使用Mycat实现数据切分(中)
Posted WhCAT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Mycat实现数据切分(中)相关的知识,希望对你有一定的参考价值。
前期回顾:
在前一篇文章中,我们安装好了Mycat,还尝试启动了一下。启动成功了,但却连接不上。在前面也针对这个问题做出解释了,是因为还没有对虚拟逻辑库进行配置。那接下来就跟着我一起走进Mycat的配置文件部分吧。在此之前,请先把先前搭建好的那4个集群启动起来,如果启动过程中遇到了问题或者还没有搭建这4个集群,可以在文章 中找到答案。
为了便于说明,重新贴上之前的集群列表
第一个PXC分片
第二个PXC分片
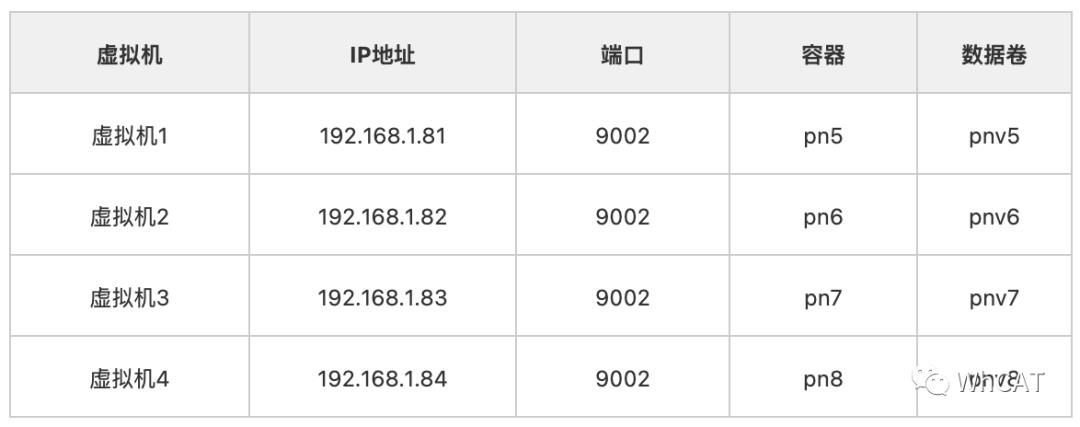
第一个Replication分片
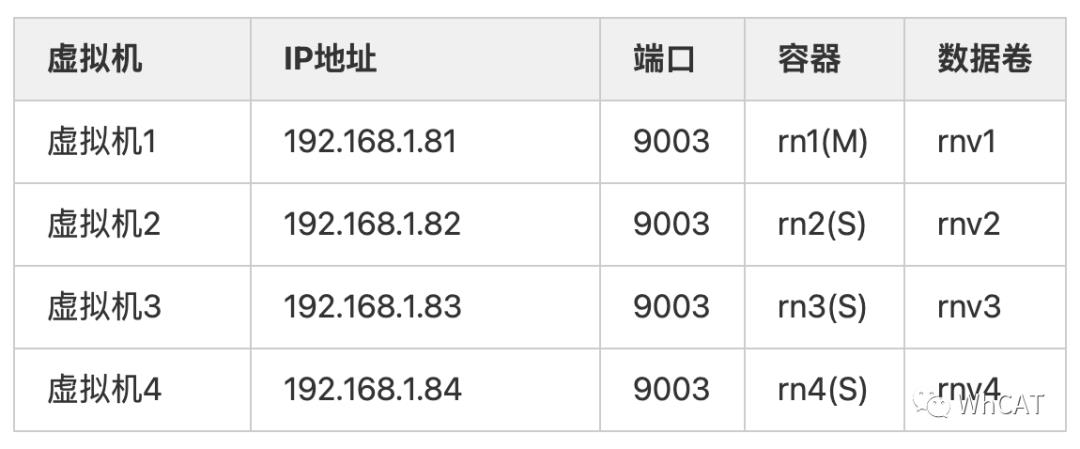
第二个Replication分片
|配置虚拟账户
虚拟账户在server.xml文件中进行配置。前面我说过Mycat有一个默认的用户名(root),密码(123456)。其实这些都是在server.xml文件中配置的。而这个默认的root账户其实就是一个虚拟账户。

那我们就仿照原来的,再新加一个虚拟账户吧。
<user name="admin" defaultAccount="true"><property name="password">123456</property><property name="schemas">myDB</property></user>
|schema.xml概述
虚拟逻辑库、虚拟逻辑表、分片规则、DataNode 以 及 DataSource都在schema.xml文件中进行配置,弄懂这个文件是使用Mycat的前提。
配置schema.xml主要针对三大标签进行配置:
schema:用于定义 MyCat 实例中的虚拟逻辑库,MyCat 可以有多个逻辑库,每个逻辑库都有自己的相关配置。可以使用 schema 标签来划分这些不同的逻辑库。
dataNode:用于定义 MyCat 中的数据节点,也就是我们通常说所的数据分片。一个 dataNode 标签就是一个独立的数据分片。
dataHost:用于定义具体的数据库实例、读写分离配置和心跳语句。
本文不对schema.xml中用到的所有标签进行解释,只会边用边解释其含义。关于schema.xml更为详细的解释,请参考官方文档:mycat权威指南。
|配置集群负载均衡
配置第一个PXC集群,使其具有负载均衡能力
<dataHost name="pxc1" maxCon="1000" minCon="10" balance="0"writeType="1" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="p1w1" url="192.168.1.81:9001" user="root"password="abc123456"/><writeHost host="p1w2" url="192.168.1.82:9001" user="root"password="abc123456"/><writeHost host="p1w3" url="192.168.1.83:9001" user="root"password="abc123456"/><writeHost host="p1w4" url="192.168.1.84:9001" user="root"password="abc123456"/></dataHost>
其中,dataHost标签下的几个属性解释如下:
name: dataHost标签唯一标识,供上层的标签调用。
maxCon: 每个读写实例连接池的最大连接,也就是说,标签内嵌套的writeHost、readHost标签都会使用这个属性的值来实例化出连接池的最大连接数。
minCon: 指定每个读写实例连接池的最小连接,初始化连接池的大小。
balance: 负载均衡类型,有以下取值:
0:不开启读写分离机制,所有的读操作都发送到当前可用的writeHost上面
1:全部的readHost与stand by writeHost参与select语句的负载均衡
2:所有的读操作都随机的在writeHost、readhost分发
3:所有的读请求分发到writeHost对应的readhost执行,writeHost不负担读压力,注意balance=3只在1.4及以后的版本有。
writeType:负载均衡类型,有以下取值:
0:所有的写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二个writeHost
1:所有的写操作都随机的发送到配置的writeHost
dbType: 指定后端连接的数据库类型,目前支持二进制的mysql协议,还有其他使用jdbc连接的数据库。例如mongodb、oracle、spark等。
