Spark学习总结-Spark框架
Posted Mr.zhou_Zxy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark学习总结-Spark框架相关的知识,希望对你有一定的参考价值。
Spark框架
一 Spark介绍
1.spark和Hadoop
Spark和Hadoop的根本差异是多个作业之间的数据通信问题:
Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘的
2.spark和mapreduce
在绝大多数的数据计算场景中,spark确实会比mapreduce更有优势,
但是Spark是基于内存的,所以在实际的生产环境中,由于内存的限制,
可能会由于内存资源不够导致Job执行失败,此时,Mapreduce其实是
一个更好的选择,所以Spark并不能完全替代MR
3.spark组件

1.Spark Core
spark core中提供了Spark最基础和最核心的功能,spark其他功能如:Spark SQL,spark Streaming,GraphX,Mlib都是在spark core上拓展的
2.Spark SQL
spark sql是spark用来操作结构化数据的组件。通过spark sql,用户可以使用SQL或者hive
3.Spark Streaming
Spark Streaming是spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API
二 快速入门
1 WordCount项目
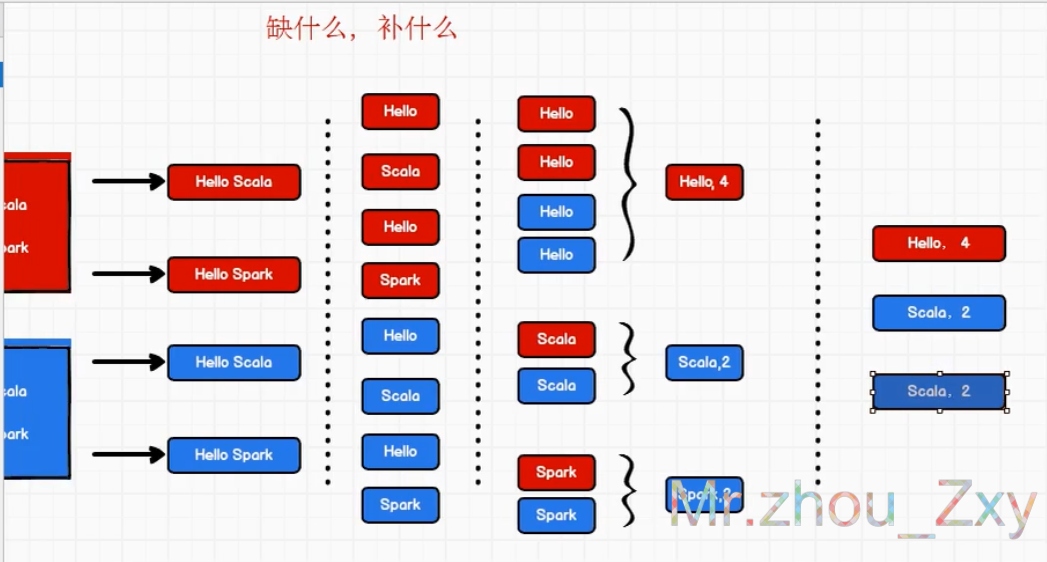
采用了Spark特有方法的写法
package com.zxy.SparkCore
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount2{
def main(args: Array[String]): Unit = {
//建立和Spark框架的连接
val wordCount: SparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val context: SparkContext = new SparkContext(wordCount)
//读取指定文件目录数据
val lines: RDD[String] = context.textFile("spark-core\\\\dates")
//切分数据
val words: RDD[String] = lines.flatMap(_.split("\\\\s+"))
//数据分组
val WordToOne: RDD[(String, Int)] = words.map(
word => (word, 1)
)
//spark提供的方法,将分组和聚合通过一个方法实现
//reduceByKey:相同的饿数据,可以对value进行reduce聚合
val WordToCount: RDD[(String, Int)] = WordToOne.reduceByKey(_ + _)
//数据收集
val array: Array[(String, Int)] = WordToCount.collect()
//数据打印
array.foreach(println)
//关闭连接
context.stop()
}
}
简化版
package com.zxy.SparkCore
