大数据(8m)计算1小时内最大流量
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据(8m)计算1小时内最大流量相关的知识,希望对你有一定的参考价值。
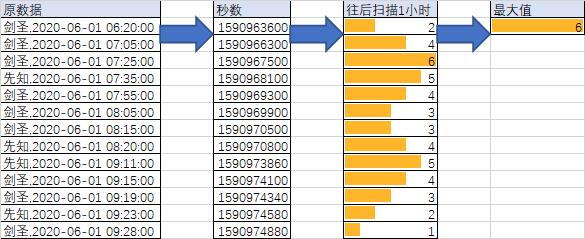
需求

Python实现
import time
# 1小时的秒数
INTERVAL = 3600
# 原始数据
data = '''
剑圣,2020-06-01 06:20:00
剑圣,2020-06-01 07:05:00
剑圣,2020-06-01 07:25:00
先知,2020-06-01 07:35:00
剑圣,2020-06-01 07:55:00
剑圣,2020-06-01 08:05:00
剑圣,2020-06-01 08:15:00
先知,2020-06-01 08:20:00
先知,2020-06-01 09:11:00
剑圣,2020-06-01 09:15:00
剑圣,2020-06-01 09:19:00
先知,2020-06-01 09:23:00
剑圣,2020-06-01 09:28:00
'''.strip()
# 数据处理,提取时间
time_ls = []
for line in data.split('\\n'):
name, t = line.split(',')
t = time.mktime(time.strptime(t, '%Y-%m-%d %H:%M:%S'))
time_ls.append(t)
# 计算每个时间节点往后1小时内的总流量
interval_counts = []
length = len(time_ls)
for i in range(length):
interval_count = 1
for j in range(i + 1, length):
# 计算时间差
if time_ls[j] - time_ls[i] < INTERVAL:
interval_count += 1
else:
break
interval_counts.append(interval_count)
print(interval_counts)
# 计算1小时内最大流量
max_density = max(interval_counts)
print(max_density)
SparkSQL实现
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
// 创建SparkSession对象
val c1: SparkConf = new SparkConf().setAppName("a1").setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(c1).getOrCreate()
// 隐式转换支持
import spark.implicits._
// 原始数据
val df = Seq(
("剑圣", "2020-06-01 06:20:00"),
("剑圣", "2020-06-01 07:05:00"),
("剑圣", "2020-06-01 07:25:00"),
("先知", "2020-06-01 07:35:00"),
("剑圣", "2020-06-01 07:55:00"),
("剑圣", "2020-06-01 08:05:00"),
("剑圣", "2020-06-01 08:15:00"),
("先知", "2020-06-01 08:20:00"),
("先知", "2020-06-01 09:11:00"),
("剑圣", "2020-06-01 09:15:00"),
("剑圣", "2020-06-01 09:19:00"),
("先知", "2020-06-01 09:23:00"),
("剑圣", "2020-06-01 09:28:00"),
).toDF("name", "hms")
// 创建视图
df.createTempView("pv")
// 自联结
spark.sql(
"""
|SELECT
| t0.hms,
| count(1) c
|FROM pv t0
|INNER JOIN pv t1 ON
| (UNIX_TIMESTAMP(t1.hms) >= UNIX_TIMESTAMP(t0.hms))
| AND
| (UNIX_TIMESTAMP(t1.hms) - UNIX_TIMESTAMP(t0.hms) < 3600)
|GROUP BY t0.hms
|""".stripMargin).createTempView("pv_count")
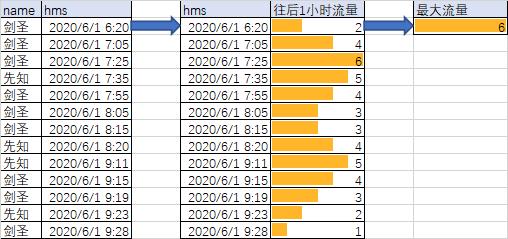
spark.sql("SELECT * FROM pv_count ORDER BY hms").show()
// 取出最大值
spark.sql("SELECT MAX(c) FROM pv_count").show()
SQL
SELECT
t0.hms,
count(1) c
FROM pv t0
INNER JOIN pv t1 ON
(UNIX_TIMESTAMP(t1.hms) >= UNIX_TIMESTAMP(t0.hms))
AND
(UNIX_TIMESTAMP(t1.hms) - UNIX_TIMESTAMP(t0.hms) < 3600)
GROUP BY t0.hms
以上是关于大数据(8m)计算1小时内最大流量的主要内容,如果未能解决你的问题,请参考以下文章