Spark推荐系列之Word2vec算法介绍实现和应用说明
Posted Thinkgamer_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark推荐系列之Word2vec算法介绍实现和应用说明相关的知识,希望对你有一定的参考价值。
Spark推荐实战系列目前已经更新:
- Spark推荐实战系列之Swing算法介绍、实现与在阿里飞猪的实战应用
- Spark推荐实战系列之ALS算法实现分析
- Spark中如何使用矩阵运算间接实现i2i
- FP-Growth算法原理、Spark实现和应用介绍
- Spark推荐系列之Word2vec算法介绍、实验和应用说明
更多精彩内容,请持续关注「搜索与推荐Wiki」!
1. 背景
word2vec 是Google 2013年提出的用于计算词向量的工具,在论文Efficient Estimation of Word Representations in Vector Space中,作者提出了Word2vec计算工具,并通过对比NNLM、RNNLM语言模型验证了word2vec的有效性。
word2vec工具中包含两种模型:CBOW和skip-gram。论文中介绍的比较简单,如下图所示,CBOW是通过上下文的词预测中心词,Skip-gram则是通过输入词预测上下文的词。
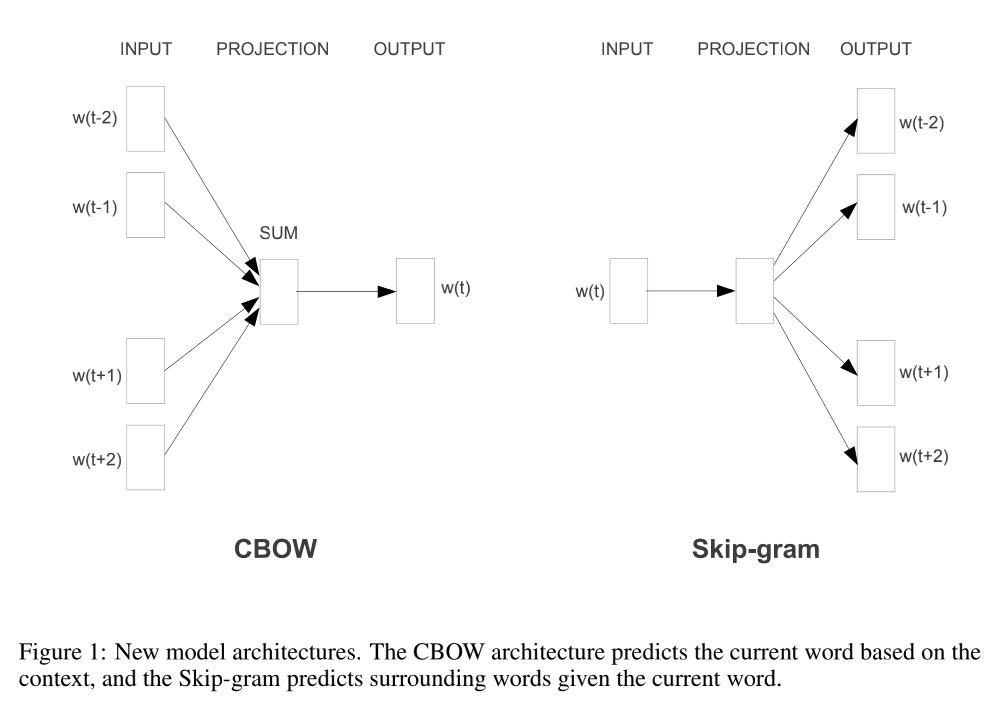
