Linux从青铜到王者第四篇:Linux开发项目之编译器和调试器
Posted 森明帮大于黑虎帮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux从青铜到王者第四篇:Linux开发项目之编译器和调试器相关的知识,希望对你有一定的参考价值。

系列文章目录
文章目录
前言

一、Linux编译器-gcc/g++使用
1.背景知识
- 预处理(进行宏替换)
- 编译(生成汇编)
- 汇编(生成机器可识别代码)
- 连接(生成可执行文件或库文件)
2.gcc/g++如何完成
格式:gcc /g++[选项] 要编译的文件 [选项] [目标文件]
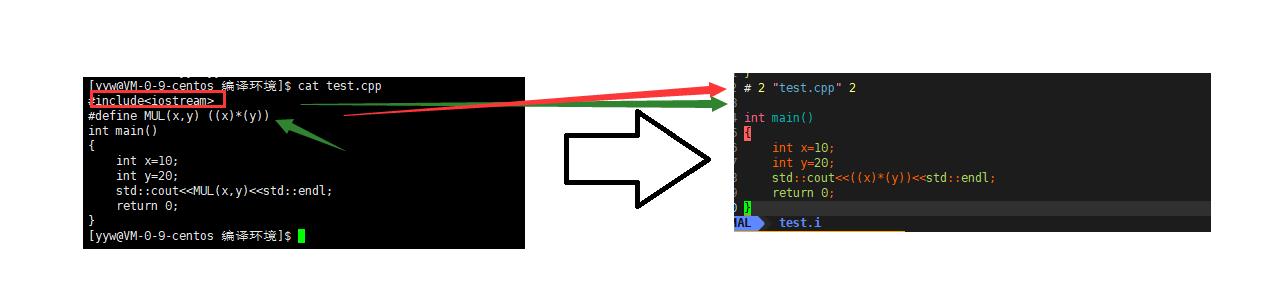
1.预处理(进行宏替换)
- 预处理功能主要包括宏定义,,头文件的展开文件包含,条件编译,去注释等。
- 预处理指令是以#号开头的代码行。
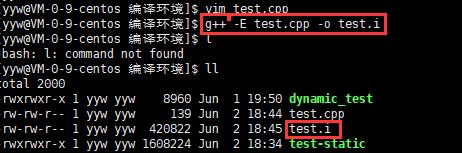
- 实例: g++ –E test.cpp –o test.i
- 选项“-E”,该选项的作用是让 gcc 在预处理结束后停止编译过程。
- 选项“-o”是指目标文件,“.i”文件为已经过预处理的C++原始程序
2.编译(生成汇编)
- 在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gcc 把代码翻译成汇编语言。
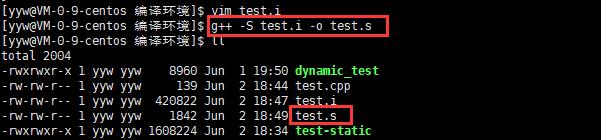
- 用户可以使用“-S”选项来进行查看,该选项只进行编译而不进行汇编,生成汇编代码。
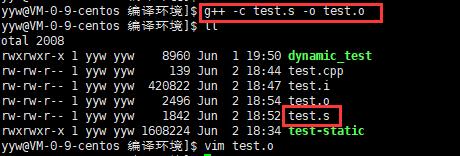
- 实例: g++ –S test.i –o test.s
3.汇编(生成机器可识别代码)
- 汇编阶段是把编译阶段生成的“.s”文件转成目标文件
- 读者在此可使用选项“-c”就可看到汇编代码已转化为“.o”的二进制目标代码了
- 实例: g++ –c test.s –o test.o
4.连接(生成可执行文件或库文件)
- 在成功编译之后,就进入了链接阶段。
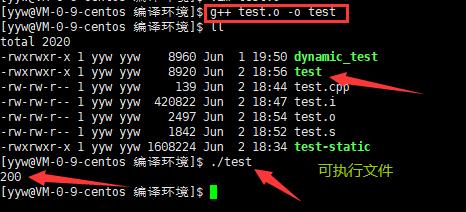
- 实例: g++ test.o –o test
5.重要的概念:函数库
- 我们的C++程序中,并没有定义“cout”的函数实现,且在预编译中包含的“iostream”中也只有该函数的声明,而没有定义函数的实现,那么,是在哪里实“cout”函数的呢?
- 最后的答案是:系统把这些函数实现都被做到名为 libc.so.6 的库文件中去了,在没有特别指定时,g++会到系统默认的搜索路径“/usr/lib”下进行查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数“cout”了,而这也就是链接的作用。
6.函数库分为静态库和动态库
-
静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为“.a”。
g++ test.cpp -o static_test -static。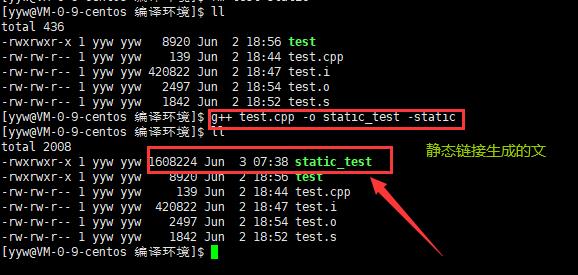
file static_test,查看文件属性

