Elasticsearch入门 组件部署及体验
Posted 杀智勇双全杀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch入门 组件部署及体验相关的知识,希望对你有一定的参考价值。
Elasticsearch入门(四) 组件部署及体验
FileBeat
简介
Elastic官网最下方有链接可以跳转:

跳转到Beat后可以看到:
这是一个家族。。。可以查看Beats的文档说明。
常用的是FileBeat。
部署
cd ~
rz
tar -zxvf filebeat-7.6.1-linux-x86_64.tar.gz -C /export/server/es/
使用
FileBeat程序需要配置Input和Output,从官网手册(Configure里有各种配置)可以看到支持的类型。配置好后运行开发配置文件即可。
测试
先创建配置文件:
cd /export/server/es/filebeat-7.6.1-linux-x86_64/
mkdir apps
vim apps/logfile_to_es.filebeat
修改内容为:
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/esuser/server.log.*
output.elasticsearch:
hosts: ["node1:9200", "node2:9200", "node3:9200"]
保存后上传数据:
cd
rz
先上传2个Kafka日志:
[esuser@node1 ~]$ ll
总用量 376800
-rw-r--r-- 1 esuser esuser 427746 4月 24 2020 server.log.2020-04-24-19
-rw-r--r-- 1 esuser esuser 942 4月 24 2020 server.log.2020-04-24-20
切换目录:
cd /export/server/es/filebeat-7.6.1-linux-x86_64/
尝试运行(-c表示运行配置文件,-e表示执行):
[esuser@node1 filebeat-7.6.1-linux-x86_64]$ filebeat -c apps/logfile_to_es.filebeat -e
Exiting: error loading config file: config file ("apps/logfile_to_es.filebeat") can only be writable by the owner but the permissions are "-rw-rw-r--" (to fix the permissions use: 'chmod go-w /export/server/es/filebeat-7.6.1-linux-x86_64/apps/logfile_to_es.filebeat')
不出意外会提示权限太多不能运行,按照提示取消属组与其它用户的可写权限后才能运行:
chmod go-w /export/server/es/filebeat-7.6.1-linux-x86_64/apps/logfile_to_es.filebeat
当然还需要先启动ES和ES-head,3台机先启动ES:
/export/server/es/elasticsearch-7.6.1/bin/elasticsearch >>/dev/null 2>&1 &
然后node1启动ES-head:
/export/server/es/elasticsearch-head/node_modules/grunt/bin/grunt server >/dev/null 2>&1 &
发现启动失败:
1943 Jps
1741 Elasticsearch
[2]+ 退出 99 /export/server/es/elasticsearch-head/node_modules/grunt/bin/grunt server > /dev/null 2>&1
[esuser@node1 ~]$ /export/server/es/elasticsearch-head/node_modules/grunt/bin/grunt server >/dev/null 2>&1 &
[2] 1955
[esuser@node1 ~]$ /export/server/es/elasticsearch-head/node_modules/grunt/bin/grunt server >/dev/null 2>&1 &
[3] 1961
[2] 退出 99 /export/server/es/elasticsearch-head/node_modules/grunt/bin/grunt server > /dev/null 2>&1
[esuser@node1 ~]$ /export/server/es/elasticsearch-head/node_modules/grunt/bin/grunt server
grunt-cli: The grunt command line interface (v1.2.0)
Fatal error: Unable to find local grunt.
If you're seeing this message, grunt hasn't been installed locally to
your project. For more information about installing and configuring grunt,
please see the Getting Started guide:
http://gruntjs.com/getting-started
[3]+ 退出 99 /export/server/es/elasticsearch-head/node_modules/grunt/bin/grunt server > /dev/null 2>&1
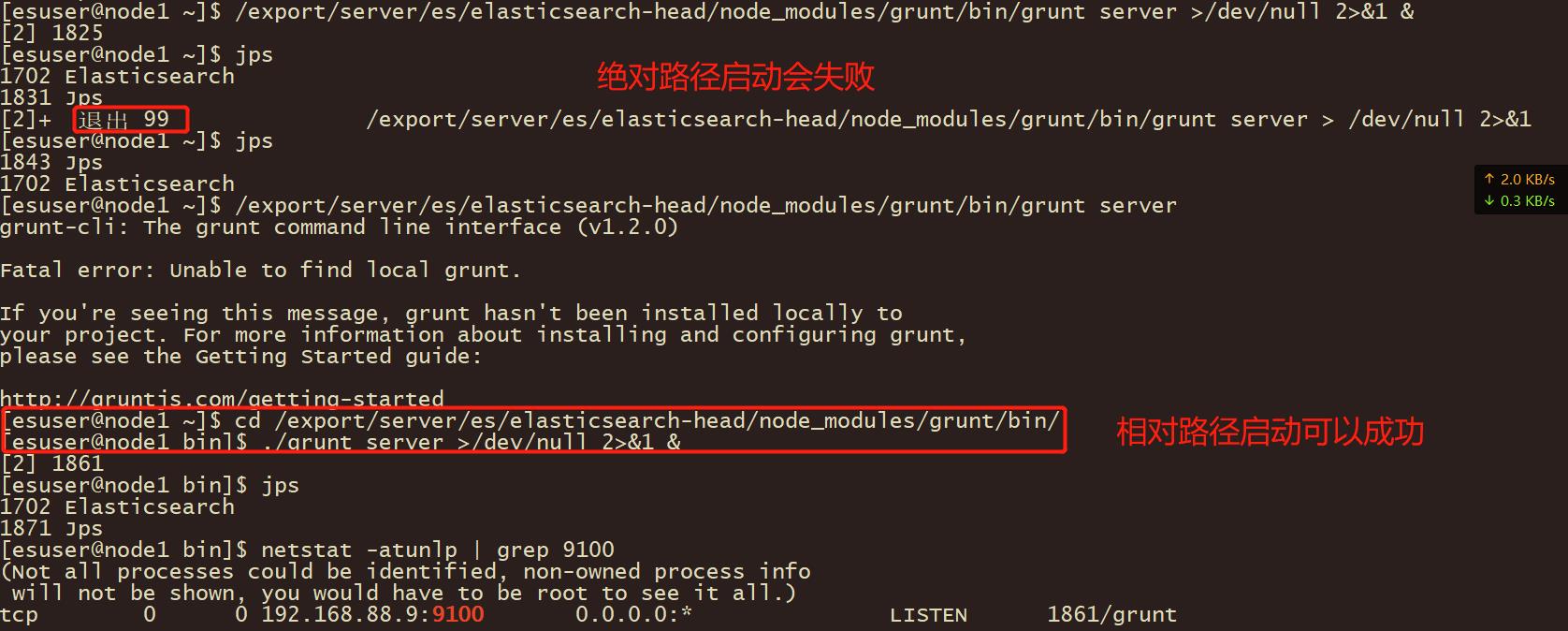
报错:Unable to find local grunt.