Word2vec 开启了Embedding的相关工作,自从embedding开始大规模走进推荐系统中,下面我们就来看一下Word2vec算法的原理、Spark实现和应用说明。
2. 算法原理
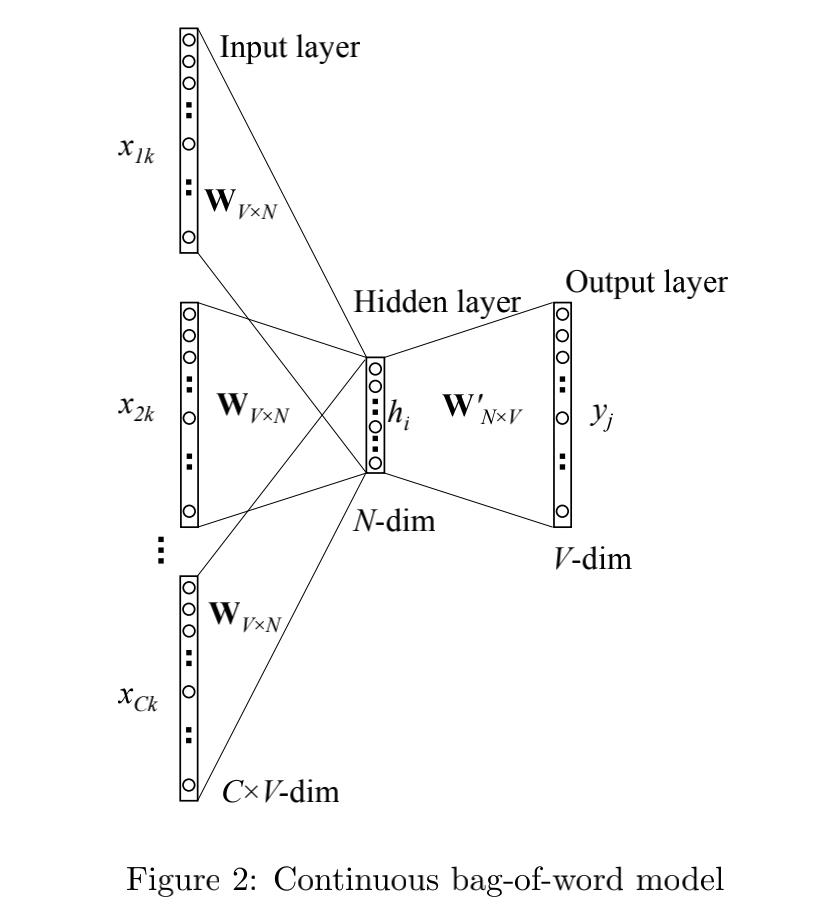
Word2vec包含了两种模型,分别是CBOW和Skip-gram,CBOW又分为:
- One-word context
- multi-word context
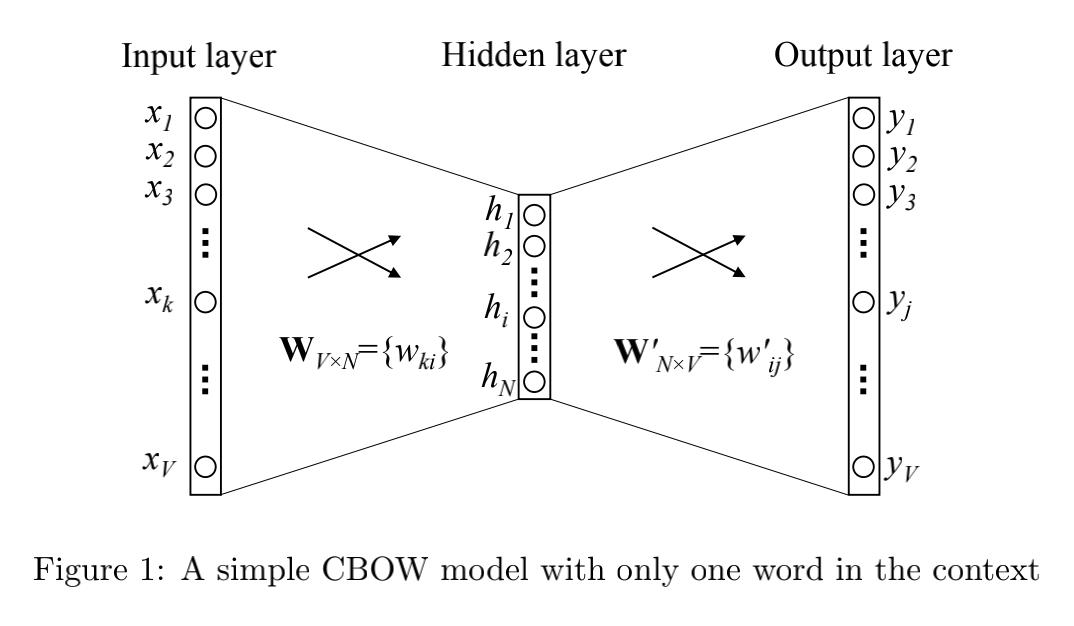
其中单词的总个数为 V V V,隐藏层的神经元个数为 N N N,输入层到隐藏层的权重矩阵为 W V ∗ N W_{V*N} WV∗N,隐藏层到输出层的权重矩阵为 W N ∗ V ′ W'_{N*V} WN∗V′。
此时的
h
h
h 表达式为:
h
=
1
C
W
T
(
x
1
+
x
2
+
.
.
.
.
+
x
C
)
=
1
C
(
v
w
1
+
v
w
2
+
.
.
.
+
v
w
C
)
T
h = \\frac{1}{C} W^T (x_1 + x_2 + .... + x_C) \\\\ = \\frac{1}{C} (v_{w_1} + v_{w_2}+ ... + v_{w_C})^T
h=C1WT(x1+x2+....+xC)=C1(vw1+vw2+...+vwC)T
其中
C
C
C 表示上下文单词的个数,
w
1
,
w
2
,
.
.
.
