ResT解读
Posted 周先森爱吃素
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ResT解读相关的知识,希望对你有一定的参考价值。
最近的一篇基于Transformer的工作,由南京大学的研究者提出一种高效的视觉Transformer结构,设计思想类似ResNet,称为ResT,这是我个人觉得值得关注的一篇工作。
简介
ResT是一个高效的多尺度视觉Transformer结构,可以作为图像识别的通用骨干网络,它采用类似ResNet的设计思想,分阶段捕获不同尺度的信息。不同于现有的Transformer方法只使用标准的Transformer block来处理具有固定分辨率的原始图像,ResT有着几个优势:提出一种内存高效的多头自注意力,使用深度卷积进行内存压缩,并且跨注意力头的维度投影交互同时保持多头的多样性能力;将位置编码构建为空间注意力,它可以以更加灵活的方式处理任意尺寸的输入而无需插值或者微调;不同于直接在每个阶段开始进行序列化,而是将patch embedding设计为一系列重叠的有stride的卷积操作。作者在图像分类以及下游任务中验证了ResT的性能,结果表明,ResT大幅度优于当前SOTA骨干网络,在ImageNet数据集上,同等计算量前提下,所提方法取得了优于PVT、Swin。
-
论文标题
ResT: An Efficient Transformer for Visual Recognition
-
论文地址
https://arxiv.org/abs/2105.13677
-
论文源码
https://github.com/wofmanaf/ResT
介绍
用于提取图像特征的骨干网络(backbone)在计算机视觉任务中至关重要,好的特征有利于下游任务的展开,如图像分类、目标检测、实例分割等。如今,计算机视觉中主要有两种骨干网络结构,一种是卷积神经网络结构,一种是Transformer结构,它们都是堆叠多个块(block)来捕获特征信息的。
CNN block通常是一个bottleneck结构,可以定义为堆叠的1x1卷积、3x3卷积和1x1卷积配合一个残差连接,如下图的(a)所示。两个1x1卷积分别用于通道降维和通道升维,保证3x3卷积处理的特征图通道数不会太高。CNN骨干网络通常更快一些,这主要得益于参数共享、局部信息聚合以及维度缩减,然而,受限于有限且固定的感受野,卷积网络在那些需要长程依赖的场景中效果并不好,比如实例分割中,从一个更大的邻域中收集并关联目标间的关系是很重要的。
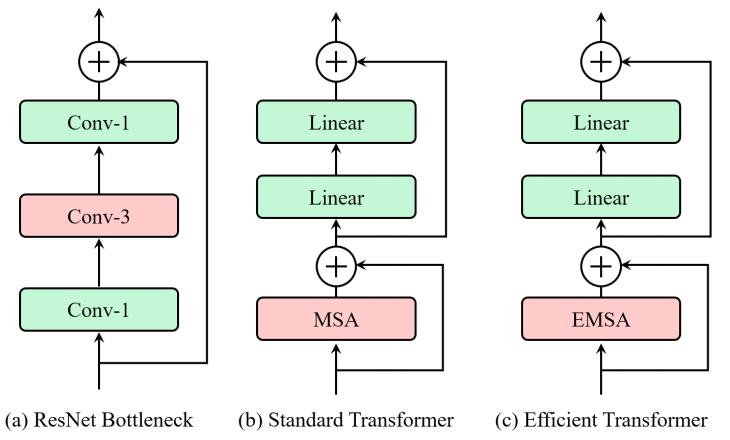
为了克服这些限制,能够捕获长程信息的Transformer结构最近被探索用于设计骨干网络。不同于CNN网络,Transformer网络首先是将图片切分为一系列块(patch,也叫token),然后将这些token和位置编码相加来表示粗糙的空间信息,最终采用堆叠的Transformer block来捕获特征信息。一个标准的Transformer block由一个多头自注意力(multi-head self-attention,MSA)和一个前馈神经网络(feed-forward network,FFN)构成,其中MSA通过query-key-value分解来建模token之间的全局依赖,FFN则用来学习更宽泛的表示。Transformer block的结构如上图的(b)所示,它能够根据图像内容自适应调整感受野。
虽然相比于CNN backbone。Transformer backbone潜力巨大,但它依然有四个主要的缺点如下。
- 由于现有的Transformer backbone直接对原始输入图像中的块进行序列化,因此很难提取形成图像中一些基本结构(例如,角和边缘)的低级特征。
