Linux sed 删除行命令常见使用详解
Posted ShenLiang2025
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux sed 删除行命令常见使用详解相关的知识,希望对你有一定的参考价值。
Linux sed d命令常见使用案例
声明与简介
sed:Stream Editor文本流编辑,sed是一个“非交互式的”面向字符流的编辑器。本文主要以实际的数据来介绍sed的delete line(删除)即d命令的使用。
数据说明
如下是使用的示例文本数据(emp.txt),它的结构为(员工号、员工的姓名、岗位、领导编号、雇佣日期、工资、奖金、部门编号)。这里的行号是为了方便解释结果,不是文本内容。
1 7369,smith,clerk,7902,'1980-12-17',800,null,20
2 7499,allen,salesman,7698,'1981-2-20',1600,300,30
3 7521,ward,salesman,7698,'1981-2-22',1250,500,30
4 7566,jones,manager,7839,'1981-4-2',2975,null,20
5 7654,martin,salesman,7698,'1981-9-28',1250,1400,30
6 7655,jack,manager,7698,'1987-3-28',1600,1800,10
7 7656,tim,clerk,7902,'1982-12-12',1400,1400,30
8 7657,kate,clerk,7902,'1989-11-11',1400,1800,10
9 7698,blake,manager,7839,'1981-5-1',2850,null,30
10 7699,dlake,salesman,7839,'1983-6-15',3000,null,10
11 7782,clark,manager,7839,'1981-1-9',2450,null,10
12 7788,scott,analyst,7566,'1982-12-9,3000,null,20
13 7839,king,president,null,'1981-11-17',5000,null,10
14 7844,turner,salesman,7698,'1981-12-8',1500,0,30
15 7876,adams,clerk,7788,'1983-1-12',1100,null,20
16 7900,james,clerk,7698,'1981-12-3',950,null,30
17
18 --7902,ford,analyst,7566,'1981-12-3',3000,null,20
19
20 7934,miller,clerk,7782,'1982-1-23',1300,null,10
d命令
D命令即是删除行 (delete lines)是对sed的输出流里的数据进行删除而不是直接作用到文件本身。
删除文本内容
删除所有内容
# 1 删除文件所有内容。执行后无返回。
sed 'd' filename
# 示例 删除emp.txt里所有内容
sed 'd' emp.txt删除指定行
# 2 删除第n行的内容,输出剩余的行。
sed 'n d' filename
# 示例,删除第2行的内容,显示剩余的内容。通过对比原始数据,不难发现员工编号7499所在的行(第二行)被删除。
sed '2 d' emp.txt删除指定的范围
# 3 从n到m行,这里n和m都包含。。
sed 'n,m d' filename
# 示例 这里删除了第3到16行,供14行,对比原始数据,剩下6行(这里有2行空行),见下:
sed '3,16 d' emp.txt
7369,smith,clerk,7902,'1980-12-17',800,null,20
7499,allen,salesman,7698,'1981-2-20',1600,300,30
--7902,ford,analyst,7566,'1981-12-3',3000,null,20
7934,miller,clerk,7782,'1982-1-23',1300,null,10
删除起始行到结尾
# 4 删除第n行到最后一行,换句话说即保留文本的n-1行。
sed 'n,$ d' filename
# 示例,删除第3行到最后一行,即保留前2行。
sed '3,$ d' emp.txt
7369,smith,clerk,7902,'1980-12-17',800,null,20
7499,allen,salesman,7698,'1981-2-20',1600,300,30递增删除