-
动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为 “.so”,如前面所述的 libc.so.6 就是动态库。g++ 在编译时默认使用动态库。完成了链接之后,g++ 就可以生成可执行文件,如下所示。 g++ test.o –o dynamic_test。在下图发生默认生成的动态链接所占内存相比静态链接小的多。
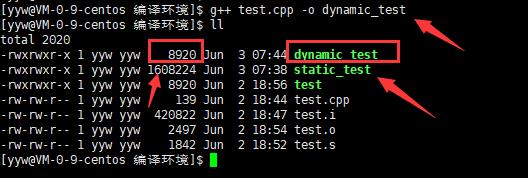
libc.so.6 就是动态库。

-
g++默认生成的二进制程序,是动态链接的,这点可以通过 file 命令验证。

7.gcc/g++选项
- -E 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面。
- -S 编译到汇编语言不进行汇编和链接。
- -c 编译到目标代码。
- -o 文件输出到 文件。
- -static 此选项对生成的文件采用静态链接。
- -g 生成调试信息。GNU 调试器可利用该信息。
- -shared 此选项将尽量使用动态库,所以生成文件比较小,但是需要系统由动态库。
- -O0。
- -O1。
- -O2。
- -O3 编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高。
- -w 不生成任何警告信息。
- -Wall 生成所有警告信息
二、Linux调试器-gdb使用
1.背景知识
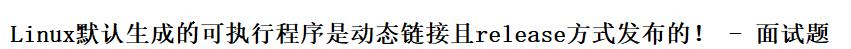
1. 程序的发布方式有两种,debug模式和release模式
2. Linux gcc/g++出来的二进制程序,默认是release模式
3. 要使用gdb调试,必须在源代码生成二进制程序的时候, 加上 -g 选项
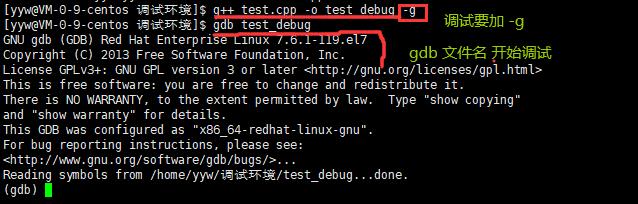
2. 开始使用
gdb binFile 退出: ctrl + d 或 quit 调试命令:
-
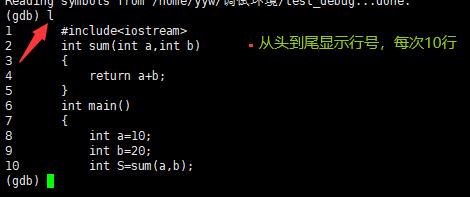
list/l 行号:显示binFile源代码,接着上次的位置往下列,每次列10行。
-
list/l 函数名:列出某个函数的源代码。
-
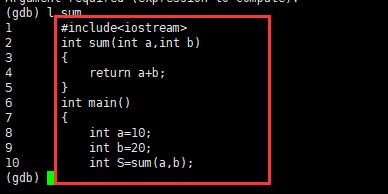
r或run:运行程序。