- Transformer block中MSA的内存和计算与空间或通道维度成二次方扩展,导致大量的训练和推理开销。
- MSA 中的每个head只负责输入token的一个子集,这可能会损害网络的性能,特别是当每个子集中的通道维度太低时,使得query和key的点积无法构成信息函数。
- 现有 Transformer backbone中的输入token和位置编码都是固定规模的,不适合需要密集预测的视觉任务。
在这篇论文中,作者提出一种高效的通用backbone ResT(以ResNet命名),该结构可以解决上述的问题,这个结构会在下一节具体说明。
ResT
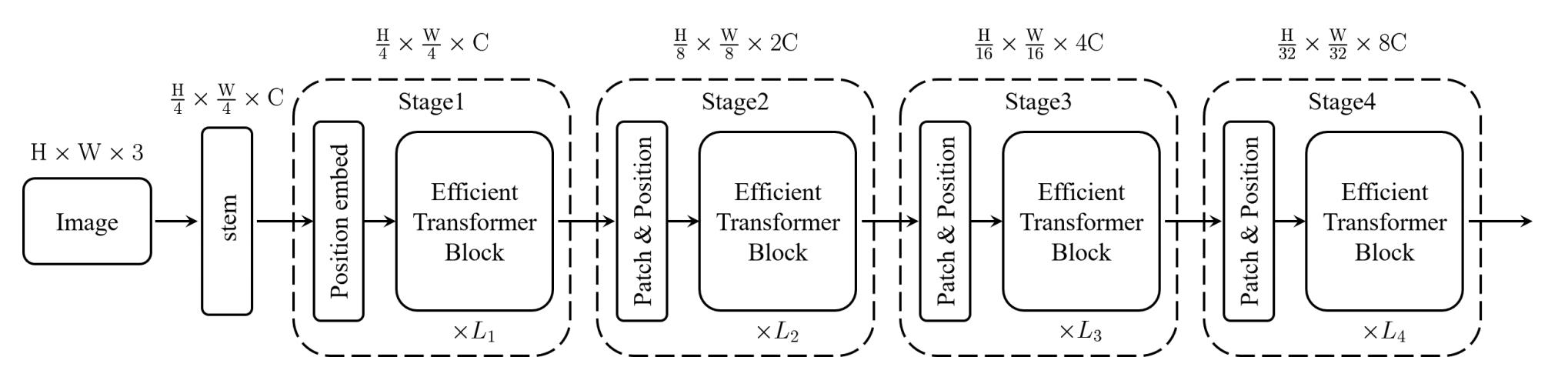
上图所示的即为ResT的结构图,可以看到,它和ResNet有着非常类似的pipeline,即采用一个stem模块来提取底层特征,然后跟着四个stage捕获多尺度特征。每个stage由三个组件构成,一个patch embedding模块,一个position encoding模块以及L个efficient Transformer block。具体而言,在每个stage的开始,patch embedding模块用来减少输入token的分辨率并且拓展通道数。位置编码模块则被融合进来用于抑制位置信息并且加强patch embedding的特征提取能力。这两个阶段完成之后,输入token被送入efficient Transformer block。
Rethinking of Transformer Block
标准的Transformer block包含两个子层,分别是MSA和FFN,每个子层包围着一个残差连接。在MSA和FFN前,先经过了一个layer normalization(下面简称LN)。假定输入token为 x ∈ R n × d m \\mathrm{x} \\in \\mathbb{R}^{n \\times d_{m}} x∈Rn×dm,这里的 n n n和 d m d_m dm分别表示空间维度和通道维度,每个Transformer block的输出表示如下。
y = x ′ + F F N ( L N ( x ′ ) ) , and x ′ = x + M S A ( L N ( x ) ) \\mathrm{y}=\\mathrm{x}^{\\prime}+\\mathrm{FFN}\\left(\\mathrm{LN}\\left(\\mathrm{x}^{\\prime}\\right)\\right), \\text { and } \\mathrm{x}^{\\prime}=\\mathrm{x}+\\mathrm{MSA}(\\mathrm{LN}(\\mathrm{x})) y=x′+FFN(LN(x′)), and x′=x+MSA(LN(x))
对上面的式子,我们先来看MSA,它首先通过三组线性投影获取query Q \\mathbf{Q} Q、key K \\mathbf{K} K和value V \\mathbf{V} V,每组投影有 k k k个线性层(即heads)将 d m d_m dm映射到 d k d_k dk的空间中,这里 d k = d m / k d_{k}=d_{m} / k dk=dm/k。为了描述方便,后续所有的说明都是基于 k = 1 k=1 k=1,因此MSA可以简化为单头注意力(SA),token序列之间的全局关系可以定义为下式,每个head的输出concatenate到一起之后经过线性投影得到最终输出。可以得知,MSA的计算复杂度为 O ( 2 d m n 2 + 4 d m 2 n ) \\mathcal{O}\\left(2 d_{m} n^{2}+4 d_{m}^{2} n\\right) O(2dmn2+4dm2n),它根据输入token的空间维度或者通道维度次方级变化。
