面试官:你是如何诊断Kafka消息发送到瓶颈在哪里(有的放矢才是性能优化的正确打开方式)
Posted 中间件兴趣圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官:你是如何诊断Kafka消息发送到瓶颈在哪里(有的放矢才是性能优化的正确打开方式)相关的知识,希望对你有一定的参考价值。
掌握一到两门java主流中间件,是敲开BAT等大厂必备的技能,送给大家一个Java中间件学习路线,助力大家实现职场的蜕变。
在消息发送端遇到性能瓶颈时是否有办法正确的评估瓶颈在哪呢?如何针对性的进行调优呢?
1、Kafka 消息发送端监控指标
其实Kafka早就为我们考虑好了,Kafka提供了丰富的监控指标,并提供了JMX的方式来获取这些监控指标,在客户端提供的监控指标如下图所示:
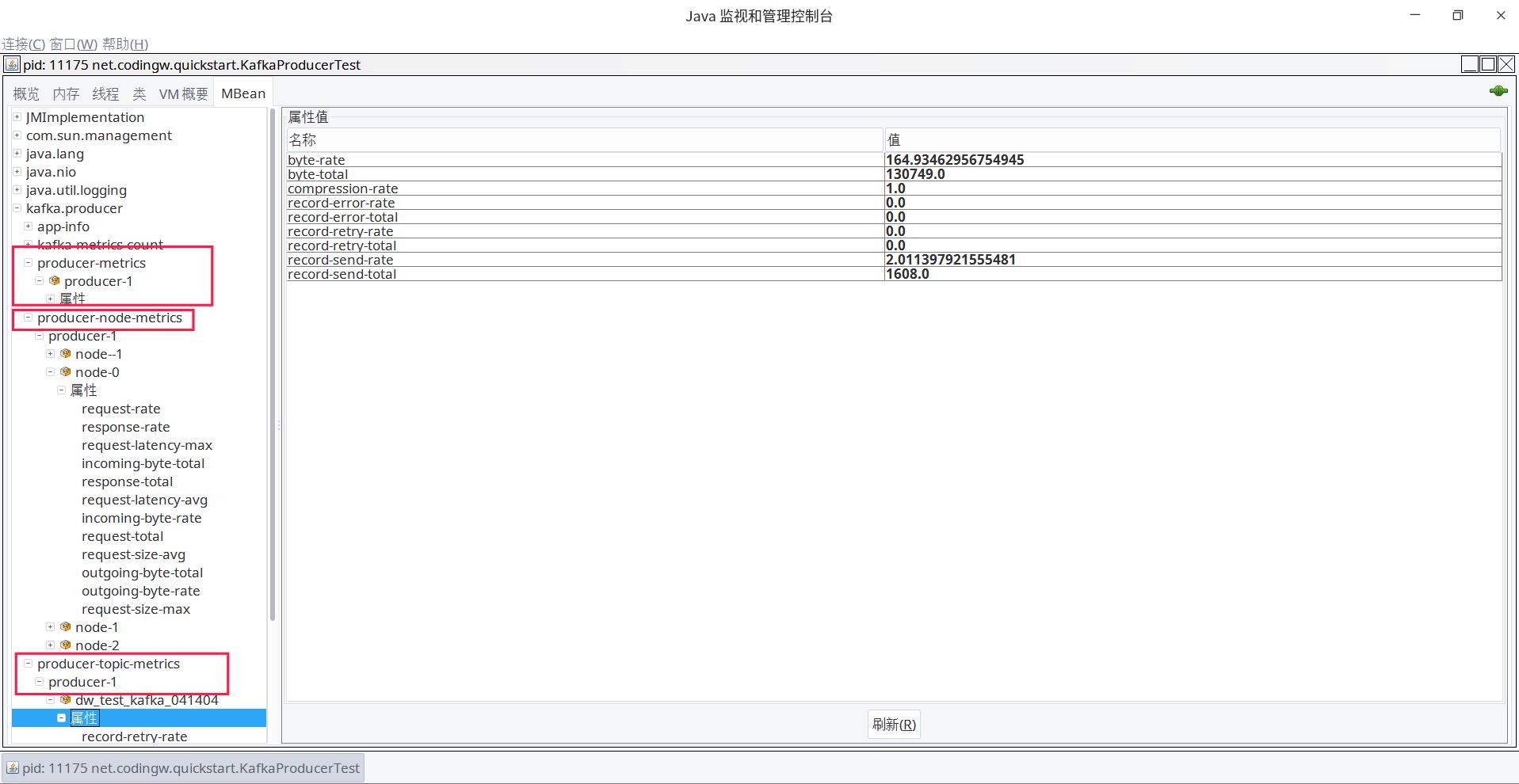
主要的监控指标分类如下:
- producer-metrics
消息发送端的监控指标,其子节点为该进程下所有的生产者 - producer-node-metrics
以Broker节点为维度,每一个发送方的数据指标。 - producer-topic-metrics
以topic为维度,统计该发送端的一些指标。
Kafka Producer相关的指标比较多,本文不会一一罗列。
1.1 producer-metrics
producer-metrics是发送端一个非常重要的监控项,如下图所示:
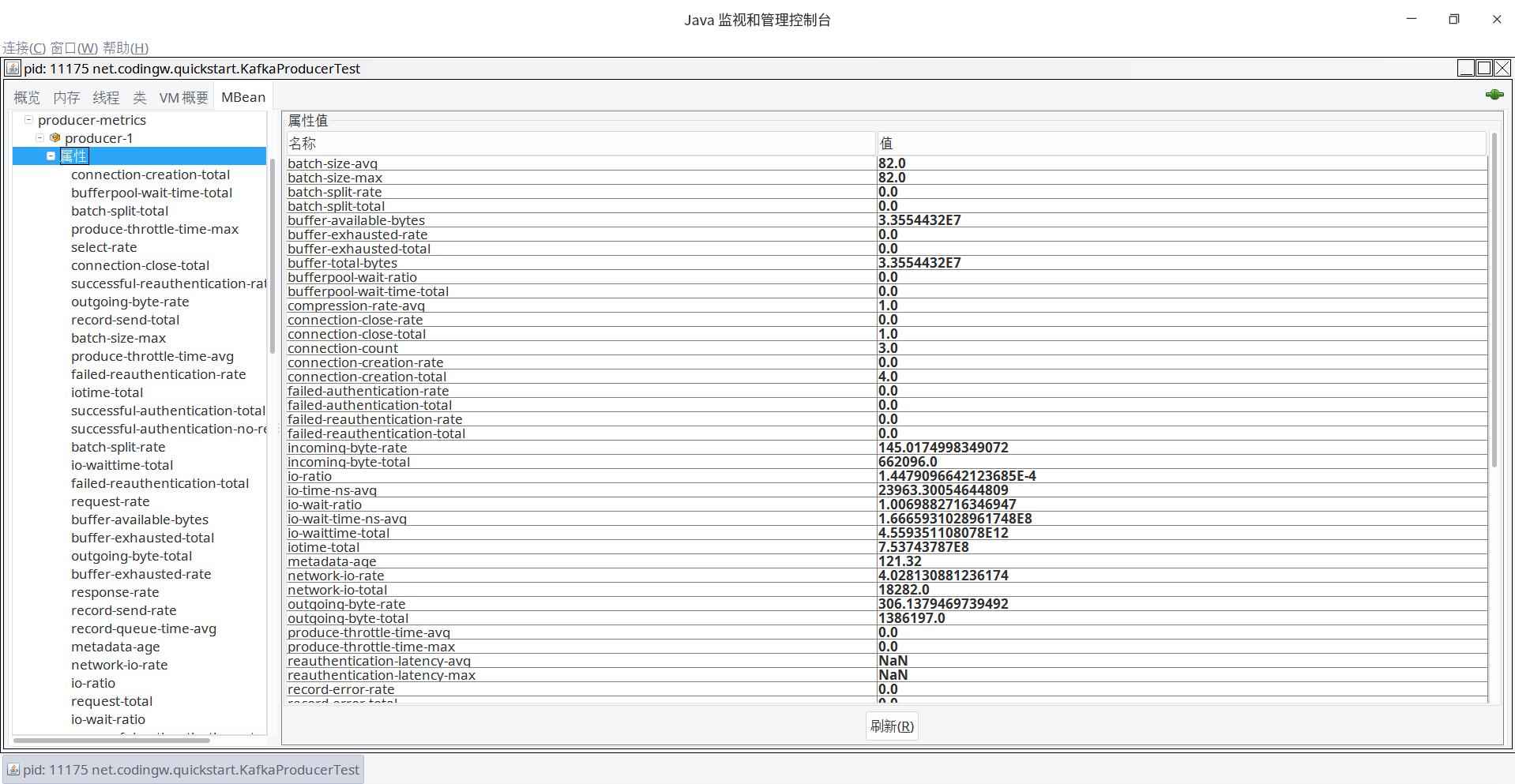
其重点项说明如下:
-
batch-size-avg
Sender线程实际发送消息时一个批次(ProducerBatch)的平均大小。 -
batch-size-max
Sender线程时间发送消息时一个批次的最大大小。实践指导:个人觉得这两个参数非常有必要进行采集,如果该值远小于batch.size设置的值,如果吞吐量不达预期,可以适当调大linger.ms。