dbDriver: 指定连接后端数据库使用的 Driver,目前可选的值有 native 和 JDBC。使用 native 的话,因为这个值执行的是二进制的 mysql 协议,所以可以使用 mysql 和maridb。其他类型的数据库则需要使用 JDBC 驱动来支持。
switchType: 配置切换类型,有以下取值:
-1: 不自动切换
1:默认值,自动切换
2:基于MySQL主从同步的状态决定是否切换
上面的配置可概括为:
balance=0:不使用读写分离
writeType=1:读写请求随机发送给可用的写节点
dbDriver='native"使用mysql数据库自带的驱动
switchType=1:根据自己心跳检测的结果,判断是哪一个mysql数据库宕机了
slaveThreshold=100:跟replication集群有关,如果从库落后主库100s就剔除这个从库
<heartbeat>:心跳检测执行的sql语句 <writeHost>:配置mysql节点的,host代表别名
在这里我们配置了4个writeHost,没有使用读写分离。writeHost即会写数据也会读数据,在读写数据时将随机发送给可用的writeHost。至于是否可用,则使用<heartbeat>配置的心跳SQL检测,如果不可用则将其剔除。
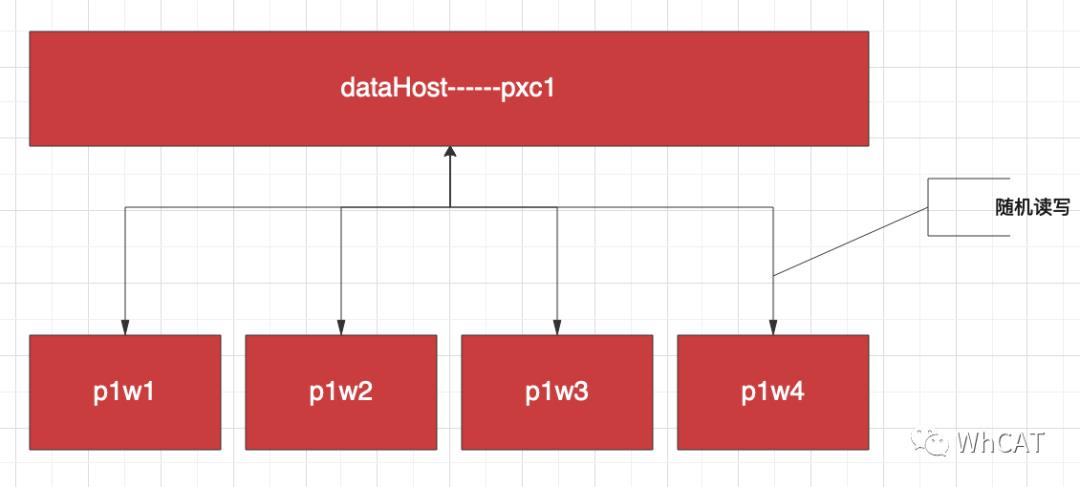
用同样的方式配置第二个PXC集群:
<dataHost name="pxc2" maxCon="1000" minCon="10" balance="0"writeType="1" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="p2w1" url="192.168.1.81:9002" user="root"password="abc123456"/><writeHost host="p2w2" url="192.168.1.82:9002" user="root"password="abc123456"/><writeHost host="p2w3" url="192.168.1.83:9002" user="root"password="abc123456"/><writeHost host="p2w4" url="192.168.1.84:9002" user="root"password="abc123456"/></dataHost>
|配置集群读写分离
配置第一个Replication集群
<dataHost name="rep1" maxCon="1000" minCon="10" balance="3"writeType="1" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="r1w1" url="192.168.1.81:9003" user="root"password="abc123456"><readHost host="r1r1" url="192.168.1.82:9003" user="root"password="abc123456"/><readHost host="r1r2" url="192.168.1.83:9003" user="root"password="abc123456"/><readHost host="r1r3" url="192.168.1.84:9003" user="root"password="abc123456"/></writeHost></dataHost>
配置第二个Replication集群
<dataHost name="rep2" maxCon="1000" minCon="10" balance="3"writeType="1" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="r2w1" url="192.168.1.81:9004" user="root"password="abc123456"><readHost host="r2r1" url="192.168.1.82:9004" user="root"password="abc123456"/><readHost host="r2r2" url="192.168.1.83:9004" user="root"password="abc123456"/><readHost host="r2r3" url="192.168.1.84:9004" user="root"password="abc123456"/></writeHost></dataHost>
在这里把balance设置成了3,实现了读写分离:所有的读请求分发到writeHost对应的readHost执行(可能有点拗口,可以看到readHost标签是writeHost标签的子标签),writeHost只负责写不负担读压力。
|配置分片
使用dataNode标签配置分片。