,
w
C
w_1, w_2, ..., w_C
w1,w2,...,wC 表示上下文单词,
v
w
v_w
vw 表示单词的输入向量(注意和输入层
x
x
x区别)。
目标函数为:
E
=
−
l
o
g
p
(
w
O
∣
w
I
1
,
w
I
2
,
.
.
.
,
w
I
C
)
=
−
u
j
∗
l
o
g
∑
j
′
=
1
V
e
x
p
(
u
j
′
)
=
−
(
v
w
O
′
)
T
∗
h
+
l
o
g
∑
j
′
=
1
V
e
x
p
(
(
v
w
j
′
)
T
∗
h
)
E = -log \\, p(w_O | w_{I_1}, w_{I_2}, ..., w_{I_C}) \\\\ = - u_j * log \\sum_{j'=1}^{V} exp(u_j') \\\\ = -(v'_{w_O})^T * h + log \\sum_{j'=1}^{V} exp((v'_{w_j})^T * h)
E=−logp(wO∣wI1,wI2,...,wIC)=−uj∗logj′=1∑Vexp(uj′)=−(vwO′)T∗h+logj′=1∑Vexp((vwj′)T∗h)
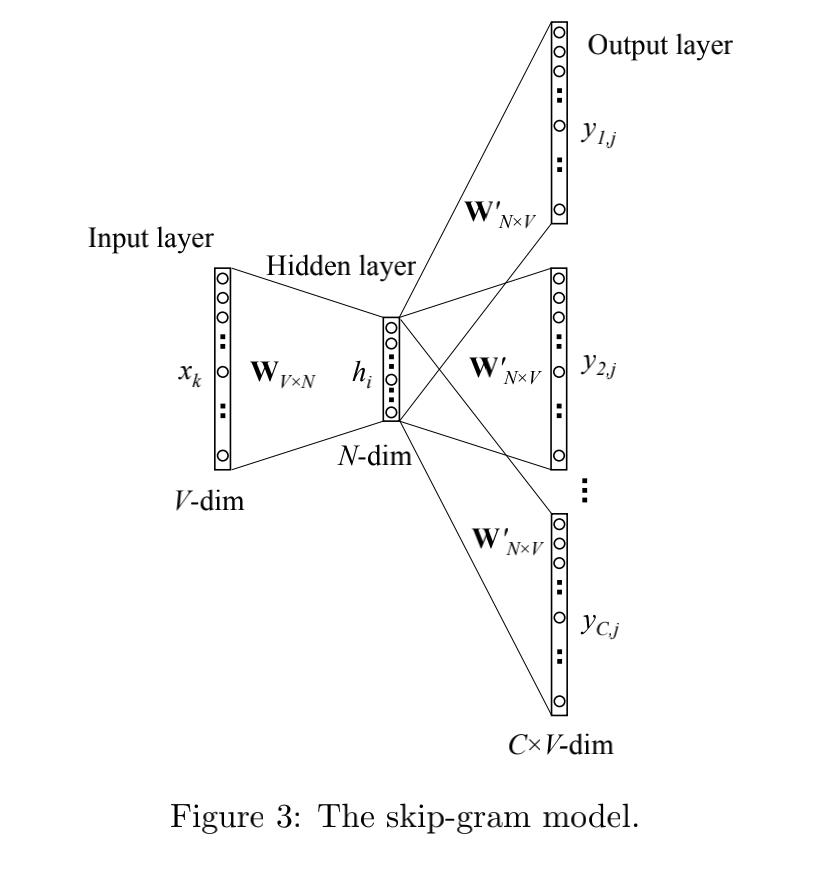
Skip-gram 对应的图如下:
从输入层到隐藏层:
h
=
W
k
,
.
T
:
=
v
w
I
T
h =W^T_{k,.} := v^T_{w_I}
h=Wk,.T:=vwIT
从隐藏层到输出层:
p
(
w
c
,
j
=
w
O
,
c
∣
w
I
)
=
y
c
,
j
=
e
x
p
(
u
c
,
j
)
∑
j
′
=
1
V
e
x
p
(
u
j
′
)
p(w_{c,j}= w_{O,c} | w_I) = y_{c, j} = \\frac{exp(u_{c,j})} {\\sum_{j'=1}^{V}exp(u_{j'})}
p(wc,j=wO,c∣wI)=yc,j=∑j′=1Vexp(uj′)exp(uc,j)
其中:
- w I w_I wI 表示的是输入词
- w c , j w_{c,j} wc,j 表示输出层第 c c c个词实际落在了第 j j j个神经元
-
w
O
,
c
w_{O,c}
wO,c 表示输出层第
c
c
c个词应该落在第
O
O
以上是关于Spark推荐系列之Word2vec算法介绍实现和应用说明的主要内容,如果未能解决你的问题,请参考以下文章
利用Tensorflow进行自然语言处理(NLP)系列之二高级Word2Vec