面试怎么能不了解分库分表
Posted 大道测试
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试怎么能不了解分库分表相关的知识,希望对你有一定的参考价值。
根据经验单表几百万、两三千万的数量对于数据库是没什么压力的,淘宝日订单量在5000万单以上,数据库面对海量的数据压力,分库分表就是必须进行的操作了。
测试对分表的预期结果判断
假设,用户表根据ID%6,分为6张表。验证预期结果时,需要查看某个用户的相关信息,测试环境数据量较小时,就可以通过创建视图,简单粗暴的来使用。
创建视图来查询
CREATE VIEW user_view AS
SELECT*FROM user_0 UNION
SELECT*FROM user_1 UNION
SELECT*FROM user_2 UNION
SELECT*FROM user_3 UNION
SELECT*FROM user_4 UNION
SELECT*FROM user_5;通过查询视图校验需要查询的数据
SELECT * FROM user_view WHERE username="张三";分库分表的关键逻辑
全局唯一主键
一般我们数据库的主键都是自增的,那么分表之后主键冲突的问题就是一个无法避免的问题,最简单的办法就是以一个唯一的业务字段作为唯一的主键,比如订单表的订单号肯定是全局唯一的。常见的分布式生成唯一ID的方式很多,最常见的雪花算法Snowflake、滴滴Tinyid、美团Leaf。以雪花算法举例来说,一毫秒可以生成4194304多个ID。
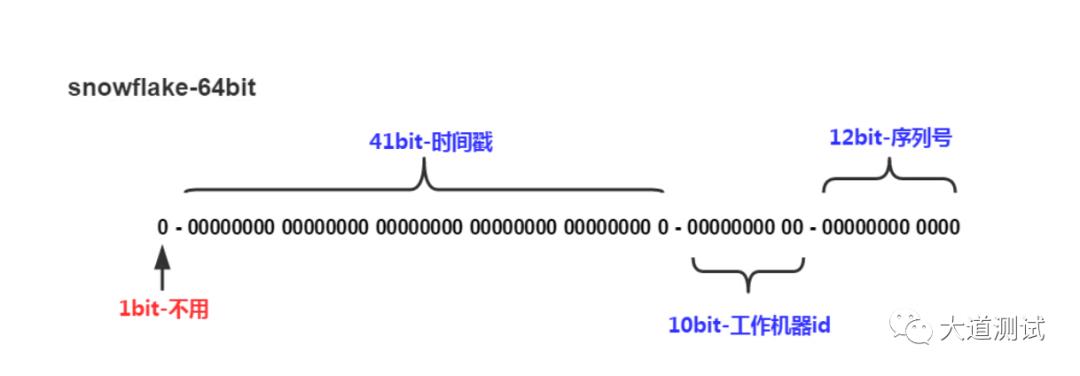
确定分表数量
第一步,分表后要怎么保证订单号的唯一搞定了,现在考虑下分表的问题。首先根据自身的业务量和增量来考虑分表的大小。
举个例子,现在我们日单量是10万单,预估一年后可以达到日100万单,根据业务属性,一般我们就支持查询半年内的订单,超过半年的订单需要做归档处理。
那么以日订单100万半年的数量级来看,不分表的话我们订单量将达到100万X180=1.8亿,以这个数据量级部分表的话肯定单表是扛不住的,就算你能扛RT的时间你也根本无法接受吧。根据经验单表几百万的数量对于数据库是没什么压力的,那么只要分256张表就足够了,1.8亿/256≈70万,如果为了保险起见,也可以分到512张表。那么考虑一 下,如果业务量再增长10倍达到1000万单每天,分表1024就是比较合适的选择。
通过分表加上超过半年的数据归档之后,单表70万的数据就足以应对大部分场景了
分库分表后数据查询
根据全局主键(订单号等)确定数据所在表,然后发起查询。
根据业务查询所需要的维度,通过双写根据新的维度(比如客户id)重新建立全局主键,分表保存,方便后续查询。
通过构建离线数仓或者ES,有效聚合数据,来进行数据查询。
扫一扫,关注我
若有收获,点个在看 以上是关于面试怎么能不了解分库分表的主要内容,如果未能解决你的问题,请参考以下文章