S A ( Q , K , V ) = Softmax ( Q K T d k ) V \\mathrm{SA}(\\mathbf{Q}, \\mathbf{K}, \\mathbf{V})=\\operatorname{Softmax}\\left(\\frac{\\mathbf{Q K}^{\\mathrm{T}}}{\\sqrt{d_{k}}}\\right) \\mathbf{V} SA(Q,K,V)=Softmax(dkQKT)V
接着,来看FFN,它主要用于特征转换和非线性,通常由两个线性层和一个非线性激活函数构成,第一层将输入的通道数从 d m d_m dm拓展到 d f d_f df,第二层则从 d f d_f df降到 d m d_m dm。数学上表示如下式,其中 W 1 ∈ R d m × d f \\mathbf{W}_{1} \\in \\mathbb{R}^{d_{m} \\times d_{f}} W1∈Rdm×df且 W 2 ∈ R d f × d m \\mathbf{W}_{2} \\in \\mathbb{R}^{d_{f} \\times d_{m}} W2∈Rdf×dm为两个线性层的权重, b 1 ∈ R d f \\mathbf{b}_{1} \\in \\mathbb{R}^{d_{f}} b1∈Rdf和 b 2 ∈ R d m \\mathbf{b}_{2} \\in \\mathbb{R}^{d_{m}} b2∈Rdm则是相应的偏置项, σ ( ⋅ ) \\sigma(\\cdot) σ(⋅)表示GELU激活函数。标准的Transformer block中,通道数通常4倍扩大,即 d f = 4 d m d_{f}=4 d_{m} df=4dm。FFN的计算代价为 8 n d m 2 8 n d_{m}^{2} 8ndm2。
F F N ( x ) = σ ( x W 1 + b 1 ) W 2 + b 2 \\mathrm{FFN}(\\mathrm{x})=\\sigma\\left(\\mathrm{x} \\mathbf{W}_{1}+\\mathbf{b}_{1}\\right) \\mathbf{W}_{2}+\\mathbf{b}_{2} FFN(x)=σ(xW1+b1)W2+b2
Efficient Transformer Block
如上面所述,MSA有两个缺点,第一是其计算量是二次方倍的,这给训练和推理都带来了不小的负担;第二,MSA中的每个head只负责输入token序列的一个子集,当通道数比较少的时候这个会损害模型的表现。
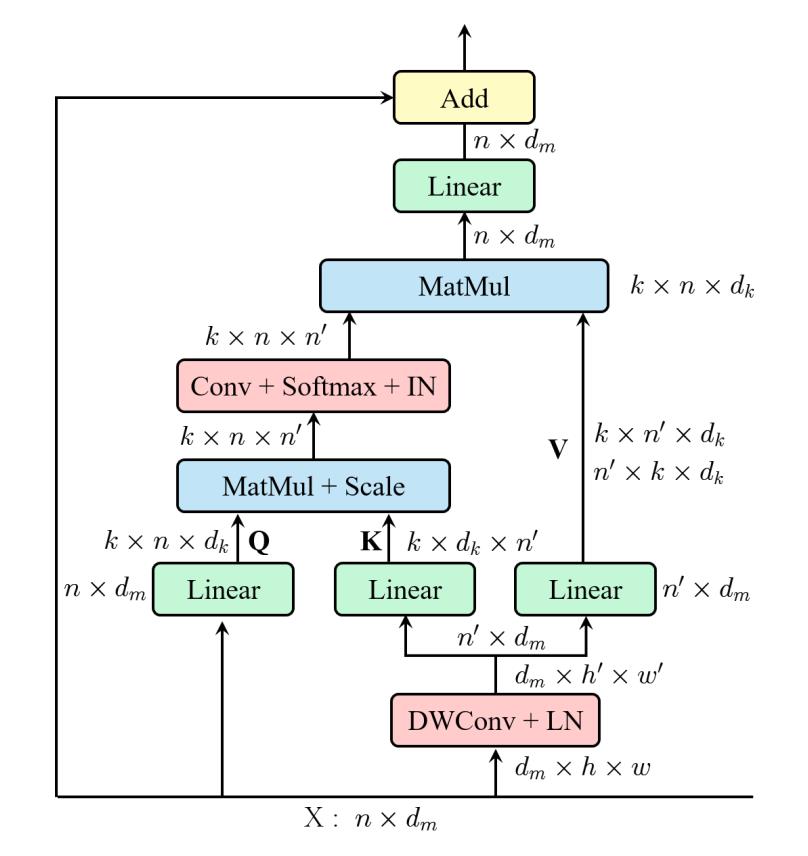
为了解决这些问题,作者提出了一种高效的多头自注意力模块,如上图所示。和MSA类似,EMSA首先采用一组投影获取query Q \\mathbf{Q} Q。为了压缩内存,2D输入的token x ∈ R n × d m \\mathrm{x} \\in \\mathbb{R}^{n \\times d_{m}} x∈Rn×dm会被沿着空间维度reshape为3D形式( x ^ ∈ R d m × h × w \\hat{\\mathrm{x}} \\in \\mathbb{R}^{d_{m} \\times h \\times w} x^∈Rdm×h×w)然后送入深度可分离卷积中按照因子 s s s降低宽高,为了简单, s s s根据 k k k自适应为 s = 8 / k s=8 / k s=8/ResT解读