各种稿子都在瞎写。。。老老实实使用相对路径启动:
cd /export/server/es/elasticsearch-head/node_modules/grunt/bin/
#后台启动
./grunt server >/dev/null 2>&1 &
#查看进程
netstat -atunlp | grep 9100
再次切换目录并重试:
cd /export/server/es/filebeat-7.6.1-linux-x86_64/
./filebeat -c apps/logfile_to_es.filebeat -e
刷新浏览器node1:9100:
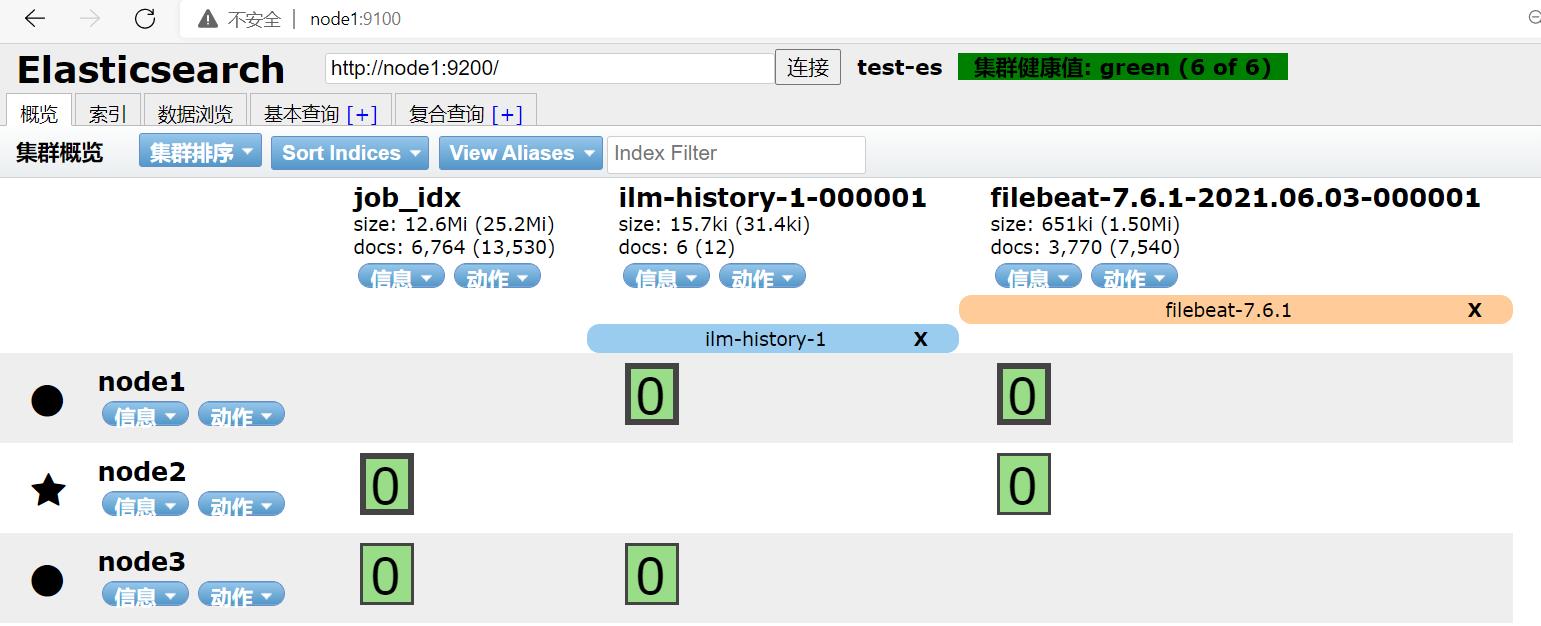
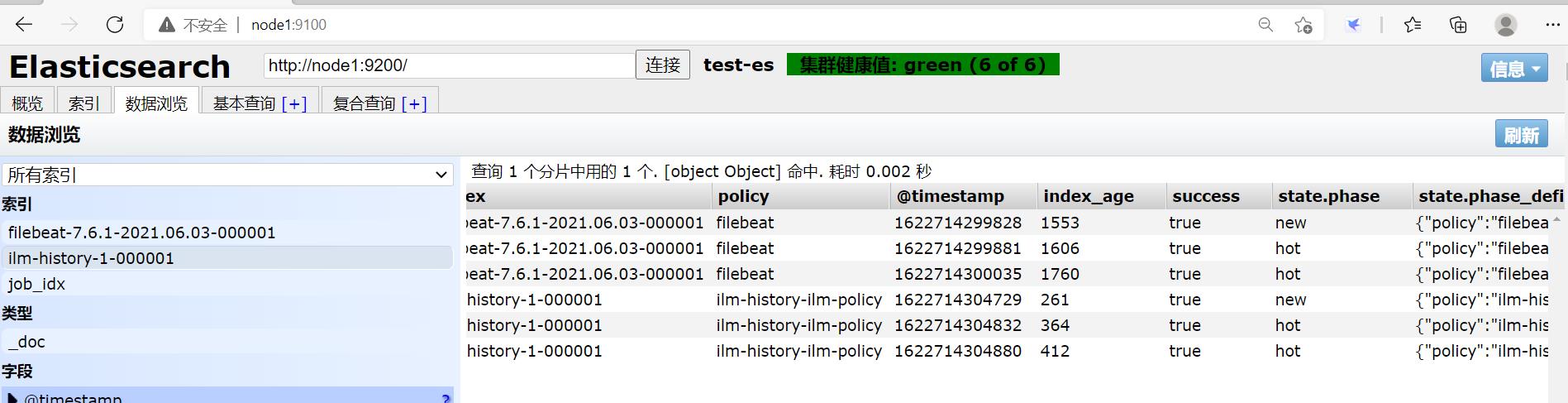
VS Code中:
GET /filebeat-7.6.1-2021.06.03-000001/_search
执行后:
"value": 3770,
新建会话,上传更多数据后:
[esuser@node1 ~]$ ll
总用量 376832
-rw-r--r-- 1 esuser esuser 427746 4月 24 2020 server.log.2020-04-24-19
-rw-r--r-- 1 esuser esuser 942 4月 24 2020 server.log.2020-04-24-20
-rw-r--r-- 1 esuser esuser 1137 4月 24 2020 server.log.2020-04-24-21
-rw-r--r-- 1 esuser esuser 27888 4月 24 2020 server.log.2020-04-24-22
VS Code中重新Run Query:
"value": 3937,
刷新网页,也发生了变化,FileBeat可以实现自动增量采集。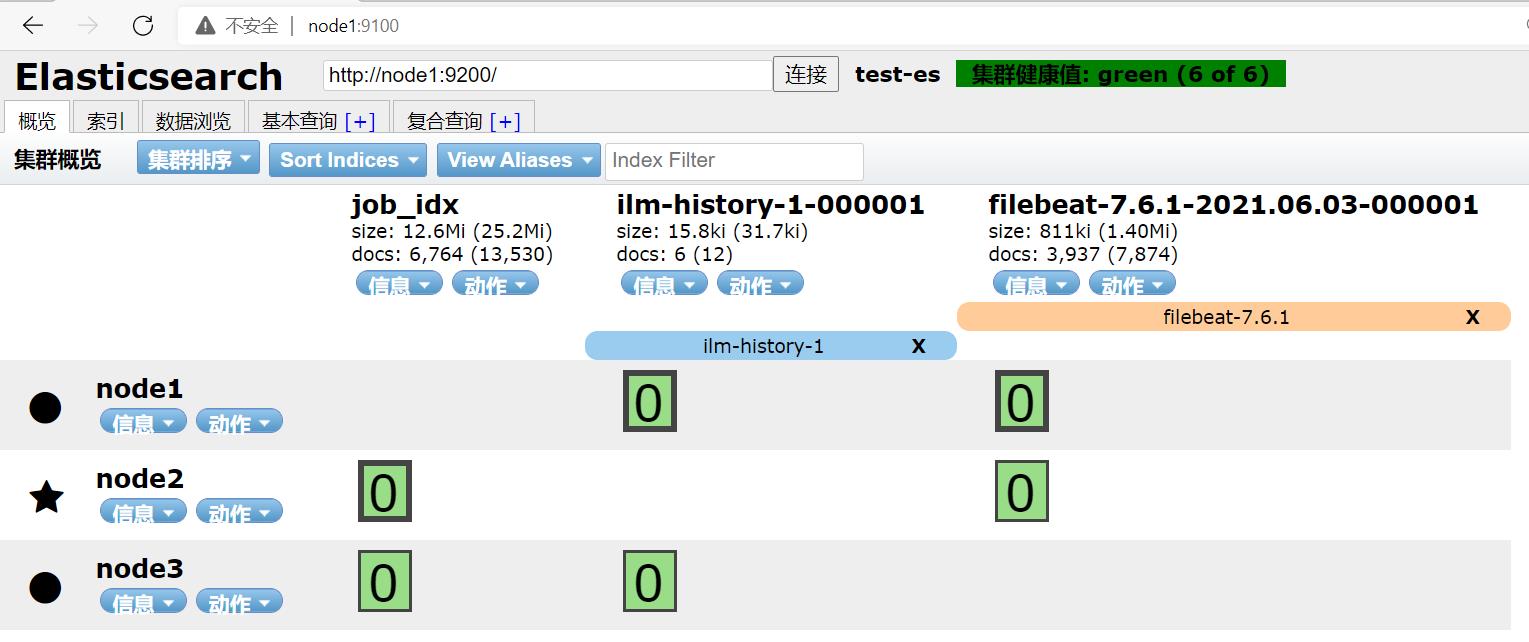
这里存着元数据:
[esuser@node1 ~]$ ll /export/server/es/filebeat-7.6.1-linux-x86_64/data/registry/filebeat/
总用量 8
-rw------- 1 esuser esuser 792 6月 3 18:06 data.json
-rw------- 1 esuser esuser 16 6月 3 17:58 meta.json
多行合并
先删除旧的内容:
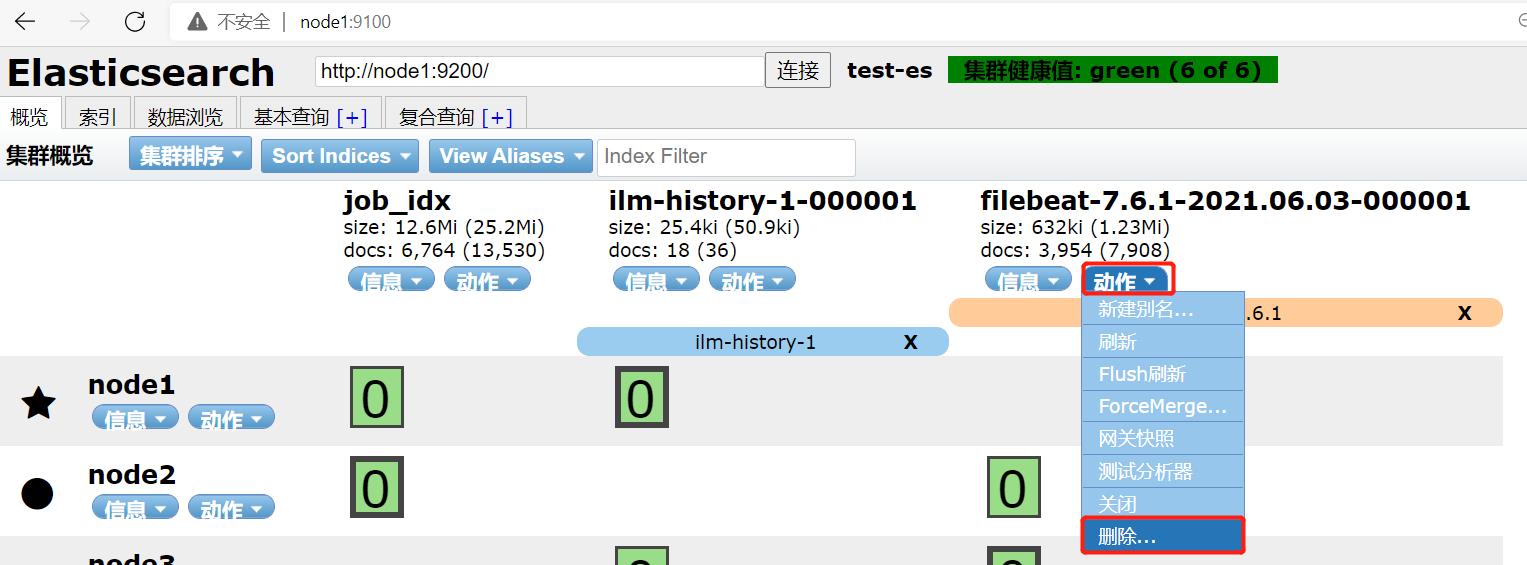
ES-head可以很方便地删除,但是需要输入:
再上传个错误日志。。。发现:
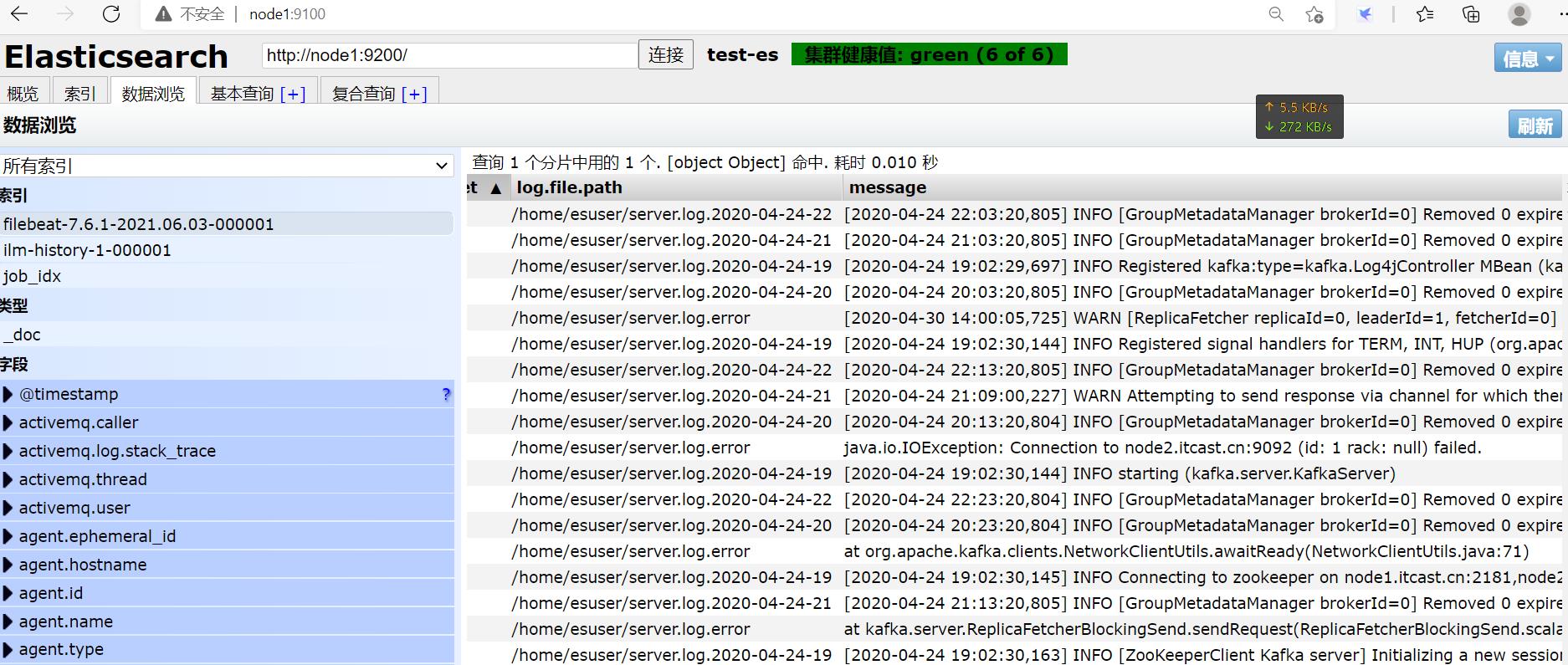
∵报错的日志文件是这样:
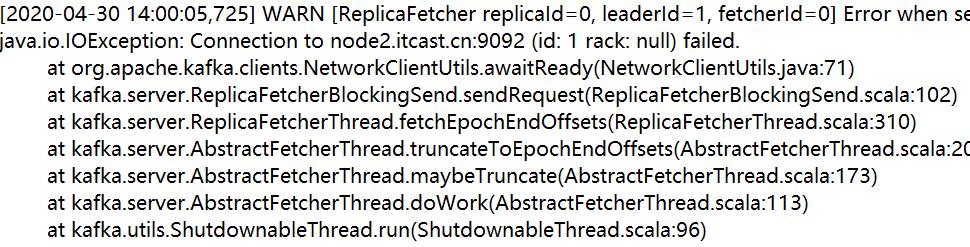
会出现错行。。。VS Code看到也是错行了:
"message": " at kafka.server.ReplicaFetcherThread.fetchEpochEndOffsets(ReplicaFetcherThread.scala:310)",
重写个配置方案:
