为何选择Cassandra数据库
Posted 数融咖啡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为何选择Cassandra数据库相关的知识,希望对你有一定的参考价值。
Cassandra 是一个来自 Apache 的分布式数据库,具有高度可扩展性,可用于管理大量的结构化数据。它提供了高可用性,没有单点故障。
在lambda架构里,作者选用的Cassandra作为速度层的组件,重要的考虑是速度快,大数据量。
据说有的公司转redis到Cassandra,有的据说是Facebook Twitter也转Cassandra到别的,比较多的是和hbase和redis等进行比较选择,当然uc 伯克利据说还有新的开源出现了。
架构的选择真是令人纠结,再看着别人各种看着有理的组合以及不断的变迁,就是感觉如何比较才是如选房一样。
数据模型
Cassandra 中数据的最外层是定义为一个键空间,类似redis的结构体。Cassandra 中的一个键空间的基本属性是 -
复制因子 - 它是集群中将接收相同数据副本的计算机数。
副本放置策略 - 它只是把副本放在戒指中的策略。我们有简单策略(机架感知策略),旧网络拓扑策略(机架感知策略)和网络拓扑策略(数据中心共享策略)等策略。
列族 - 键空间是一个或多个列族的列表的容器。列族又是一个行集合的容器。每行包含有序列。列族表示数据的结构。每个键空间至少有一个,通常是许多列族。这和hbase类似。
创建键空间的语法如下 -
CREATE KEYSPACE Keyspace name
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};
下图显示了键空间的示意图。
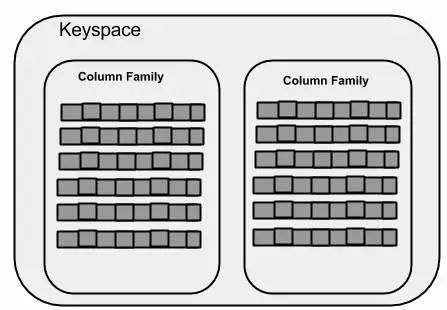
Cassandra本质上不是行存储也不是列,更像是稀疏矩阵的存储方式,
列族
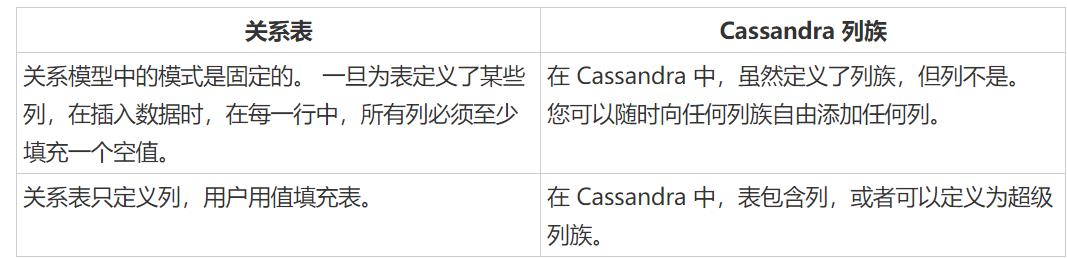
列族是有序收集行的容器。每一行又是一个有序的列集合。下表列出了区分列系列和关系数据库表的要点。
keys_cached - 它表示每个 SSTable 保持缓存的位置数。
rows_cached - 它表示其整个内容将在内存中缓存的行数。
preload_row_cache -它指定是否要预先填充行缓存。
注 - 与不是固定列族的模式的关系表不同,Cassandra 不强制单个行拥有所有列。
下图显示了 Cassandra 列族的示例。
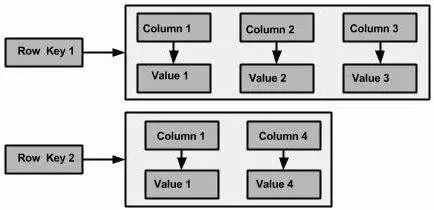
列
列是 Cassandra 的基本数据结构,具有三个值,即键或列名称,值和时间戳。下面给出了列的结构。

超级列
超级列是一个特殊列,因此,它也是一个键值对。但是超级列存储了子列的地图。
通常列族被存储在磁盘上的单个文件中。因此,为了优化性能,重要的是保持您可能在同一列族中一起查询的列,并且超级列在此可以有所帮助。下面是超级列的结构。

Cassandra 和 RDBMS 的数据模型对比
这样的结构就会让人想到可否替代redis或是hbase ,这里一个原因是也有key-value的模式,也具有列族的存储方式。