-
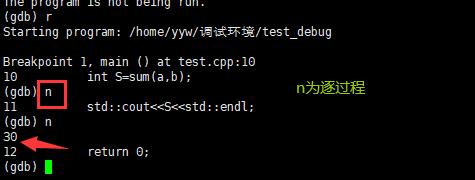
n 或 next:单条执行。逐过程
-
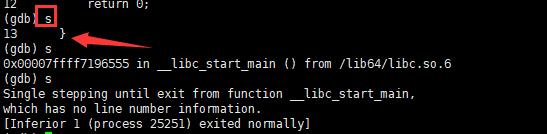
s或step:进入函数调用。逐语句
-
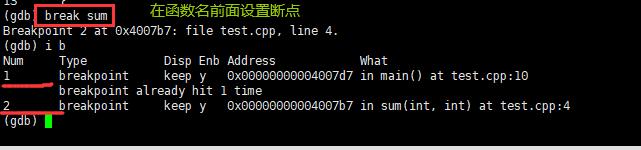
break(b) 行号:在某一行设置断点。

-
break 函数名:在某个函数开头设置断点。
-
info break :查看断点信息。

what是在哪里设置了断点。
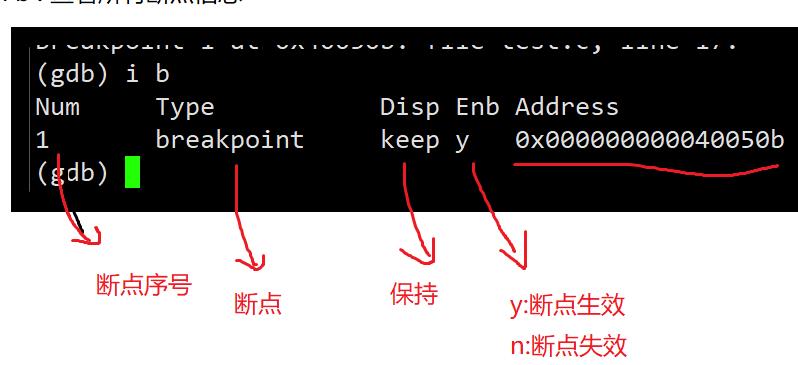
-
finish:执行到当前函数返回,然后挺下来等待命令。

-
print§:打印表达式的值,通过表达式可以修改变量的值或者调用函数。
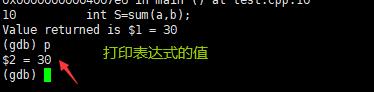
-
p 变量:打印变量值。

-
set var:修改变量的值。
-
continue(或c):从当前位置开始连续而非单步执行程序。
-
run(或r):从**开始连续而非单步执行程序。
-
delete breakpoints:删除所有断点。

-
delete breakpoints n:删除序号为n的断点。
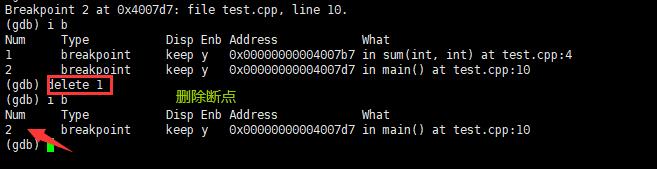
-
disable breakpoints:禁用断点。 disable 断点序号
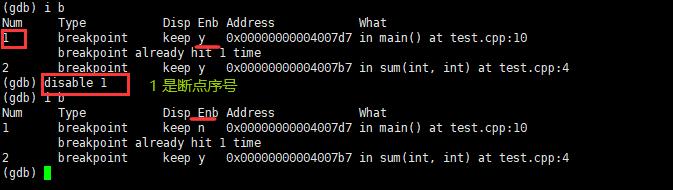
-
enable breakpoints:启用断点。enable 断点序号

-
info(或i) breakpoints:参看当前设置了哪些断点。

-
display 变量名:跟踪查看一个变量,每次停下来都显示它的值。
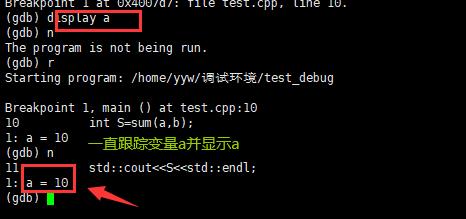
-
undisplay:取消对先前设置的那些变量的跟踪。
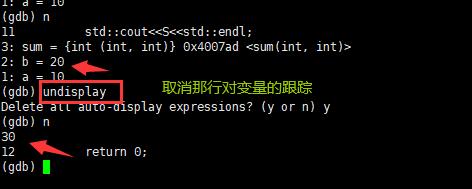
-
until X行号:跳至X行。
-
breaktrace(或bt):查看各级函数调用及参数。