import org.apache.spark.{SparkConf, SparkContext}
object WordCount4{
def main(args: Array[String]): Unit = {
//建立和Spark框架的连接
val wordCount: SparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val context: SparkContext = new SparkContext(wordCount)
context.textFile("spark-core\\\\dates").flatMap(_.split("\\\\s+")).map(word => (word,1)).reduceByKey(_ + _).collect().foreach(println)
//关闭连接
context.stop()
}
}
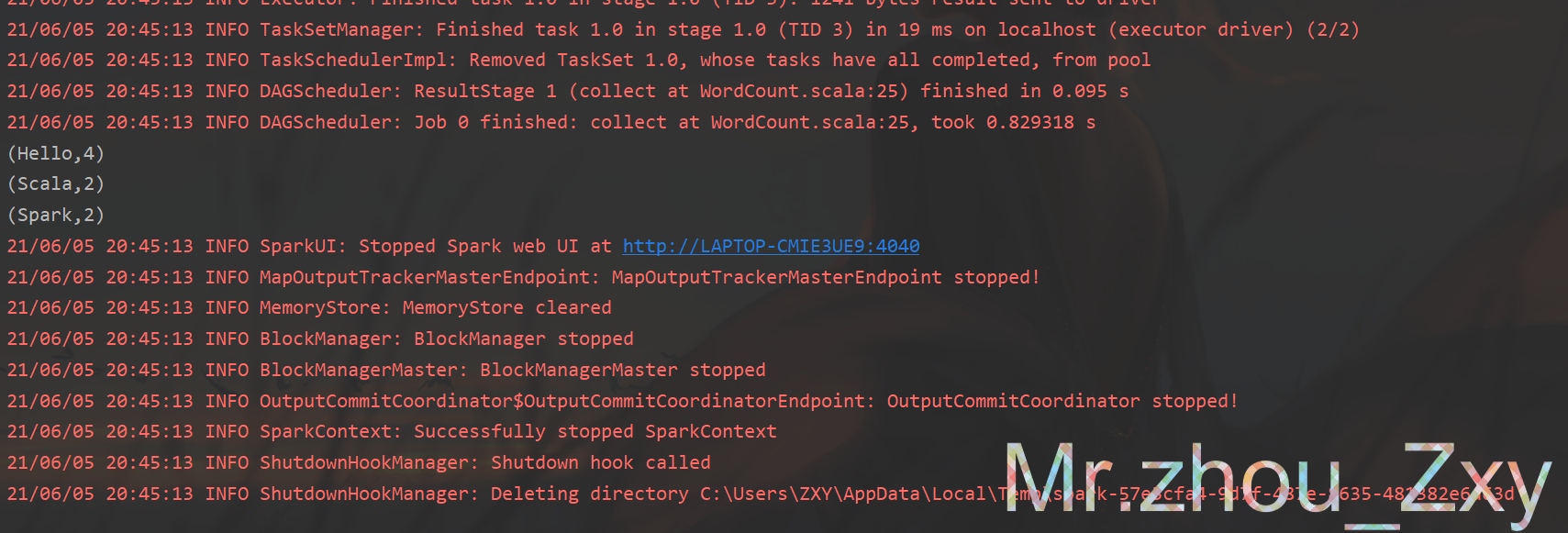
控制台效果
2 Maven的POM文件
我这里采用的Scala2.11.8
使用的Spark2.4.7
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scalap</artifactId>
<version>2.11.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.7</version>
</dependency>
</dependencies>
3 log4j.properties
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# Set everything to be logged to the console
# log4j.rootCategory=INFO, console
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=WARN
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=WARN
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
# Parquet related logging
log4j.logger.org.apache.parquet.CorruptStatistics=ERROR
log4j.logger.parquet.CorruptStatistics=ERROR
三 Linux安装Spark
Hadoop版本采用2.8.1,Spark版本采用3.0.2
## 解压缩
[root@hadoop software]# tar -zxvf spark-3.0.2-bin-hadoop3.2.tgz -C /opt/
Welcome to
____ __
/ __/__ ___ _____/ /__
_\\ \\/ _ \\/ _ `/ __/ '_/
/___/ .__/\\_,_/_/ /_/\\_\\ version 3.0.2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_45)
Type in expressions to have them evaluated.
Type :help for more information.
