论文阅读|《用强化学习求解带插单的动态FJSP》
Posted 码丽莲梦露
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读|《用强化学习求解带插单的动态FJSP》相关的知识,希望对你有一定的参考价值。
《Dynamic scheduling for flexible job shop with new job insertions by deep reinforcement learning》
Applied Soft Computing Journal/2020

这篇文章使用DRL来解决带新件插入的DFJSP问题,目标为最小化总拖期,贡献如下:
(1)使用在[0,1]中取值的七个通用特征表示每个重调度点的状态。
(2)设计了六个组合规则(动作)来确定下一步要处理的工序和分配的机器。
(3)提出了一种深度Q网络(DQN),获取每个规则的state–action值,根据该值可以在不同的决策点上选择最合适的调度规则。
(4)实验
1 Q-learning 和Deep Q-learning 的概念
1.1 RL 和 Q-learning
强化学习可以看作一个五元组的马尔可夫过程模型(MDP),在MDP中,智能体根据周围环境选择合适的行动。强化学习的目标是找到一个最优策略使得总过程的奖励值最优。
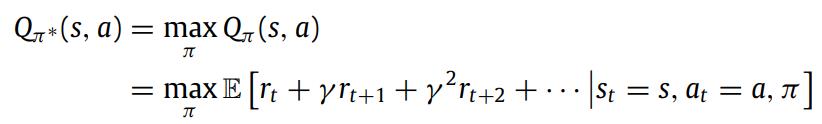
1.2 深度Q-network 和深度Q-learning
为了解决标准Q学习的维度灾难,用神经网络来近似表示Q-learning的Q函数,设置了当前Q和目标Q和Replay Memory,Replay memory中存放每一次试错的行动、状态、奖励值和下一状态,以此来训练目标Q,并设置每隔C步更新当前Q,即目标Q赋值给当前Q,其中,目标值的计算式如下:
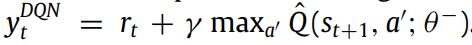
1.3 Double DQN
Double DQN更改了DQN的目标值计算公式,为:
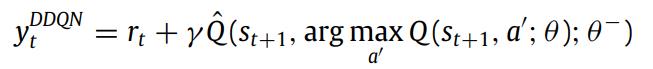
伪代码如下:

1.4 软目标权值更新策略
以往当前Q的更新,是设置定步长C,当C值的选取具有一定的不确定性,会影响收敛速度,因此,这篇文章对此进行了修改,即在每一步按权重进行更新:
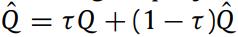
2 问题描述
以最大拖期为目标的普通FJSP
3 算法设计
3.1 整体框架
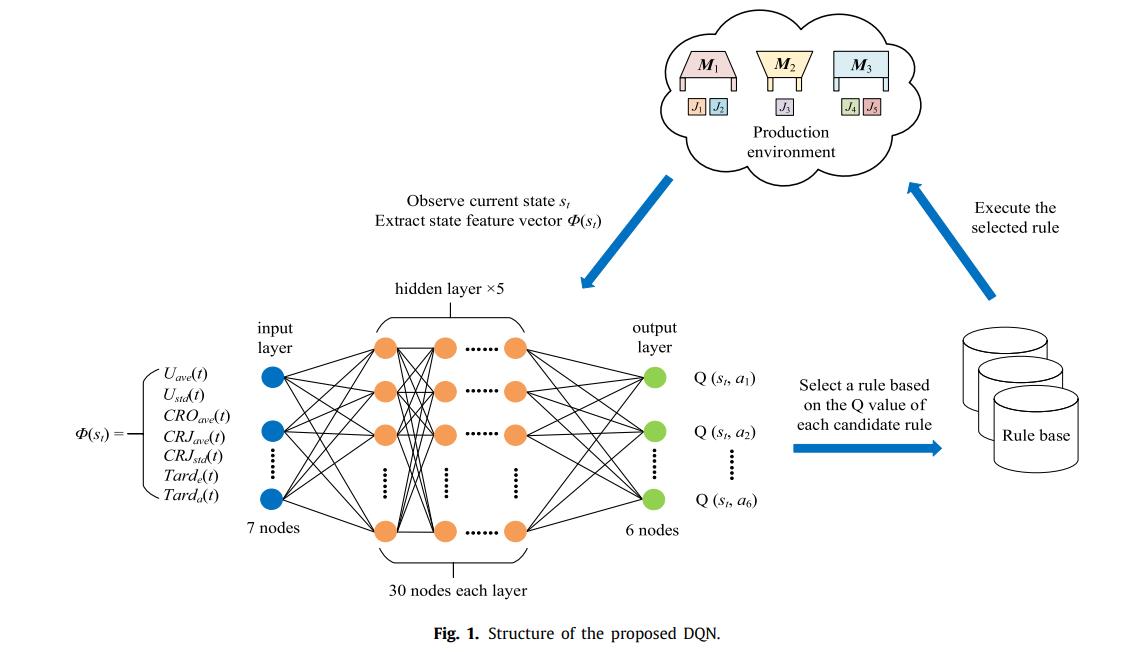
3.2 状态定义
状态由7种参数组成,这组成Q函数神经网络的输入。
(1)平均机器使用率
(2)机器利用率的标准差
(3)工序完成率
(4)工件完成率
(5)工件完成率标准差
(6)拖延率
(7)平均拖延率
3.3 调度规则
提出了6种调度策略,分别作为神经网络的输出。
3.4 奖励函数的定义
奖励函数详情见伪代码:

4 算法总流程

以上是关于论文阅读|《用强化学习求解带插单的动态FJSP》的主要内容,如果未能解决你的问题,请参考以下文章