-
info(i) locals:查看当前栈帧局部变量的值。
-
quit:退出gdb。
三、Linux项目自动化构建工具-make/Makefile
1.背景知识

-
会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力。
-
一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。
-
makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
-
make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
-
make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
2.原理实现
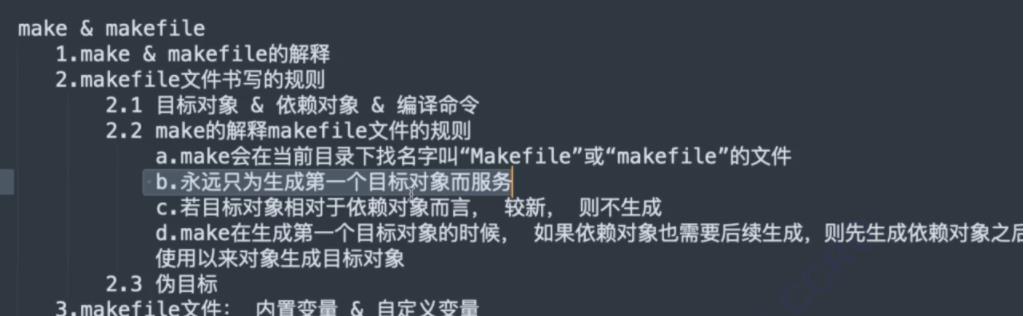
b.makefile永远只为生成第一个目标对象服务,如果有两个文件,只生成一个文件。
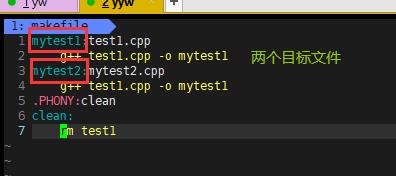
只生成mytest1。
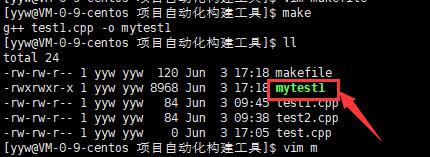
c.若目标对象相对于依赖对象较新,则不生成。此时mytest1实在test1.cpp后生成的,所以相对于依赖对象较新。
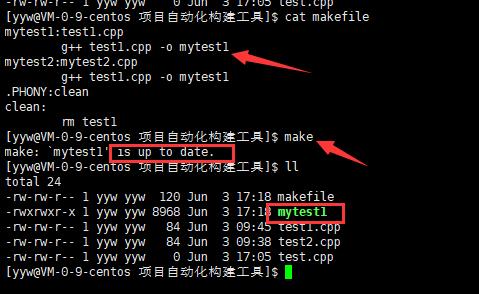
d.make生成第一个目标对象时候,如果依赖对象也需要后续生成的话,则先生成依赖对象,使用来生成目标对象。
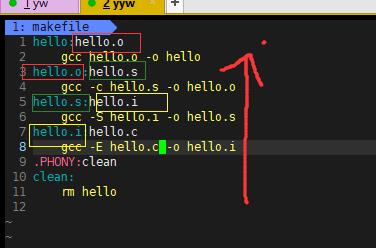
-
make会在当前目录下找名字叫“Makefile”或“makefile”的文件。
-
如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到“hello”这个文件,并把这个文件作为最终的目标文件。
-
如果test文件不存在,或是hello所依赖的后面的hello.o文件的文件修改时间要比hello这个文件新(可以用 touch 或者vim编辑或创建makefile文件),那么,他就会执行后面所定义的命令来生成hello这个文件。

