爬虫日记(85):Scrapy的ExecutionEngine类
Posted caimouse
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫日记(85):Scrapy的ExecutionEngine类相关的知识,希望对你有一定的参考价值。
接着下来我们来分析_next_request_from_scheduler函数,这个函数主要实现从调度器里获得下载请求,然后把请求下载再放到下载器里去下载。实现这部分的功能:
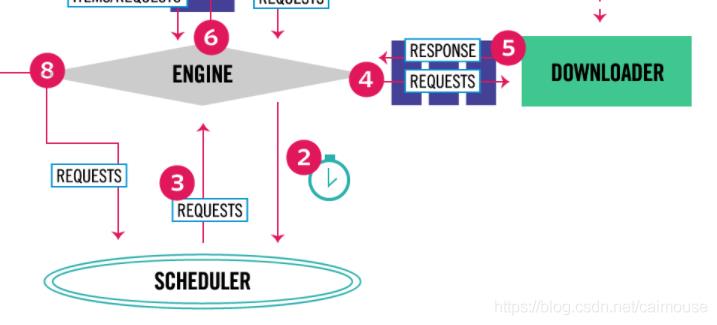
也就是上图的2、3、4、5这四步的功能。因此我们需要详细地查看这个函数的每一行代码:

这个函数传进来的参数spider是蜘蛛类对象。
第152行代码是保存类的slot对象到临时对象,避免self.slot修改为空的状态冲突。
第153行是从类class Scheduler对象获得下一个可以发送的请求下载对象。
第154行判断下一个请求对象是否为空,如果为空就直接退此函数执行。
以上是关于爬虫日记(85):Scrapy的ExecutionEngine类的主要内容,如果未能解决你的问题,请参考以下文章
爬虫日记(85):Scrapy的ExecutionEngine类