbc🇪🇸,如下图:
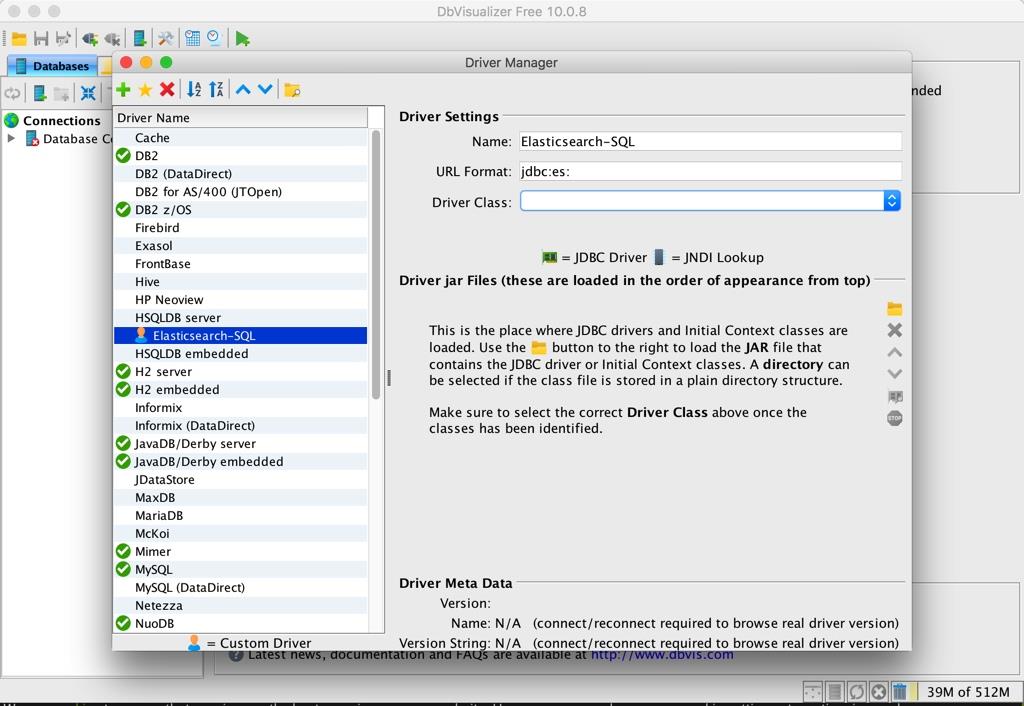
然后点击上图黄色的文件夹按钮,添加我们刚刚下载好且解压之后的所有 jar 文件,如下:
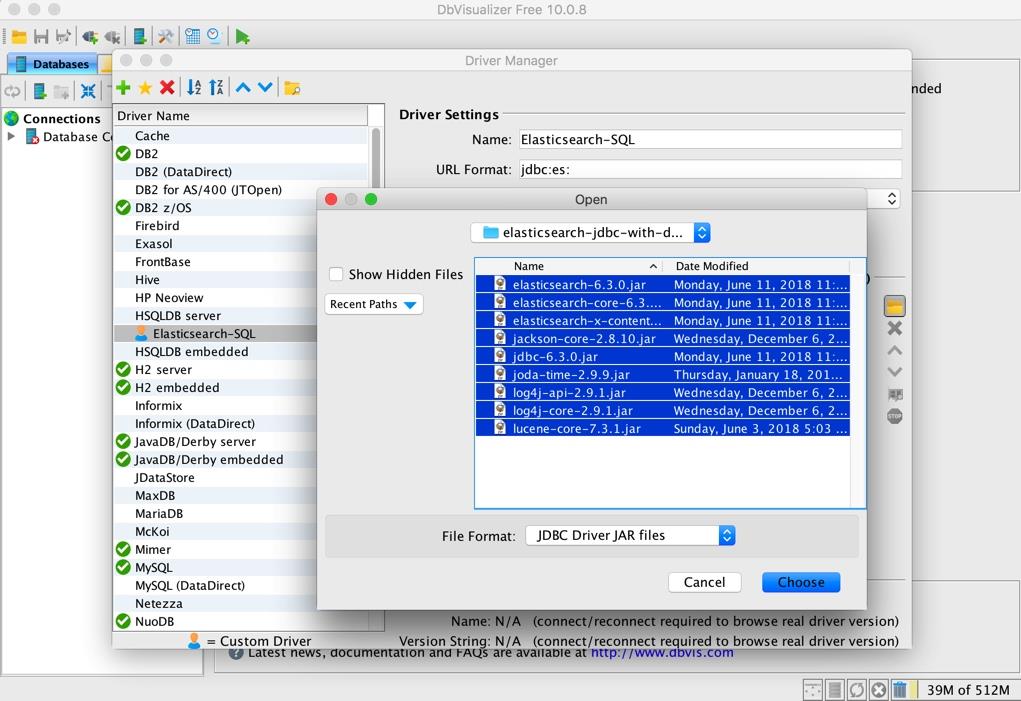
添加完成之后,如下图:
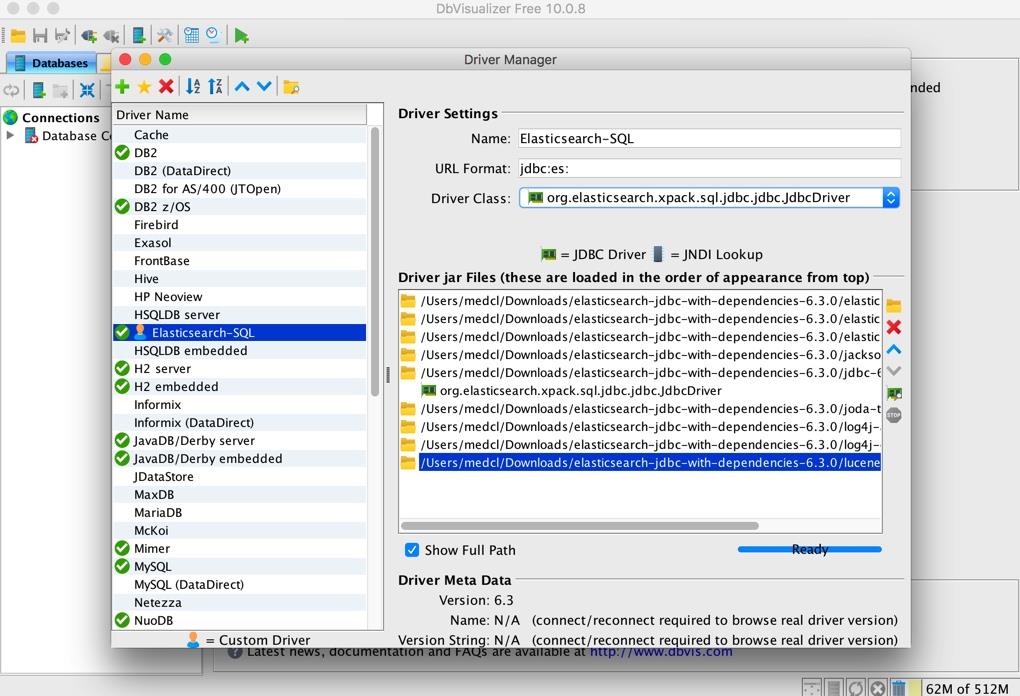