-
如果hello依赖的hello.o文件不存在,那么make会在当前文件中找目标为hello.o文件的依赖性,如果找到则再根据那一个规则生成hello.o文件。(这有点像一个堆栈的过程)。
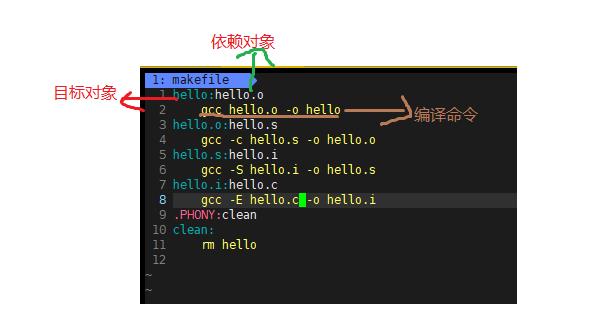
-
当然,你的C文件和H文件是存在的啦,于是make会生成 hello.o 文件,然后再用hello.o 文件声明make的终极任务,也就是执行文件test了。
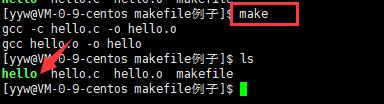
-
这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
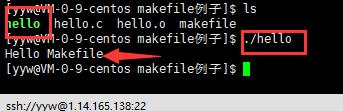
-
在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。
-
make只管文件的依赖性,即,如果在我找了依赖关系之后,冒号后面的文件还是不在,那么对不起,我就不工作啦。
3.项目清理
- 工程是需要被清理的。
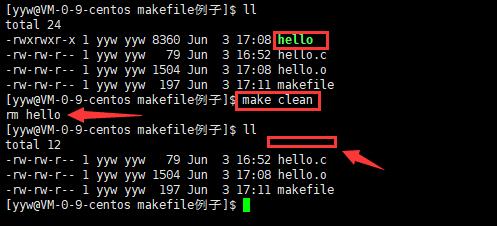
- 像clean这种,没有被第一个目标文件直接或间接关联,那么它后面所定义的命令将不会被自动执行,不过,我们可以显示要make执行。即命令——“make clean”,以此来清除所有的目标文件,以便重编译。
- 但是一般我们这种clean的目标文件,我们将它设置为伪目标,用 .PHONY 修饰,伪目标的特性是,总是被执行的。
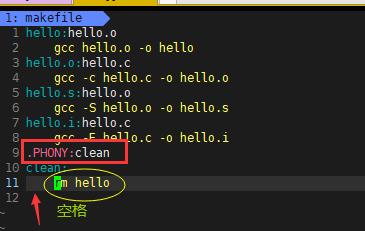
- 可以将我们的 hello目标文件声明成伪目标,测试一下。
4.内置变量和自定义变量
1.Makefile中的特殊宏定义:
-
$* 不包括后缀名的当前依赖文件的名称
-
$+ 所有的依赖文件,以空格分开,并以出现的先后为序,可能包含重复的依赖文件。
-
$< 第一个依赖文件的名称
-
$? 所有时间戳比目标文件晚的依赖文件,并以空格分开
-
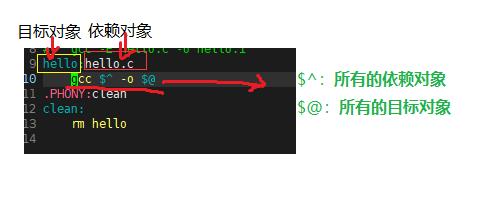
$@目标文件的完整名称 (当前所有目标对象)
-
$^ 所有不重复的目标依赖文件,以空格分开。 (当前所有依赖对象)
-
-:告诉make命令忽略所有的错误
-
@告诉make在执行命令前不要将改命令显示在标准输出上
2.内置变量
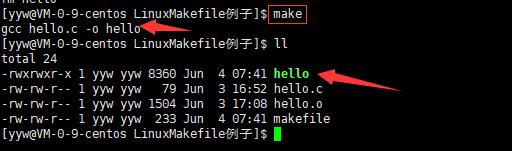
使用make也能生成hello的可执行文件。
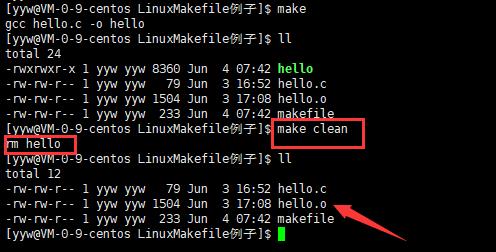
使用make clean也能清理hello的可执行文件。
3.自定义变量