vim /export/server/es/filebeat-7.6.1-linux-x86_64/apps/logfile_regex_to_es.filebeat
填写:
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/esuser/server.log.*
multiline.pattern: '^\\['
multiline.negate: true
multiline.match: after
output.elasticsearch:
hosts: ["node1:9200", "node2:9200", "node3:9200"]
并保存,其中:
multiline.pattern: '^\\[' #中括号开头的数据作为新的一行
multiline.negate: true #不符合的行进行合并
multiline.match: after #合并在上一行的后面
之后去掉属主外其余用户的可写权限:
chmod go-w /export/server/es/filebeat-7.6.1-linux-x86_64/apps/logfile_regex_to_es.filebeat
使用ctrl+c结束后,再次重复上一步的删除操作,并把家目录的日志文件也删除:
rm -rf server.log.2*
删除元数据:
rm -ef /export/server/es/filebeat-7.6.1-linux-x86_64/data/registry/filebeat/*
VS Code中删除ES数据:
delete /filebeat-7.6.1-2021.06.02-000001
执行:
cd /export/server/es/filebeat-7.6.1-linux-x86_64/
./filebeat -c apps/logfile_regex_to_es.filebeat -e
如果node1:9100多次刷新不更新,就需要删除元数据:
rm -rf /export/server/es/filebeat-7.6.1-linux-x86_64/data/registry/filebeat/*
并重新采集。。。刷新后看到:
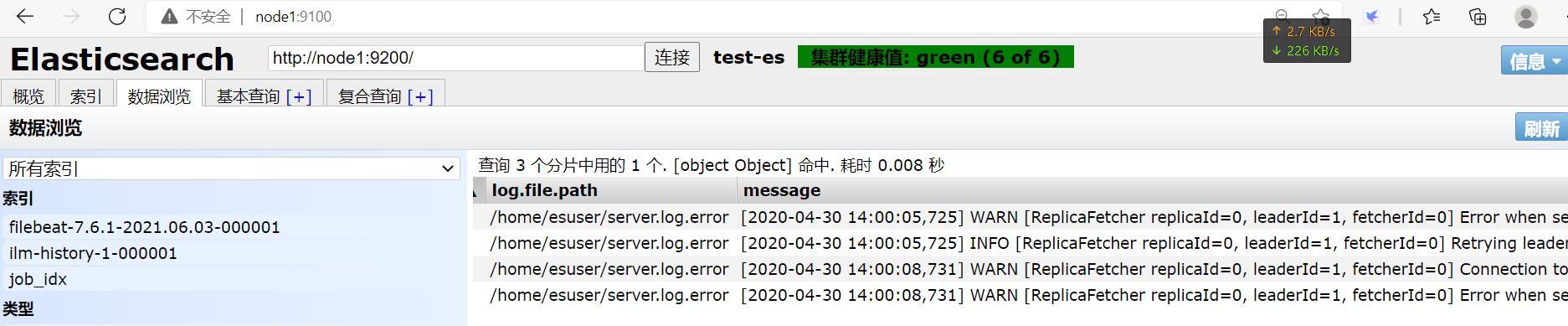
VS Code使用:
GET /filebeat-7.6.1-2021.06.03-000001/_search
{
"query": {
"match": {
"log.file.path": "/home/esuser/server.log.error"
}
}
}
查询后:
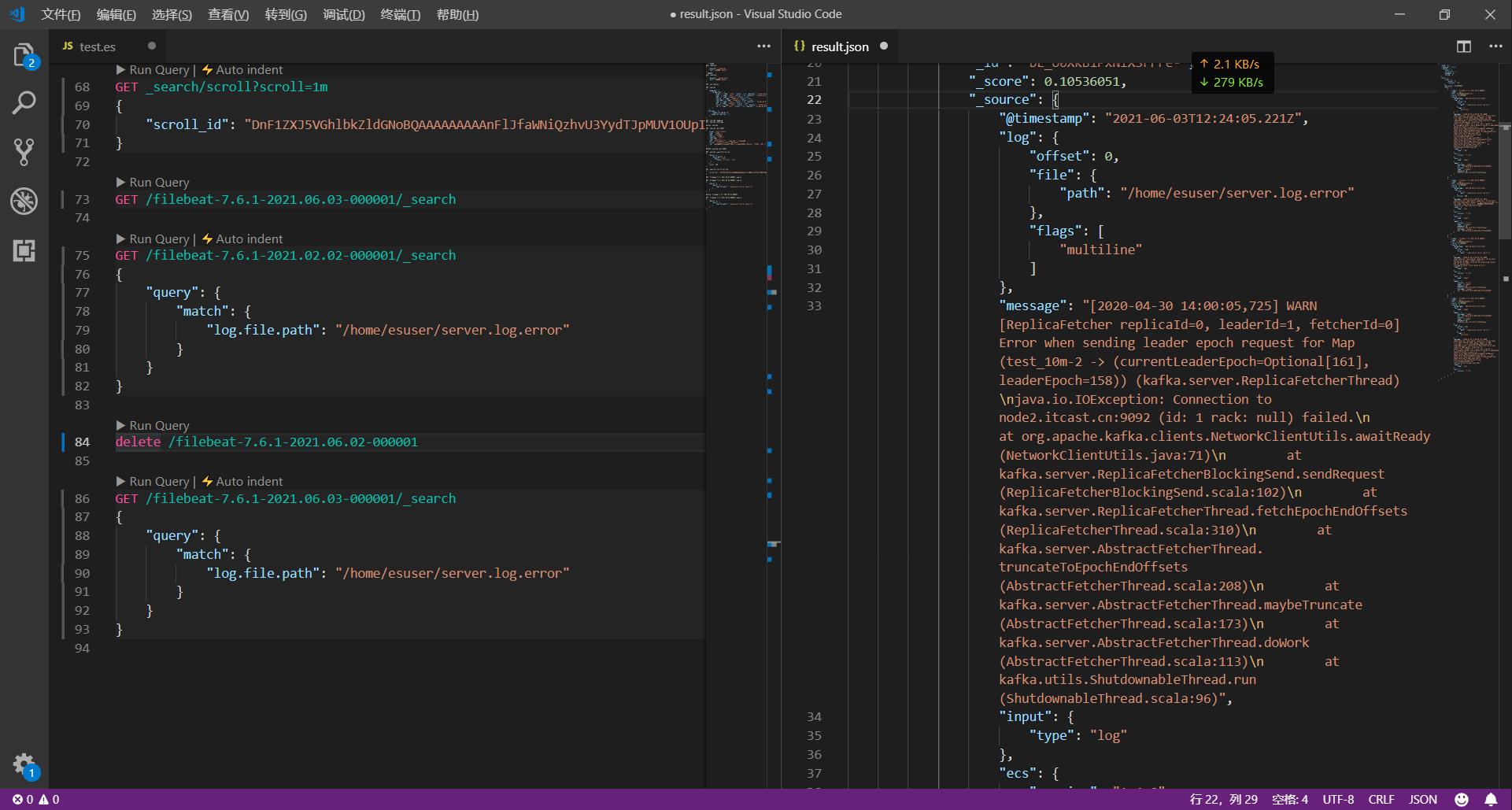
(需要查看中设置右侧分栏自动换行)
Logstash
简介
这是ELK中的L组件,用于全场景下的数据采集,注重于数据的转换处理(能对FileBeat传递过来的数据进行ETL处理),功能全面,可以实现数据的预处理。
但是这货侧重于数据处理,性能较差,开发接口不友好,现在一般不用于做数据采集工具(Flume、Sqoop等使用容易)。
官网有写这货需要Input、Filter(可选)、Output:
部署
安装包是zip的,Linux中很少见:
cd
rz
unzip logstash-7.6.1.zip -d /export/server/es/
cd /export/server/es/logstash-7.6.1/
就完了。。。
使用
先配置,再调用配置的老套路。。。
采集stdin并输出到stdout
node1使用VIM:
cd /export/server/es/logstash-7.6.1/
mkdir apps
vim apps/stdin-stdout.json
填写:
input {
stdin { }
}
output {
stdout {}
}
保存后即可测试:
bin/logstash -f apps/stdin-stdout.json
其中:
-f:指定运行某个文件
-e:在命名行执行代码
-t:测试代码的语法是否正确
这3个参数只能选1个用。。。
执行后(截取部分内容):
The stdin plugin is now waiting for input:
/export/server/es/logstash-7.6.1/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{
"host" => "node1",
"message" => "hehe",
"@version" => "1",
"@timestamp" => 2021-06-03T12:47:18.039Z
}
{
"host" => "node1",
"message" => "haha",
"@version" => "1",
"@timestamp" => 2021-06-03T12:47:18.057Z
}
[2021-06-03T20:47:18,572][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
采集文件并输出到stdout
VIM编辑:
vim /export/server/es/logstash-7.6.1/apps/input-file-test.json
input{
file{
path => "/home/esuser/tomcat.log"
type => "log"
start_position => "beginning"
}
}
output{
stdout{
codec=>rubydebug
}
}
保存后先上传日志文件再测试:
bin/logstash -f apps/input-file-test.json
采集mysql并输出到stdout
MySQL中:
create database test;
use test;
CREATE TABLE `wcresult` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`word` varchar(100) NOT NULL,
`number` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into wcresult values(null,'hadoop',8);
insert into wcresult values(null,'hive',16);
VIM编辑:
vim /export/server/es/logstash-7.6.1/apps/input-jdbc1.json
input {
jdbc {
jdbc_driver_library => "/home/esuser/mysql-connector-java-5.1.38.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://node3:3306/test"
jdbc_user => "root"
jdbc_password => "123456"
schedule => "*/1 * * * *"
statement => "SELECT * from wcresult where number > 10;"
}
}
output{
stdout{
codec=>rubydebug
}
}
准备好jar包后就可以测试:
bin/logstash -f apps/input-jdbc1.json
也可以增量更新:
input {
jdbc {
jdbc_driver_library => "/home/esuser/mysql-connector-java-5.1.38.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://node3:3306/test"
jdbc_user => "root"
jdbc_password => "123456"
use_column_value => true
tracking_column => "id"
schedule => "*/1 * * * *"
statement => "SELECT * from wcresult where number > 10 and id > :sql_last_value;"
}
}
output{
stdout{
codec=>rubydebug
}
}
bin/logstash -f apps/input-jdbc2.json
采集FileBeat到并输出到ES
先用FileBeat采集文件,写入Logstash,再用Logstash写入ES。
日志文件当然需要正则表达式划分:
cd /export/server/es/filebeat-7.6.1-linux-x86_64/
vim apps/logfile_to_logstash.filebeat
插入:
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/esuser/access.*
multiline.pattern: '^\\d+\\.\\d+\\.\\d+\\.\\d+ '
multiline.negate: true
multiline.match: after
output.logstash:
enabled: true
hosts: ["node1:45454"]
保存后,去掉其余用户的可写权限:
chmod go-w apps/logfile_to_logstash.filebeat
继续VIM:
cd /export/server/es/logstash-7.6.1/
vim apps/beats_to_es.json
插入:
input {
beats {