加上存储在磁盘,有更好的持久化能力,所以作为视图层也是理所当然,同时很适合实时事务处理,所以像电商的订单或是很多银行和金融业对于实时写入读取都有要求的比较多选择Cassandra。
对这里看到了 ,他结合了两种的特点,我们可以从他们的底层架构看它的来源
分布式、去中心、可扩展性
从大数据的开源历史看,原点应该说是著名的Google的三篇论文还有一个其实是amazon的dynamo论文,
这两个论文就是对于海量数据存储的解决方法的理论来源,他们共同的基本思想是要是的数据分布,并且使用的是性能不好,容易失效或损坏的廉价机器上,所以对于分布式,容错和可扩展性是主要考虑的问题,也要使得应用看上去是可用,虽然下面可能都在不断处理问题。
cassandra不仅吸收了dynamo论文中的如何做分布式,如何做副本复制,故障容错等方面成功的经验,又吸取了google bigtable中的LSM单机引擎层面精华,应该说是理论结合到工程实践的最佳案例。
dynamo的分布式是基于去中心化的集群模式,也就是各个节点地位一样,通过一致性哈希等一致性算法,使得数据存入保持一致,由于是集群模式,所以线性扩展非常方便,也不会太复杂。
而bigtable一般是主从结构,而且还有管理节点集群,会有单点问题,同时也增加了复杂度。
Cassandra选择了前者的优势,同时Cassandra的gossip算法使得集群模式更加快速。
另外可以处理的数据量更多,Facebook和instangram一天用Cassandra处理上亿图片。
一致化的软硬件环境也是一个大优点,易于大规模部署
不像hadoop需要hdfs等存储,同时又是p2p的对等架构,在实际部署时候非常统一方便运维。
同时Cassandra也是高度容错的,没有单点故障,可以做到不停服滚动升级,当然也是可以配置管理,是可选择的,因为一般它认为故障大部分是短时可修复,不一定要进行数据迁移,可以选择不做切换。
Cassandra也易于集成spark ,kafka等组件
也是开源可控的
redis和Cassandra
虽然redis有好的读取速度,但是内存和持久化还是个大问题
因为redis持久化需要经过一个操作系统的buffer IO,也就是有个中间的缓存,和其 它磁盘数据库不同,所以容易带来效率和安全的问题。
虽然redis 的cluster模式和Cassandra很接近,但是也是gossip ,却不具有好的可控性,这也是不容易做实时事务的原因,相对于数据可用性较高的比如金融业比较不合适,扩展Cassandra比redis简单的多。
当然最后内存的费用肯定更高,并且内存和swap的空间肯定不如磁盘。
Cassandra和hbase
Cassandra对于高速写入的吞吐量场景是更理想的选择,而hbase更适合做数据管理,而不是实时事务,写的速度慢,因为需要经过zk ,metatable再到region sever等
hbase不是对等架构,需主从节点,同时还有控制组也就是zookeeper,可能有单点问题,集群较复杂
Cassandra是高可用系统,就是AP 可以改变参数成为CP,HBASE是CP,适合一致性高的场景
总体比较,hbase在一致性和查询scan更有优势。读多写少
Cassandra适合写多读少,比如银行系统
以上是关于为何选择Cassandra数据库的主要内容,如果未能解决你的问题,请参考以下文章