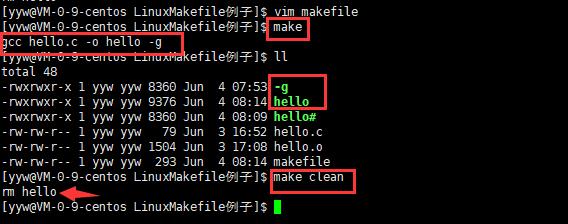
5.批量注释和批量化取消注释

四、Linux第一个小程序-进度条

1.回车和换行
- 回车概念
回车是回到当前行的最开始位置。 - 换行概念
换行是换到下一行位置
2.行缓冲区概念
1.什么现象
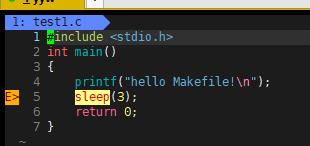
运行程序可以发现hello Makefile!先出来,后面一条过三秒在出来。

2.什么现象
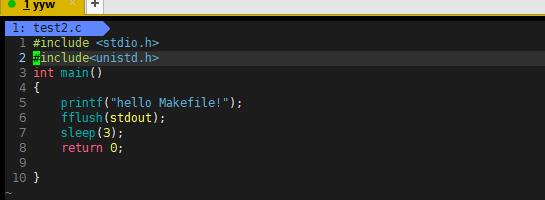
运行程序可以发生此时没有换行,后面一个过3秒后在hello Makefile!后出来。