port => 45454
}
}
output {
elasticsearch {
hosts => [ "node1:9200","node2:9200","node3:9200"]
}
}
为了防止出错,先删除元数据:
rm -rf /export/server/es/filebeat-7.6.1-linux-x86_64/data/registry/filebeat/*
先启动Logstash:
cd /export/server/es/logstash-7.6.1/
bin/logstash -f apps/beats_to_es.json
再启动FileBeat:
cd /export/server/es/filebeat-7.6.1-linux-x86_64/
./filebeat -c apps/logfile_to_logstash.filebeat -e
上传log文件后:
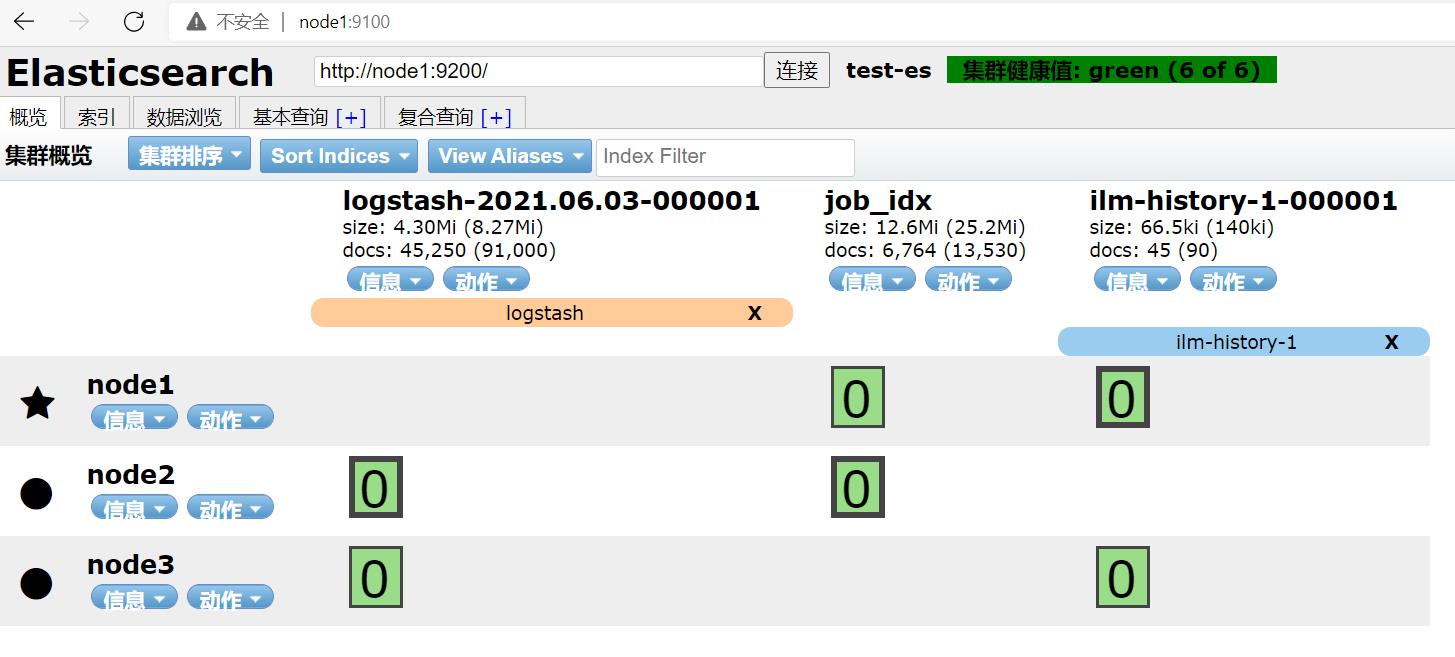
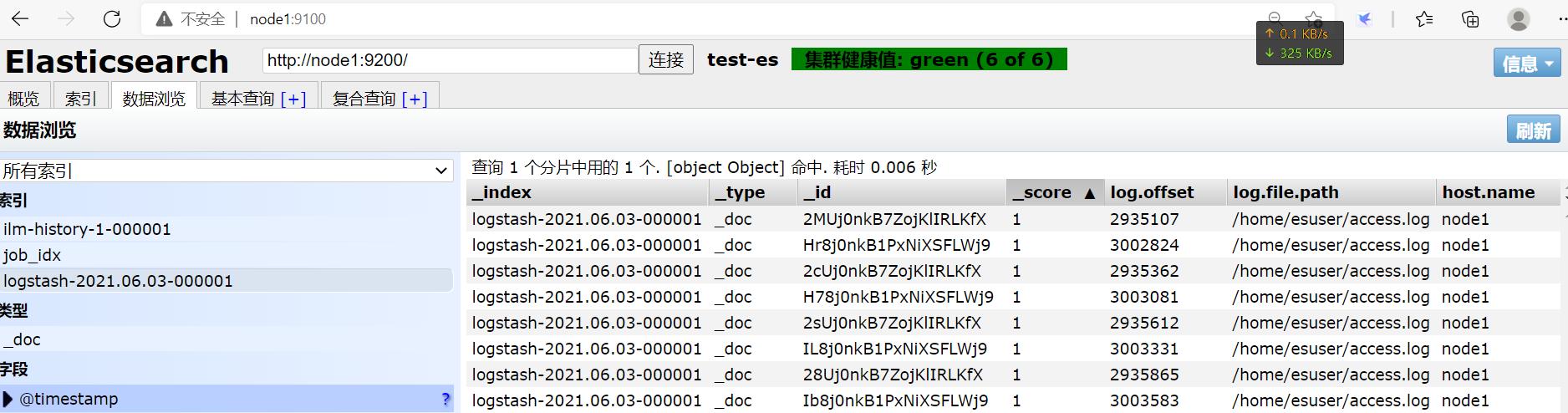
每条数据作为一个message内容写入了es。
数据解析
先查看已经安装的Logstash插件:
/export/server/es/logstash-7.6.1
bin/logstash-plugin list
使用GROK插件可以正则匹配,将原始数据中的字段提取出来:
%{SYNTAX:SEMANTIC}
这种套路。。。
vim apps/beats_grokall_console.json
插入:
input {
beats {
port => 45454
}
}
filter {
grok {
match => {
"message" => "%{IP:ip} - - \\[%{HTTPDATE:date}\\] \\"%{WORD:method} %{PATH:uri} %{DATA}\\" %{INT:status} %{INT:length} \\"%{DATA:reference}\\" \\"%{DATA:browser}\\""
}
}
}
output {
stdout {
codec => rubydebug
}
}
保存后,先启动Logstash:
bin/logstash -f apps/beats_grokall_console.json
删除FileBeat的元数据并启动FileBeat:
rm -rf /export/server/es/filebeat-7.6.1-linux-x86_64/data/registry/filebeat/*
cd /export/server/es/filebeat-7.6.1-linux-x86_64/
∵必须先开启接收端后开启发送端才能确保数据不会丢失,故启动顺序不对会出现:
2021-06-03T22:00:17.634+0800 ERROR pipeline/output.go:100 Failed to connect to backoff(async(tcp://node1:45454)): dial tcp 192.168.88.9:45454: connect: connection refused