-
batch-split-rate
Kafka提供了对大的ProducerBatch分割成小的机制,即如果客户端的ProducerBatch如果超过了服务端允许的最大消息大小,将会触发在客户端分割重新发送,该值记录每秒切割的速率 -
batch-split-total
Kafka 发生的 split 次数。温馨提示:按照笔者对这部分源码的阅读,我觉得ProducerBatch的split的意义不大,因为新分配的ProducerBatch的容量会等于batch.size,未超过该大小,则该Batch不会被分隔,笔者认为该功能大概率无法完成实际的切割意图。
实践指导:如果该值不为0,则表示服务端,客户端设置的消息大小不合理,客户端设置的batch.szie大小应该小于服务端设置的 max.message.bytes,默认值100W字节(约等于1M)
-
buffer-available-bytes
当前发送端缓存区可用字节大小。 -
buffer-total-bytes
发送端总的缓存区大小,默认为32M,33,554,432个字节。实战指导:如果缓存区剩余字节数持续较低,需要评估缓存区大小是否合适,Sender线程遇到了瓶颈,从而考虑网络、Brorker是否遇到瓶颈。
-
bufferpool-wait-ratio
-
bufferpool-wait-time-total
客户端从缓存区中申请内存用于创建ProducerBatch所阻塞的总时长。实战指导:如果该值持续大于0,说明发送存在瓶颈,可以适当降低linger.ms的值,让消息有机会得到更加及时的处理。
-
produce-throttle-time-avg
消息发送被broker限流的平均时间 -
produce-throttle-time-max
消息发送被broker限流的最大时间 -