就可以关闭这个 JDBC 驱动的管理窗口了。下面我们来连接到 ES 数据库。
选择主程序左侧的新建连接图标,打开向导,如下:
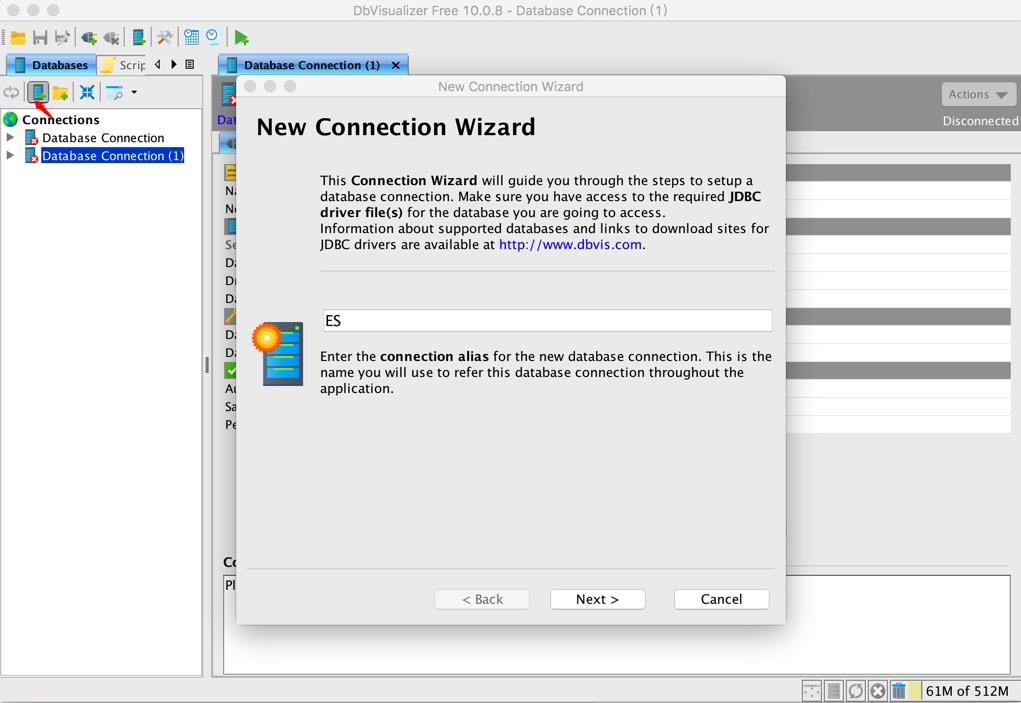
选择刚刚加入的 Elasticsearch-SQL 驱动:
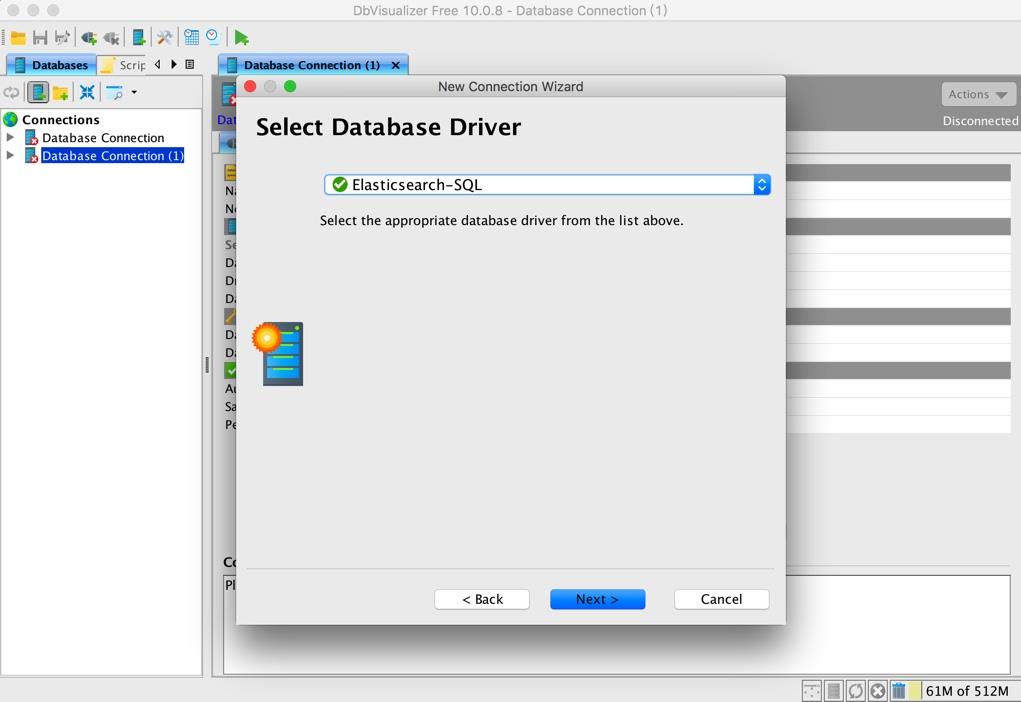
设置连接字符串,此处没有登录信息,如果有可以对应的填上:
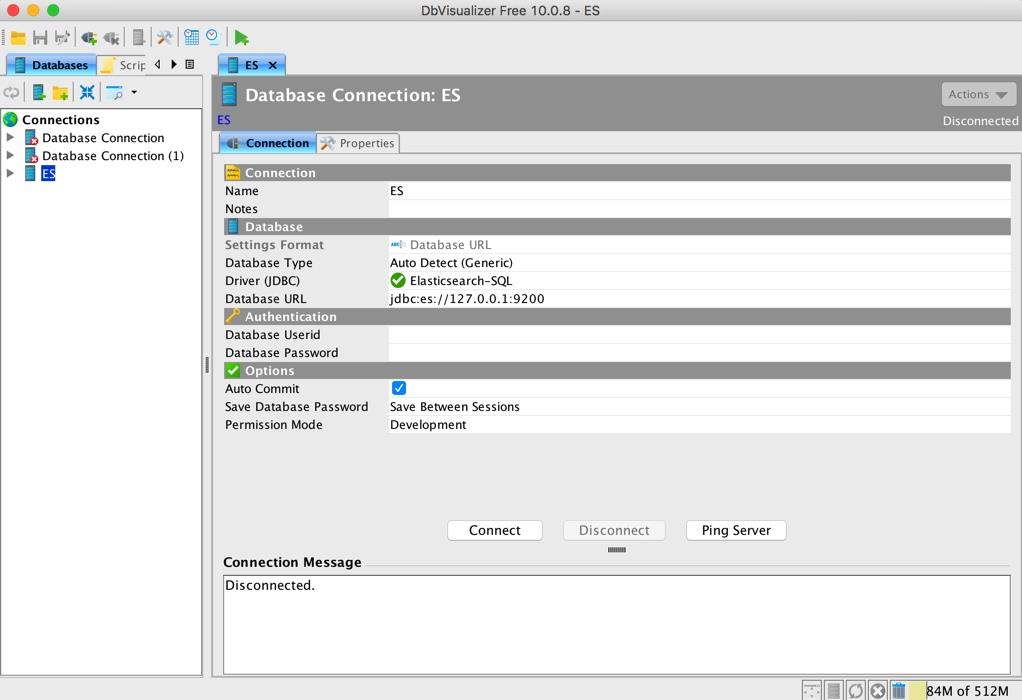
点击 Connect,即可连接到 ES,左侧导航可以展开看到对应的 ES 索引信息:
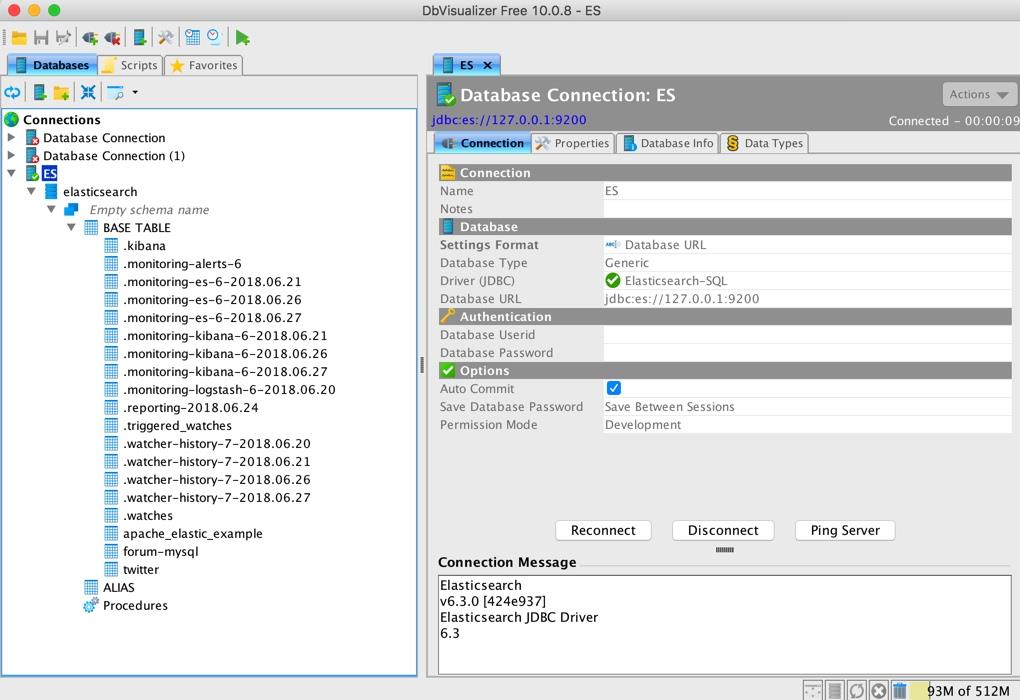
同样可以查看相应的库表结果和具体的数据:
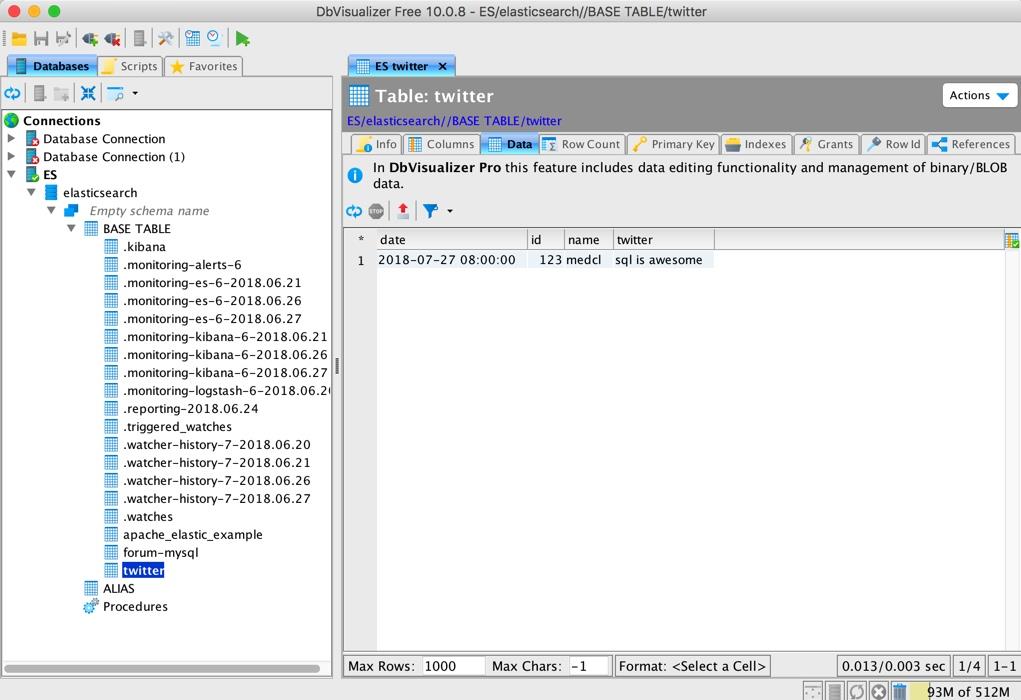
用他自带的工具执行 SQL 也是不在话下:
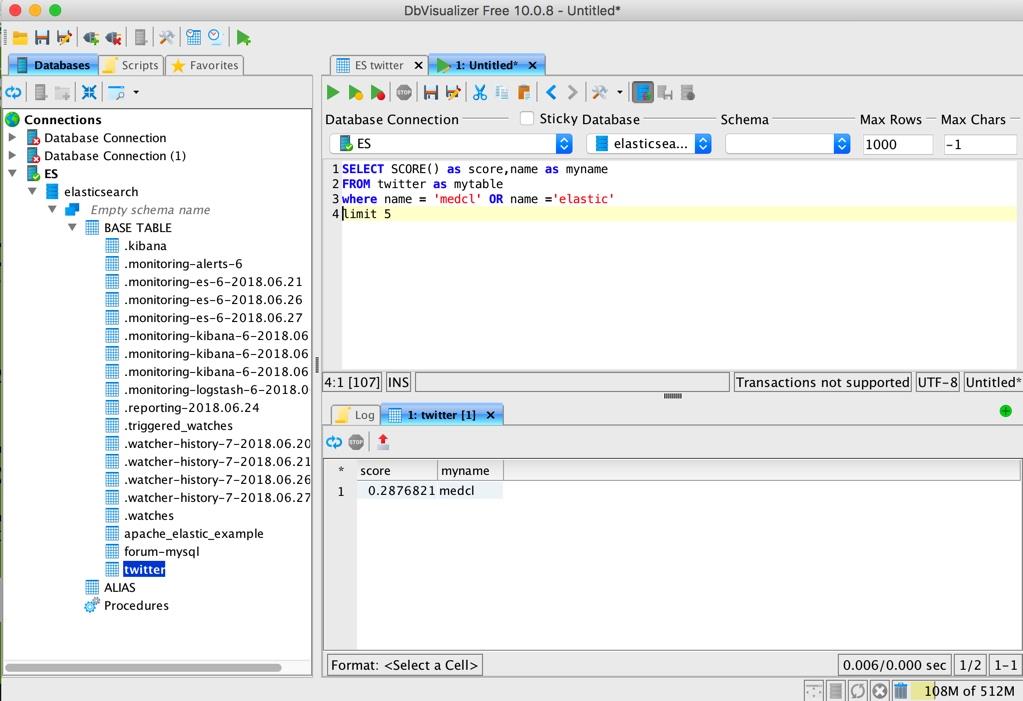
同理,各种 ETL 工具和基于 SQL 的 BI 和可视化分析工具都能把 Elasticsearch 当做 SQL 数据库来连接获取数据了。
最后一个小贴士,如果你的索引名称包含横线,如 logstash-201811,只需要做一个用双引号包含,对双引号进行转义即可,如下:
POST /_xpack/sql?format=txt
{
"query":"SELECT COUNT(*) FROM \\"logstash-*\\""
}
关于 SQL 操作的文档在这里:
https://www.elastic.co/guide/en/elasticsearch/reference/current/sql-jdbc.html
以上是关于Elasticsearch玩转 Elasticsearch 7.8 的 SQL 功能的主要内容,如果未能解决你的问题,请参考以下文章