2021-06-03T22:00:17.635+0800 INFO pipeline/output.go:93 Attempting to reconnect to backoff(async(tcp://node1:45454)) with 4 reconnect attempt(s)
同一家的产品这点做的比较好。。。会一直等待连接成功才继续发送。。。连接成功后就会刷屏发送数据:
数据转换
mutate插件可以实现字段添加、处理、重命名等操作。
date插件可以实现日期转换处理。
cd /export/server/es/logstash-7.6.1
vim apps/beats_mutate_date_es.json
插入:
input {
beats {
port => 45454
}
}
filter {
grok {
match => {
"message" => "%{IP:ip} - - \\[%{HTTPDATE:date}\\] \\"%{WORD:method} %{PATH:uri} %{DATA}\\" %{INT:status:int} %{INT:length:int} \\"%{DATA:reference}\\" \\"%{DATA:browser}\\""
}
}
mutate {
enable_metric => "false"
remove_field => ["message", "log", "tags", "@timestamp", "input", "agent", "host", "ecs", "@version"]
}
date {
match => ["date","dd/MMM/yyyy:HH:mm:ss Z","yyyy-MM-dd HH:mm:ss"]
target => "date"
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["node1:9200" ,"node2:9200" ,"node3:9200"]
index => "apache_web_log"
}
}
老套路:
bin/logstash -f apps/beats_mutate_date_es.json
rm -rf /export/server/es/filebeat-7.6.1-linux-x86_64/data/registry/filebeat/*
./filebeat -c apps/logfile_to_logstash.filebeat -e
默默等待:
2021-06-03T22:09:24.863+0800 INFO pipeline/output.go:95 Connecting to backoff(async(tcp://node1:45454))
2021-06-03T22:09:24.863+0800 INFO pipeline/output.go:105 Connection to backoff(async(tcp://node1:45454)) established

采集标准输出到文件
input {stdin{}}
output {
file {
path => "/export/servers/es/logstash-6.0.0/usercase/datas/%{+YYYY-MM-dd}-%{host}.txt"