# 5 删除第n行,以m为步长(增幅)的所有行,输出为剩下内容。这里~是波浪线。
sed 'n~m d' filename
# 示例,比如删除以第1行开始,增幅为2的所有行,即删除1、3、5、7、9、11、13、15、17、19。保留是偶数的行,可参考原始数据核验。
sed '1~2 d' emp.txt
7499,allen,salesman,7698,'1981-2-20',1600,300,30
7566,jones,manager,7839,'1981-4-2',2975,null,20
7655,jack,manager,7698,'1987-3-28',1600,1800,10
7657,kate,clerk,7902,'1989-11-11',1400,1800,10
7699,dlake,salesman,7839,'1983-6-15',3000,null,10
7788,scott,analyst,7566,'1982-12-9,3000,null,20
7844,turner,salesman,7698,'1981-12-8',1500,0,30
7900,james,clerk,7698,'1981-12-3',950,null,30
--7902,ford,analyst,7566,'1981-12-3',3000,null,20
7934,miller,clerk,7782,'1982-1-23',1300,null,10删除指定的范围加号方式
# 6 删除第n到m行之间的行,输出剩余内容。这里m大于n,+是加号。效果等同于去掉+号。
sed 'n,+m d' filename
# 示例删除第3到21行的内容,输出剩余的内容。
sed '3,+21 d' emp.txt
7369,smith,clerk,7902,'1980-12-17',800,null,20
7499,allen,salesman,7698,'1981-2-20',1600,300,30删除结合模式匹配
指定关键字删除
# 1 删除指定的关键词word
sed '/word/ d' filename
# 示例,删除文本里含有clerk关键字的行,输出剩余内容。
sed '/clerk/ d' emp.txt
7499,allen,salesman,7698,'1981-2-20',1600,300,30
7521,ward,salesman,7698,'1981-2-22',1250,500,30
7566,jones,manager,7839,'1981-4-2',2975,null,20
7654,martin,salesman,7698,'1981-9-28',1250,1400,30
7655,jack,manager,7698,'1987-3-28',1600,1800,10
7698,blake,manager,7839,'1981-5-1',2850,null,30
7699,dlake,salesman,7839,'1983-6-15',3000,null,10
7782,clark,manager,7839,'1981-1-9',2450,null,10
7788,scott,analyst,7566,'1982-12-9,3000,null,20
7839,king,president,null,'1981-11-17',5000,null,10
7844,turner,salesman,7698,'1981-12-8',1500,0,30
--7902,ford,analyst,7566,'1981-12-3',3000,null,20
多个关键字删除
# 2 删除指定的关键词word1、word2
sed '/word1/ d' emp.txt | sed '/word2/ d'
# 删除包含clerk和salesman的行,这里主要是借助|(管道符号)实现,即前面的输出作为下个命令的输入。
sed '/clerk/ d' emp.txt | sed '/salesman/ d'
7566,jones,manager,7839,'1981-4-2',2975,null,20
7655,jack,manager,7698,'1987-3-28',1600,1800,10
7698,blake,manager,7839,'1981-5-1',2850,null,30
7782,clark,manager,7839,'1981-1-9',2450,null,10
7788,scott,analyst,7566,'1982-12-9,3000,null,20
7839,king,president,null,'1981-11-17',5000,null,10