io-ratio
IO线程处理IO读写的总时间 -
io-time-ns-avg
每一次事件选择器调用IO操作的平均时间(单位为纳秒) -
io-waittime-total
io线程等待读写就绪的平均时间(单位为纳秒) -
iotime-total
io处理总时间。 -
network-io-rate
客户端每秒所有连接的网络读写tps。 -
network-io-total
客户端所有连接上的网络操作(读或写)总数。
1.2 通用指标
Kafka在消息发送端除了上述指标外,还有一些通用类的监控指标,这类指标的统计维度包括:消息发送者、节点、TOPIC三个维度。

主要的维度说明如下:
- producer-metics
发送端维度 - producer-node-metrics
发送端-Broker节点维度 - producer-topic-metrics
发送端-主题维度的统计
接下来说明的指标,分别以不同的维度进行统计,但其表示的含义表示一样,故接下来统一说明。
-
incoming-byte-rate
每秒的入端流量,每秒进入的字节数。 -
incoming-byte-total
总共进入的字节数。 -
outgoing-byte-total
总出发送的字节数。 -
request-latency-avg
消息发送的平均延时。 -
request-latency-max
消息发送的最大延迟时间。
实战指导:latency-avg与max可以反应消息发送的延迟性能,如果延迟过高,说明Sender线程发送消息存在瓶颈,建议该值与linger.ms进行比较,如果该值显著小于linger.ms,则为了提高吞吐率,可适当调整batch.size的大小。
-
request-rate
每秒发送Tps -
request-size-avg
消息发送的平均大小。 -
request-size-max