## Web UI
http://192.168.130.129:4040/jobs/
快速入门
scala> sc.textFile("data/date.txt").flatMap(_.split("\\\\s+")).groupBy(word => word).map(vk => (vk._1,vk._2.size)).collect().foreach(println)
(Spark,1)
(Hello,2)
(Scala,1)
scala> sc.textFile("data/date.txt").flatMap(_.split("\\\\s+")).map(word => (word,1)).reduceByKey(_ + _).collect().foreach(println)
(Spark,1)
(Hello,2)
(Scala,1)
四 IDEA项目上传到Spark终端
## Maven项目打包上传到Spark,
bin/spark-submit \\
--class com.zxy.SparkCore.WordCount4 \\
--master local[2] \\
/opt/apps/spark-3.0.2/data/spark-core-1.0-SNAPSHOT.jar \\
10
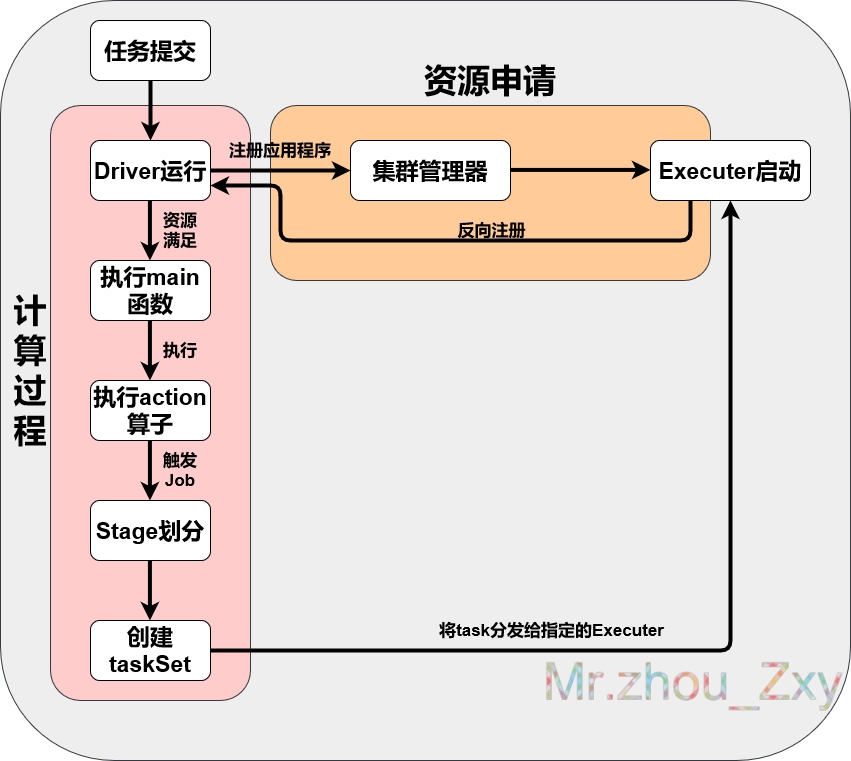
五 Spark资源申请架构
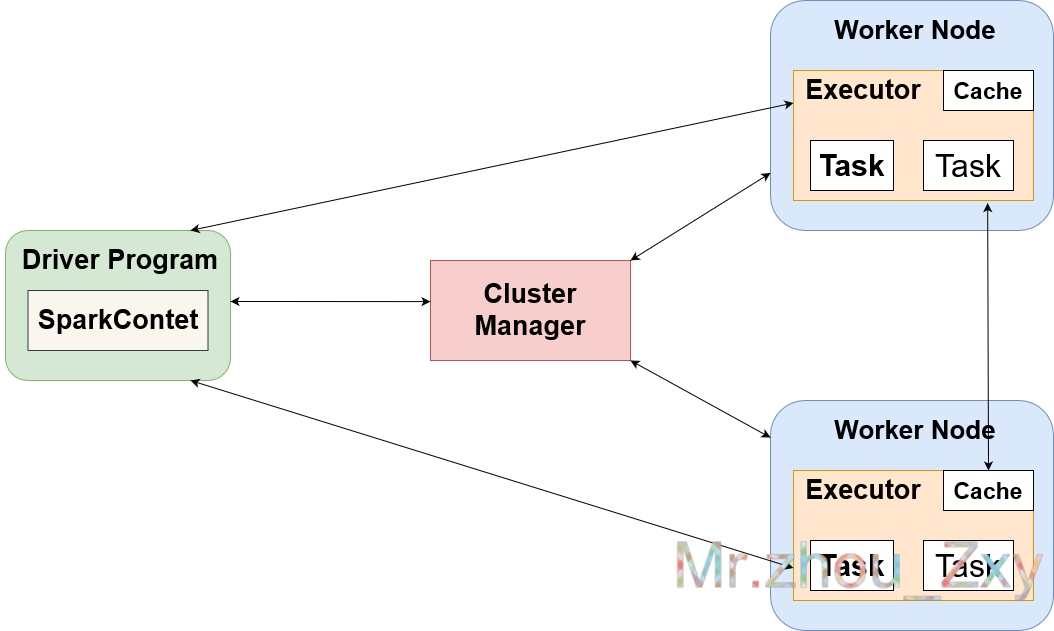
六 提交流程(资源申请和运算)
以上是关于Spark学习总结-Spark框架的主要内容,如果未能解决你的问题,请参考以下文章