--7902,ford,analyst,7566,'1981-12-3',3000,null,20
关键字指定位置删除
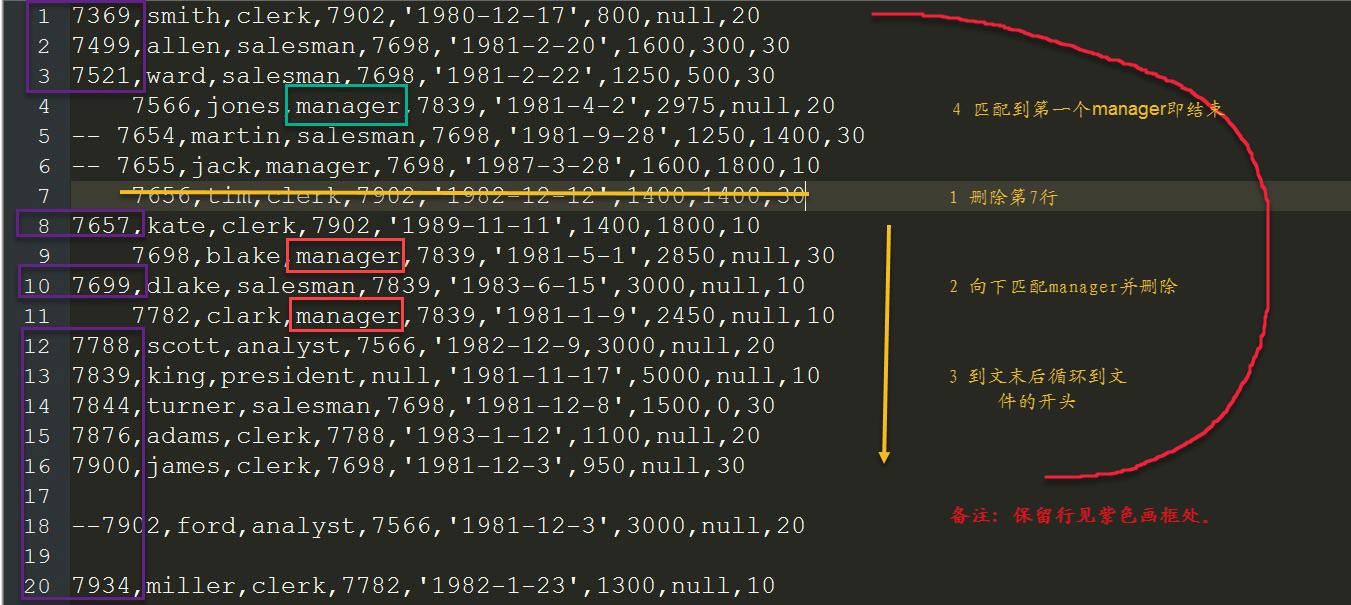
# 3 指定位置删除,从位置n开始往下删除匹配关键字word的行(含第n行),循环到文件头匹配关键字word的行(匹配到的行删除,执行到文末时从开头继续匹配,匹配到首个word后结束。原文件里内容的顺序不变)。
sed '/word/, n d' filename
# 示例,从第7行开始删,后面有manager关键字的会被删除,继续循环到文件头碰到首个匹配的manager结束。
sed '/manager/,7 d' emp.txt
7369,smith,clerk,7902,'1980-12-17',800,null,20
7499,allen,salesman,7698,'1981-2-20',1600,300,30
7521,ward,salesman,7698,'1981-2-22',1250,500,30
7657,kate,clerk,7902,'1989-11-11',1400,1800,10
7699,dlake,salesman,7839,'1983-6-15',3000,null,10
7788,scott,analyst,7566,'1982-12-9,3000,null,20
7839,king,president,null,'1981-11-17',5000,null,10
7844,turner,salesman,7698,'1981-12-8',1500,0,30
7876,adams,clerk,7788,'1983-1-12',1100,null,20
7900,james,clerk,7698,'1981-12-3',950,null,30
--7902,ford,analyst,7566,'1981-12-3',3000,null,20
7934,miller,clerk,7782,'1982-1-23',1300,null,10
# 执行过程详解,见下图:
关键字到文末删除
# 4 删除首次匹配word的行到文件末尾
sed '/word/,$ d' emp.txt
# 示例,删除manager关键字出现的行到文末,因为首次出现行在再底4行,所以最终保留的为前3行。
sed '/manager/,$ d' emp.txt
7369,smith,clerk,7902,'1980-12-17',800,null,20
7499,allen,salesman,7698,'1981-2-20',1600,300,30
7521,ward,salesman,7698,'1981-2-22',1250,500,30
两个关键字匹配方式删除
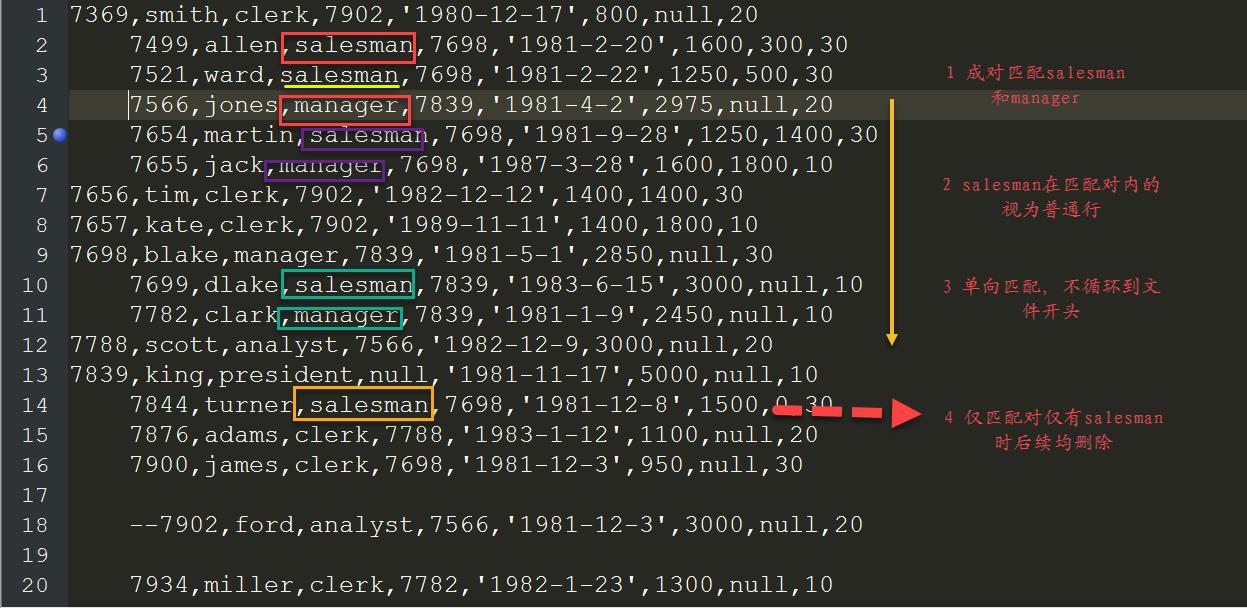
# 5 删除指定关键字word1、word2之间的内容,如果只能匹配word1时则删除该行及之后内容,匹配时不循环(即不从文件头继续寻找)。
sed '/word1/,/word2/ d' emp.txt
# 示例,删除salesman和manager匹配对内的行,其它行保留,匹配时单向(不循环)。
sed '/salesman/,/manager/ d' emp.txt
7369,smith,clerk,7902,'1980-12-17',800,null,20
7656,tim,clerk,7902,'1982-12-12',1400,1400,30
7657,kate,clerk,7902,'1989-11-11',1400,1800,10
7698,blake,manager,7839,'1981-5-1',2850,null,30
7788,scott,analyst,7566,'1982-12-9,3000,null,20
7839,king,president,null,'1981-11-17',5000,null,10
关键字和随后n行删除
# 6 删除匹配到关键字word和随后n行。
sed '/word/,+n d' filename
# 示例,删除匹配到salesman的行及随后的2行
sed '/salesman/,+2 d' emp.txt
7369,smith,clerk,7902,'1980-12-17',800,null,20
7657,kate,clerk,7902,'1989-11-11',1400,1800,10
7698,blake,manager,7839,'1981-5-1',2850,null,30
7839,king,president,null,'1981-11-17',5000,null,10