Sender线程单次消息发送的最大大小。实战指导:如果该值迟迟小于max.request.size,说明客户端消息积压的消息不多,如果从其他维度表明遇到了瓶颈,可以适当linger.ms,batch.size,可有效提高吞吐。
-
request-total
请求发送的总字节数 -
response-rate
每秒接受服务端响应TPS -
response-total
收到服务端响应总数量。
2、监控指标采集
虽然Kafka内置了众多的监控指标,但这些指标默认是存储在内存中,既然是存放在内存中,为了避免监控数据无休止的增加内存触发内存溢出,通常监控数据的存储基本是基于滑动窗口,即只会存储最近一段时间内的监控数据,进行滚动覆盖。
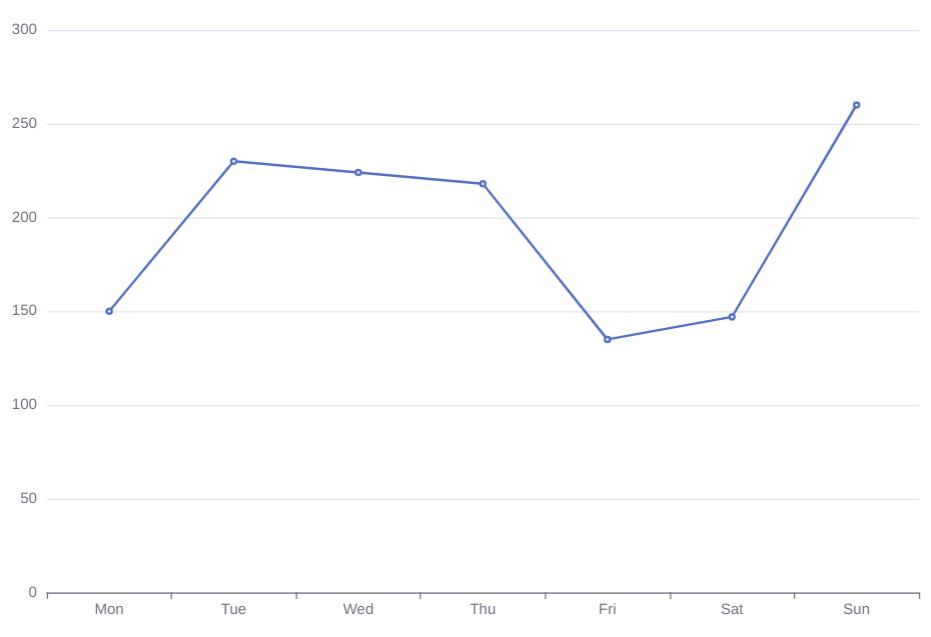
故为了更加直观的展示这些指标,因为需要定时将这些信息进行采集,统一存储在其他数据库等持久化存储,可以根据历史数据绘制曲线,希望实现的效果如下图所示:
基本的监控采集系统架构设计如下图所示:
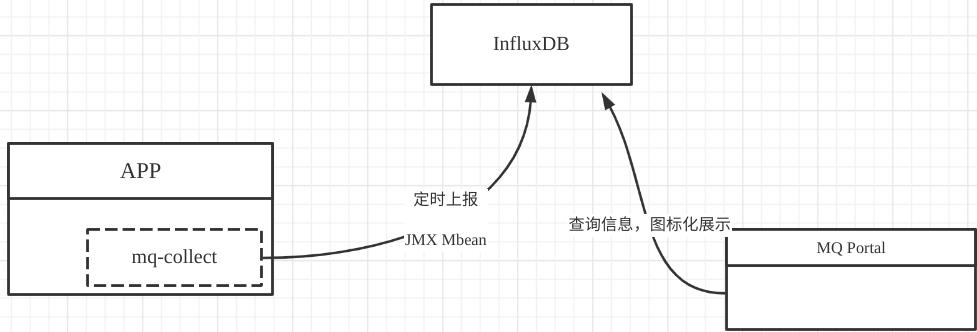
mq-collect应该是放在生产者SDK中,通过mq-collect类库异步定时将采集信息上传的到时序数据库InfluxDB,然后通过mq-portal门户展示页面,对每一个生产客户端按指标进行可视化展示,实现监控数据的可视化,从而为性能优化提供依据。
好了,本文就介绍到这里了,一键三连(关注、点赞、留言)是对我最大的鼓励。
掌握一到两门java主流中间件,是敲开BAT等大厂必备的技能,送给大家一个Java中间件学习路线,助力大家实现职场的蜕变。
最后分享笔者一个硬核的RocketMQ电子书,您将获得千亿级消息流转的运维经验。

获取方式:私信回复RMQPDF即可获取。
以上是关于面试官:你是如何诊断Kafka消息发送到瓶颈在哪里(有的放矢才是性能优化的正确打开方式)的主要内容,如果未能解决你的问题,请参考以下文章