3.进度条代码
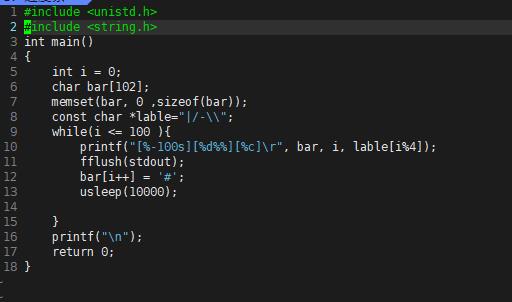

五、使用git命令行
1.安装git
suod yum install git
2.使用Github 创建项目
1.注册账号
这个比较简单, 参考着官网提示即可. 需要进行邮箱校验。
2.创建项目
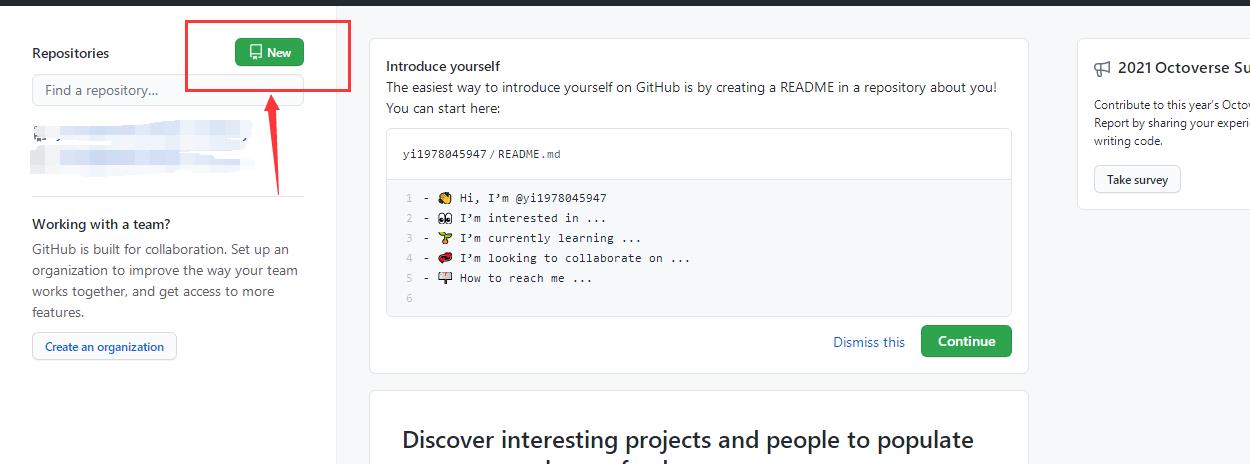
-
登陆成功后, 进入个人主页, 点击左下方的 New repository 按钮新建项目
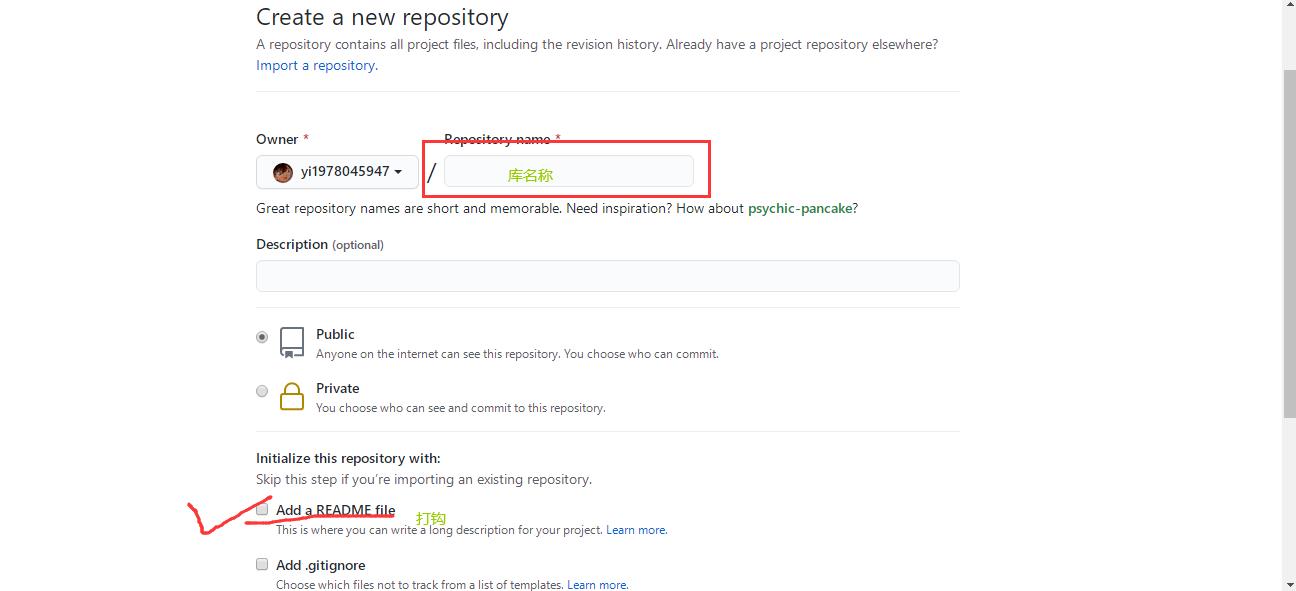
-
然后跳转到的新页面中输入项目名称(注意, 名称不能重复, 系统会自动校验. 校验过程可能会花费几秒钟). 校验完毕后, 点击下方的 Create repository 按钮确认创建。
-
在创建好的项目页面中复制项目的链接, 以备接下来进行下载。
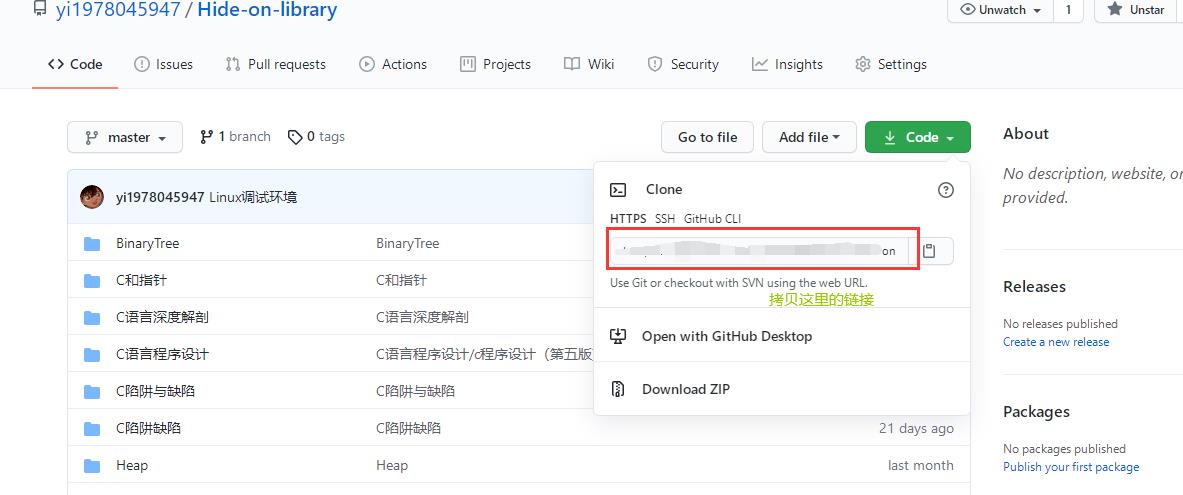
3.下载项目到本地
创建好一个放置代码的目录。
git clone url
1.三板斧第一招: git add
将代码放到刚才下载好的目录中
git add [文件名]
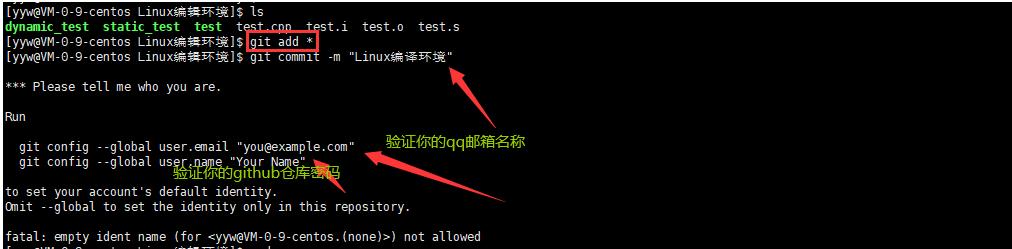
