基于Spark的WordCount小项目
Posted Mr.zhou_Zxy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Spark的WordCount小项目相关的知识,希望对你有一定的参考价值。
Spark入门小项目
一 经典项目:WordCount
方式一
类似于Scala的写法
package com.zxy.SparkCore
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount{
def main(args: Array[String]): Unit = {
//建立和Spark框架的连接
val wordCount: SparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val context: SparkContext = new SparkContext(wordCount)
//读取指定文件目录的数据
val lines: RDD[String] = context.textFile("spark-core\\\\dates")
//数据切割
val words: RDD[String] = lines.flatMap(_.split("\\\\s+"))
//数据分组
val map: RDD[(String, Iterable[String])] = words.groupBy(word => word)
//数据格式化
val WordToCount: RDD[(String, Int)] = map.map {
case (word, list) => (word, list.size)
}
//数据收集
val array: Array[(String, Int)] = WordToCount.collect()
//数据打印
array.foreach(println)
//关闭连接
context.stop()
}
}
方式一简化版
package com.zxy.SparkCore
import org.apache.spark.{SparkConf, SparkContext}
object WordCount{
def main(args: Array[String]): Unit = {
//建立和Spark框架的连接
val wordCount: SparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val context: SparkContext = new SparkContext(wordCount)
//函数式编程特点
context.textFile("spark-core\\\\dates").flatMap(_.split("\\\\s+")).groupBy(word => word).map(kv => (kv._1,kv._2.size)).collect().foreach(println)
//关闭连接
context.stop()
}
}
方式二
采用了Spark特有方法的写法
package com.zxy.SparkCore
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount2{
def main(args: Array[String]): Unit = {
//建立和Spark框架的连接
val wordCount: SparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val context: SparkContext = new SparkContext(wordCount)
//读取指定文件目录数据
val lines: RDD[String] = context.textFile("spark-core\\\\dates")
//切分数据
val words: RDD[String] = lines.flatMap(_.split("\\\\s+"))
//数据分组
val WordToOne: RDD[(String, Int)] = words.map(
word => (word, 1)
)
//spark提供的方法,将分组和聚合通过一个方法实现
//reduceByKey:相同的饿数据,可以对value进行reduce聚合
val WordToCount: RDD[(String, Int)] = WordToOne.reduceByKey(_ + _)
//数据收集
val array: Array[(String, Int)] = WordToCount.collect()
//数据打印
array.foreach(println)
//关闭连接
context.stop()
}
}
方式二简化版
package com.zxy.SparkCore
import org.apache.spark.{SparkConf, SparkContext}
object WordCount4{
def main(args: Array[String]): Unit = {
//建立和Spark框架的连接
val wordCount: SparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val context: SparkContext = new SparkContext(wordCount)
context.textFile("spark-core\\\\dates").flatMap(_.split("\\\\s+")).map(word => (word,1)).reduceByKey(_ + _).collect().foreach(println)
//关闭连接
context.stop()
}
}
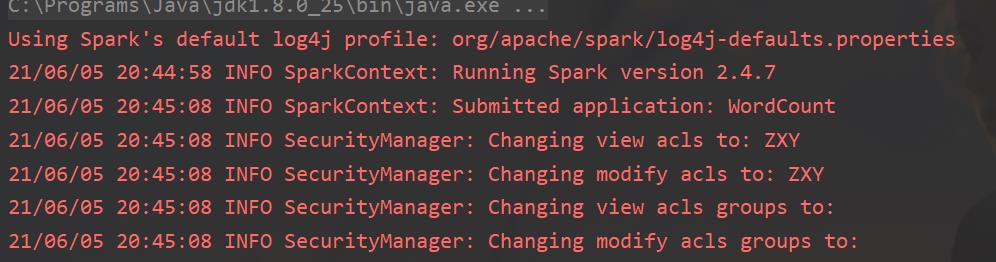
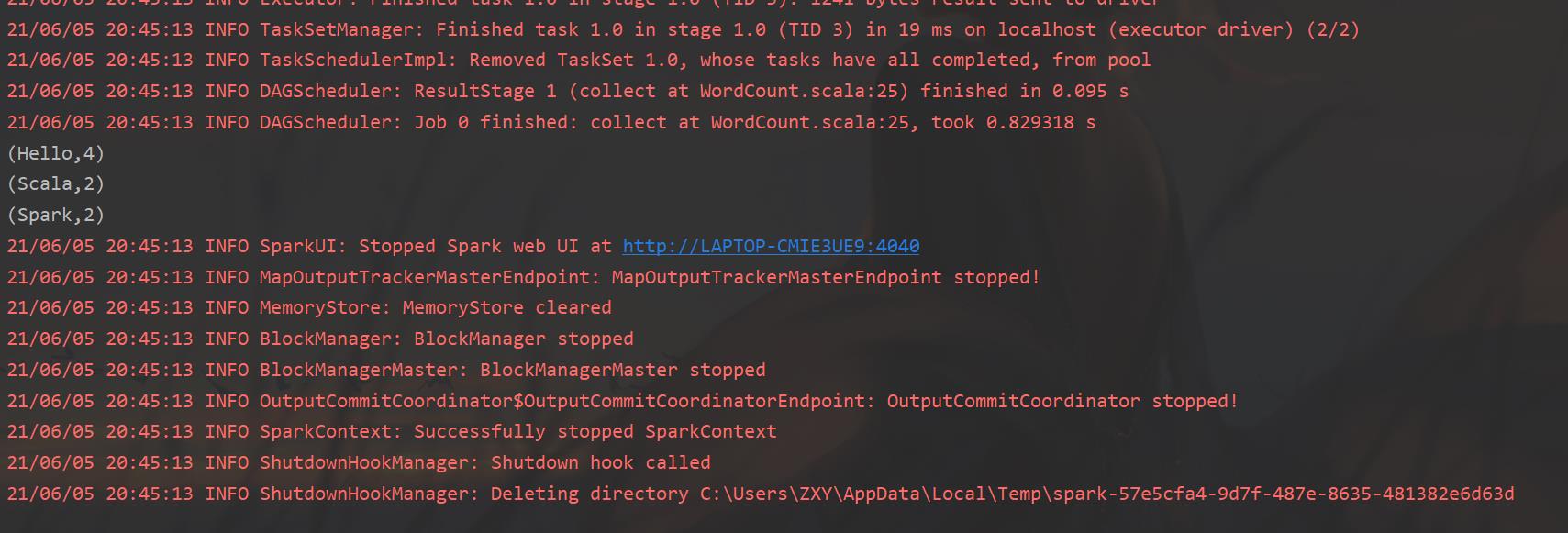
控制台效果
二 Maven的POM文件
我这里采用的Scala2.11.8
使用的Spark2.4.7
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scalap</artifactId>
<version>2.11.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.7</version>
</dependency>
</dependencies>
三 基于Java、Scala、MR的WordCound在这篇文章中
Scala\\Java\\Mapreduce代码实现词频统计
https://blog.csdn.net/m0_51197424/article/details/117549255
以上是关于基于Spark的WordCount小项目的主要内容,如果未能解决你的问题,请参考以下文章