Apache Solr搜索引擎搭建配置使用详细教程
Posted Java_Pluto
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Solr搜索引擎搭建配置使用详细教程相关的知识,希望对你有一定的参考价值。
最近因业务中需要对数据库里面的数据进行多维度检索,完全依赖SQL已经无法满足业务的需求了,显然我们需要搜索技术的支持。这玩意也没啥可技术调研的,基本上就如下几种方案:
- 自己搭建搜索引擎,采用ElasticSearch
- 自己搭建搜索引擎,采用Solr
- 使用云服务,使用阿里云的开放搜索产品或者ES产品
业务场景:
- 不需要数据实时同步
- 数据量小、访问频次低,因此单机即可
- 能提供各个字段的多维度模糊查询
- 能简单快速上手,容易维护
- 成本低
基于以上场景,基本上就pass掉了使用云服务,因为它真的不便宜,最便宜的阿里云开放搜索或者ES产品也得1元/小时,也就是一个月720元,一年8640元,这还只是一个搜索应用,如果有多个费用会更多,所以我们还是选择自建吧。那就需要考虑到运维成本的问题了,要能简单快速上手且易于维护,所以我最终选择了solr。
本文主要详细说明solr的搭建步骤,建议大家收藏文章后,跟着文章自己动手再搭建一次,以便掌握solr的相关知识。
solr官网:
https://lucene.apache.org/solr/
Solr is the popular, blazing-fast, open source enterprise search platform built on Apache Lucene™.
Solr是基于Apache Lucene™构建的流行的、速度极快的开源企业搜索平台。
下载&解压
//下载最新版8.4.1
wget http://mirror.bit.edu.cn/apache/lucene/solr/8.4.1/solr-8.4.1.tgz
//解压到solr-8.4.1
tar xzf solr-8.4.1.tgz
解压后的文件目录如下:
Apache Solr搜索引擎搭建、配置、使用详细教程
bin:脚本文件
contrib:solr专用功能的附加插件
dist:依赖的jar文件
docs:文档
example:示例
licenses:使用到的第三方许可证书
server:solr核心应用程序所在目录
启动solr服务
#启动solr
sh bin/solr start -force
可能会出现启动失败的情况:
bin/solr: line 739: syntax error near unexpected token `<'
bin/solr: line 739: ` done < <(find "$SOLR_PID_DIR" -name "solr-*.pid" -type f)'
这是可能端口被占用了,换一个指定端口启动:
./bin/solr start -p 8983 -force
输出日志:

Apache Solr搜索引擎搭建、配置、使用详细教程
这样就启动成功了,访问8983的控制台http://127.0.0.1:8983(注意检查服务器端口8983是否开放状态):
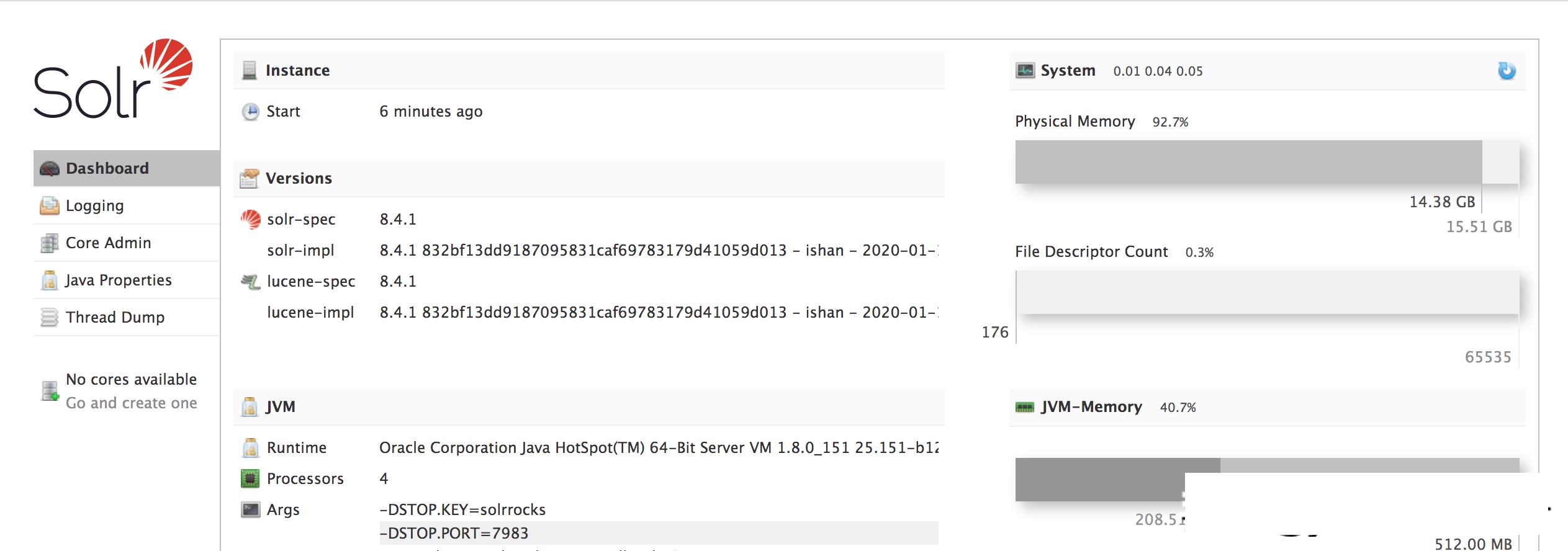
Apache Solr搜索引擎搭建、配置、使用详细教程
solr控制台
这样我们的solr就安装成功了。
配置Solr Core
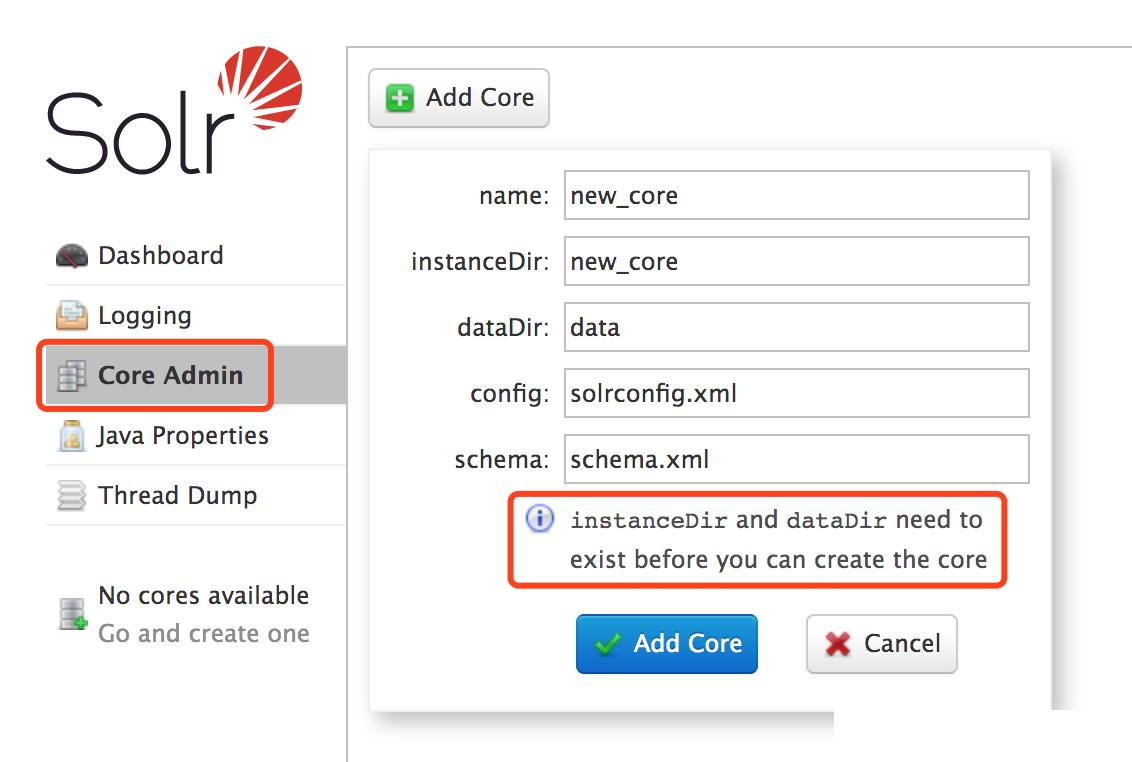
Apache Solr搜索引擎搭建、配置、使用详细教程
add core
可以看到提示说创建Core之前,instanceDir和dataDir文件夹必须已经存在。那么我们就先创建好对应的文件夹,记住这个目录:solr-8.4.1/server/solr,我们会在这个目录下创建core所属的instanceDir,而dataDir则在instanceDir目录下,可以拷贝configsets/_default/conf/目录下的所有文件到新建的core下面:
cp -r configsets/_default/conf/ test_rong_msg_history/
然后回到管理页面执行Create Core,创建好我们的Core:
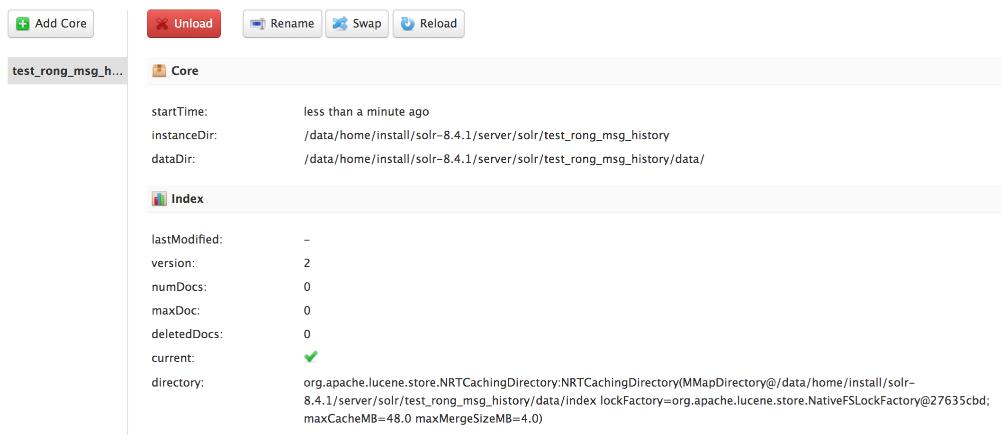
配置中文分词器
因为我们需要对中文内容进行模糊查询、匹配,则需要单独配置中文分词器,下载ik-analyzer-8.3.0.jar,最好与自己的solr版本对应:
wget https://repo1.maven.org/maven2/com/github/magese/ik-analyzer/8.3.0/ik-analyzer-8.3.0.jar
下载完毕后放到
server/solr-webapp/webapp/WEB-INF/lib目录下,再回到我们刚刚创建的Core目录下,编辑managed-schema文件,增加如下内容:

重启solr:
bin/solr restart -force
去solr控制台测试一下中文分词,选择text_ik进行分析,可以看到IKT的分词结果:

中文分词
也可以自定义分词,比如我们想将“测试中文分词”中的“中文分”单独作为一个词来分词的话,那么可以如下操作:
1.解压ik-analyzer-8.3.0.jar,执行jar -xvf ik-analyzer-8.3.0.jar得到如下文件目录:

2.将ext.dic、stopword.dic、IKAnalyzer.cfg.xml三个文件拷贝到
solr-8.4.1/server/solr-webapp/webapp/WEB-INF/classes目录下(没有classes目录mkdir一下):

3.其中ext.dic就是我们自定义的中文词,将“中文分”加到这个文件中去,重启solr,再试试分词效果:

自定义分词
可以看到,“中文分”已经作为一个词被solr拆出来了。
数据源配置DataImport
我们使用solr的目的就是为了更方便、更多维度、更快速度的检索数据,而数据都会存储在数据库中,所以就需要我们将数据库中的数据及时的导入到solr搜索引擎中,便于业务搜索。
依赖jar包下载到dist文件夹对应目录下:

编辑配置文件
test_rong_msg_history/conf/solrconfig.xml新增如下内容:
在conf目录下新增data-config.xml,主要是为了配置连接mysql数据库的数据源信息:

数据源配置好了,接下来回来solr控制台,在控制台选择我们之前添加的core,配置其schema,也可以直接编辑managed-schema文件来配置field:

至此,配置工作完成,开始讲数据库中的数据导入到solr中来,执行Dataimport:
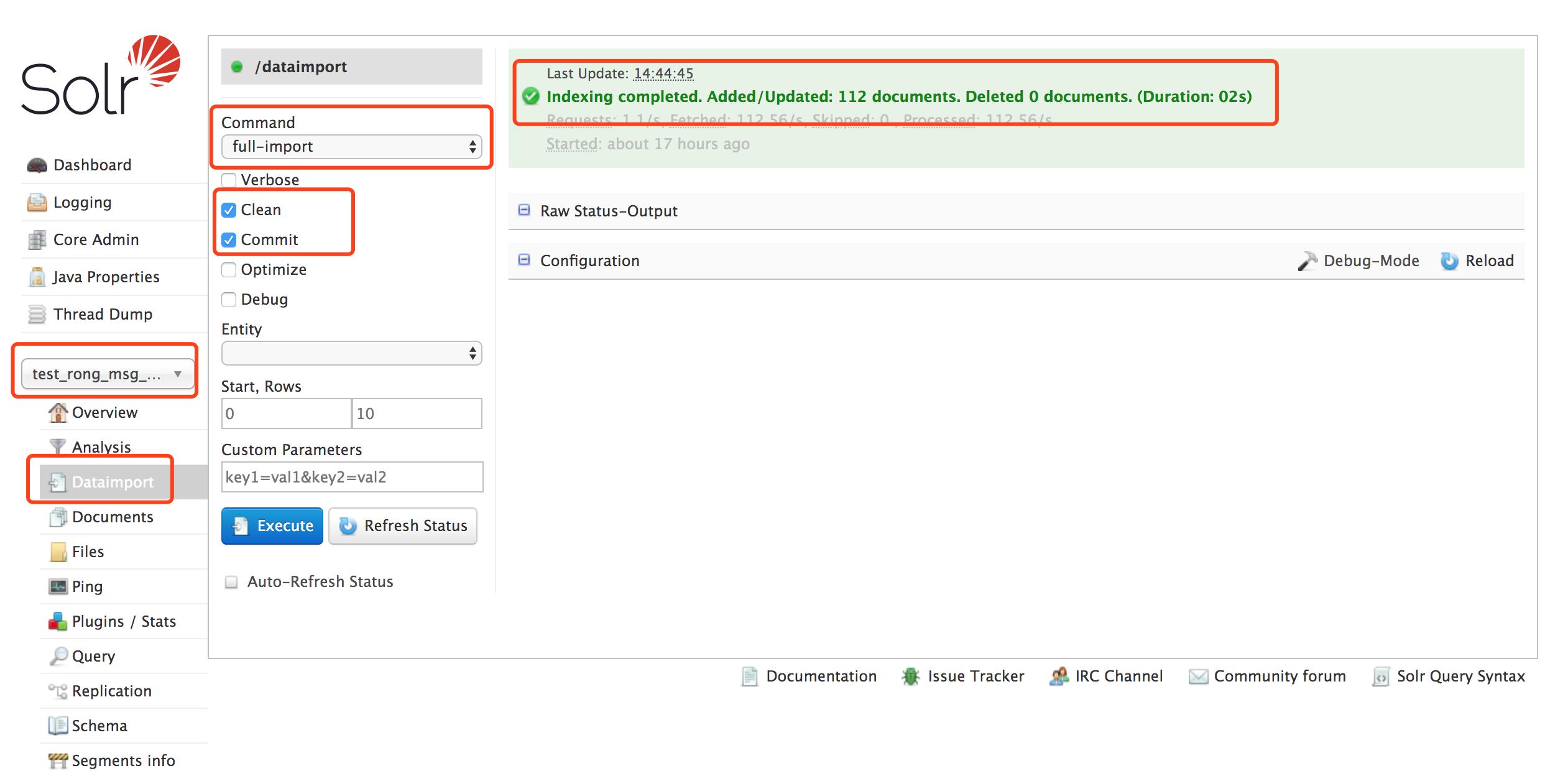
可以看到从数据库中导入了112条记录到solr,这个时候执行Query,发现可以查询数据了:
这样我们便完成了从mysql导入数据到solr的配置工作,大家便可以根据solr的相关查询API来开发自己的业务了。
以上就是solr的搭建、配置中文分词、配置数据源的详细步骤说明,建议大家感兴趣的可以自己在本地动手搭建一下,相信大家自己搭建后,不仅初步掌握了solr搜索引擎的基础知识,还会获得更多其他的收获。
最后
最近我整理了整套《JAVA核心知识点总结》,说实话 ,作为一名Java程序员,不论你需不需要面试都应该好好看下这份资料。拿到手总是不亏的~我的不少粉丝也因此拿到腾讯字节快手等公司的Offer

好了,以上就是本文的全部内容了,如果觉得有收获,记得三连,我们下期再见。

以上是关于Apache Solr搜索引擎搭建配置使用详细教程的主要内容,如果未能解决你的问题,请参考以下文章