--7902,ford,analyst,7566,'1981-12-3',3000,null,20
7934,miller,clerk,7782,'1982-1-23',1300,null,10
所有空行删除
# 7 删除文件内容里所有的空行
sed '^$/ d' filename
#删除当前文本里的空行,查看结果可知第17和19行的空行被删除了。
sed '/^$/ d' emp.txt
7369,smith,clerk,7902,'1980-12-17',800,null,20
7499,allen,salesman,7698,'1981-2-20',1600,300,30
7521,ward,salesman,7698,'1981-2-22',1250,500,30
7566,jones,manager,7839,'1981-4-2',2975,null,20
7654,martin,salesman,7698,'1981-9-28',1250,1400,30
7655,jack,manager,7698,'1987-3-28',1600,1800,10
7656,tim,clerk,7902,'1982-12-12',1400,1400,30
7657,kate,clerk,7902,'1989-11-11',1400,1800,10
7698,blake,manager,7839,'1981-5-1',2850,null,30
7699,dlake,salesman,7839,'1983-6-15',3000,null,10
7782,clark,manager,7839,'1981-1-9',2450,null,10
7788,scott,analyst,7566,'1982-12-9,3000,null,20
7839,king,president,null,'1981-11-17',5000,null,10
7844,turner,salesman,7698,'1981-12-8',1500,0,30
7876,adams,clerk,7788,'1983-1-12',1100,null,20
7900,james,clerk,7698,'1981-12-3',950,null,30
--7902,ford,analyst,7566,'1981-12-3',3000,null,20
7934,miller,clerk,7782,'1982-1-23',1300,null,10
按指定字符开头删除
# 8 删除文件内所有以字符开头的行,这里的word可以是#、--等。
sed '/^word/ d' filename
# 删除以”—“双短横线开头的行。
sed '/^--/ d' emp.txt
7369,smith,clerk,7902,'1980-12-17',800,null,20
7499,allen,salesman,7698,'1981-2-20',1600,300,30
7521,ward,salesman,7698,'1981-2-22',1250,500,30
7566,jones,manager,7839,'1981-4-2',2975,null,20
7654,martin,salesman,7698,'1981-9-28',1250,1400,30
7655,jack,manager,7698,'1987-3-28',1600,1800,10
7656,tim,clerk,7902,'1982-12-12',1400,1400,30
7657,kate,clerk,7902,'1989-11-11',1400,1800,10
7698,blake,manager,7839,'1981-5-1',2850,null,30
7699,dlake,salesman,7839,'1983-6-15',3000,null,10
7782,clark,manager,7839,'1981-1-9',2450,null,10
7788,scott,analyst,7566,'1982-12-9,3000,null,20
7839,king,president,null,'1981-11-17',5000,null,10
7844,turner,salesman,7698,'1981-12-8',1500,0,30
7876,adams,clerk,7788,'1983-1-12',1100,null,20
7900,james,clerk,7698,'1981-12-3',950,null,30
7934,miller,clerk,7782,'1982-1-23',1300,null,10
以上是关于Linux sed 删除行命令常见使用详解的主要内容,如果未能解决你的问题,请参考以下文章