将需要用 git 管理的文件告知 git
2.三板斧第三招: git commit
提交改动到本地
git commit -m “日志名称”
提交的时候应该注明提交日志, 描述改动的详细内容
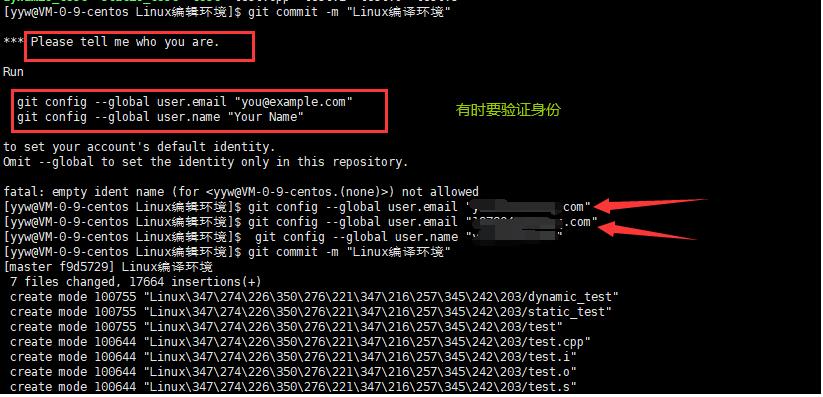
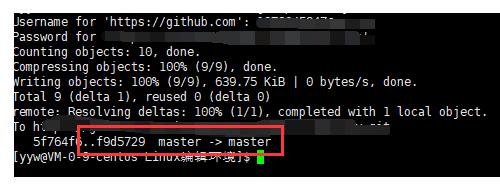
3.三板斧第三招: git push
同步到远端服务器上(github网站上)。
git push origin master

需要填入用户名密码. 同步成功后, 刷新 Github 页面就能看到代码改动了。
总结
以上就是今天要讲的内容,本文仅仅简单介绍了Linux后序工具的使用,而前面的文章和今天的文章讲解的工具提供了大量能使我们快速便捷地处理数据的函数和方法,我们务必掌握,到现在,Linux也算可以入门,接下来的文章才是重中之中。另外如果上述有任何问题,请懂哥指教,不过没关系,主要是自己能坚持,更希望有一起学习的同学可以帮我指正,但是如果可以请温柔一点跟我讲,爱与和平是永远的主题,爱各位了。

以上是关于Linux从青铜到王者第四篇:Linux开发项目之编译器和调试器的主要内容,如果未能解决你的问题,请参考以下文章