<dataNode name="dn1" dataHost="pxc1" database="testDB1" /><dataNode name="dn2" dataHost="pxc2" database="testDB1" /><dataNode name="dn3" dataHost="rep1" database="testDB2" /><dataNode name="dn4" dataHost="rep2" database="testDB2" />
dataNode标签的配置起来比较简单,涉及到了以下3个属性:
name:dataNode标签唯一标识,供上层的标签调用
dataHost: 之前配置的dataHost标签的name
database:真实存在的逻辑库名称
配置分片说白了就是引用一下前面设置的dataHost,并声明一下dataHost下真实存在的逻辑库。一个dataHost可以设置多个分片出来(比如有多个逻辑库),像下面这样:
<dataNode name="dn1" dataHost="pxc1" database="testDB1" /><dataNode name="dn2" dataHost="pxc2" database="testDB1" /><dataNode name="dnA" dataHost="pxc1" database="myDB1" /><dataNode name="dnB" dataHost="pxc2" database="myDB1" /><dataNode name="dn3" dataHost="rep1" database="testDB2" /><dataNode name="dn4" dataHost="rep2" database="testDB2" />
testDB1表结构如下:
CREATE TABLE `customer` (`ID` int(10) unsigned NOT NULL,`NAME` varchar(200) NOT NULL,`CITY_ID` int(10) unsigned NOT NULL,PRIMARY KEY (`ID`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;CREATE TABLE `payment` (`ID` int(10) unsigned NOT NULL,`CUSTOMER_ID` int(10) unsigned NOT NULL,`PAY` decimal(10,2) unsigned NOT NULL,`CREATE_TIME` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`ID`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
testDB2表结构如下:
CREATE TABLE `company` (`ID` int(10) unsigned NOT NULL,`NAME` varchar(200) NOT NULL,`CITY_ID` smallint(6) NOT NULL,PRIMARY KEY (`ID`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;CREATE TABLE `student` (`ID` int(10) unsigned NOT NULL,`NAME` varchar(200) NOT NULL,PRIMARY KEY (`ID`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;CREATE TABLE `teacher` (`ID` int(10) unsigned NOT NULL,`NAME` varchar(200) NOT NULL,PRIMARY KEY (`ID`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
请创建数据库testDB1和数据库testDB2,后面将会用到。
|配置虚拟逻辑库
使用schema标签配置虚拟逻辑库。
在这里,我想要实现的效果是:
针对testDB1数据库:
根据城市ID切分存储testDB1的customer表数据,需要注意的是payment表和customer表存在关联关系。我们不可能做跨节点多表关联查询,所以有关联关系的数据要存储到同一个分片上,这里则用到了父子表。
针对testDB2数据库:
根据城市ID切分存储testDB2的company表数据,利用主键求模切分存储student表数据。而teacher表由于数据量不大,又为了要演示全局表,因此在这里直接定义成全局表。
除此之外,还涉及到自定义切分规则,比如根据城市id切分等等。这里涉及到的知识还有很多,所以我打算放到下一篇文章来说。
|小结
本篇文章讲了如何通过配置dataHost标签实现数据源配置、读写分离配置、负载均衡配置;如何通过配置dataNode标签实现分片配置。下一节我将介绍如何自定义切分规则,如何实现数据切分,父子表、全局表的概念以及应用场景,并把Mycat真正启动起来。
以上是关于使用Mycat实现数据切分(中)的主要内容,如果未能解决你的问题,请参考以下文章