codec => line {
format => "%{message}"
}
flush_interval => 0
}
}
采集标准输出到ES
input {stdin{}}
output {
elasticsearch {
hosts => ["node1:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}
采集文件到Kafka
input {
file{
path => "/home/es/tomcat.log"
type => "log"
start_position => "beginning"
}
}
output {
kafka {
topic_id => "bigdata"
bootstrap_servers => "node1:9092,node2:9092,node3:9092"
batch_size => 5
}
}
采集Kafka到ES
input{
kafka {
group_id => "testLogstash"
auto_offset_reset => "earliest"
topics => ["bigdata"]
bootstrap_servers => "node1:9092,node2:9092,node3:9092"
}
}
output {
elasticsearch {
hosts => ["node1:9200"]
index => "kakfatoes"
}
}
都是套路。。。
Kibana
这是个可视化工具。。。毕竟ES-head并不美观。。。
部署
cd
rz
tar -zxvf kibana-7.6.1-linux-x86_64.tar.gz -C /export/server/es/
cd /export/server/es/kibana-7.6.1-linux-x86_64/
vim config/kibana.yml
修改第7行:
server.host: "node1"
修改25行:
server.name: "test-kibana"
修改28行:
elasticsearch.hosts: ["http://node1:9200"]
同样是会霸占前台shell会话的进程。。。输出重定向到黑洞:
bin/kibana >>/dev/null 2>&1 &
查看进程:
[esuser@node1 kibana-7.6.1-linux-x86_64]$ ps -ef | grep node
esuser 3628 1645 82 22:16 pts/0 00:00:52 bin/../node/bin/node bin/../src/cli
esuser 3675 1645 0 22:17 pts/0 00:00:00 grep --color=auto node
打开
浏览器node1:5601:
添加数据源:
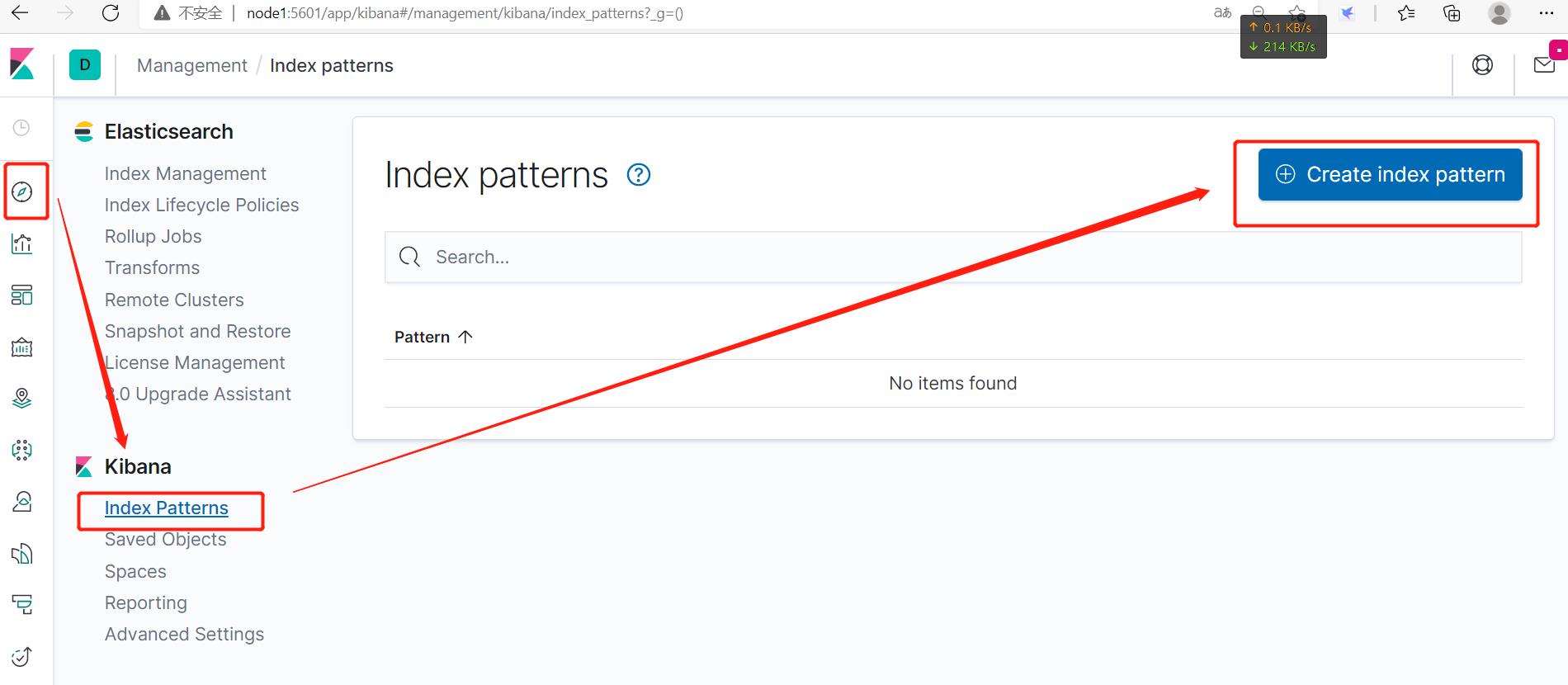
Discover→Index Patterns→Create index pattern。
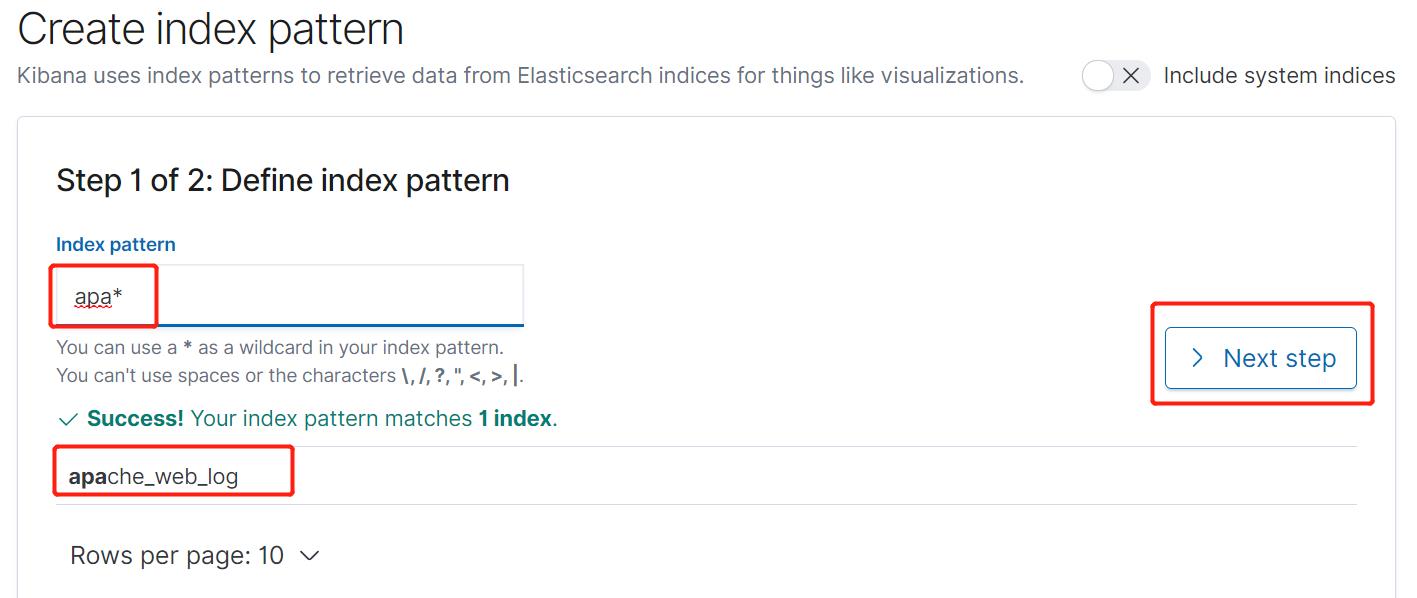
输入开头字符会自动识别,就可以Next step。
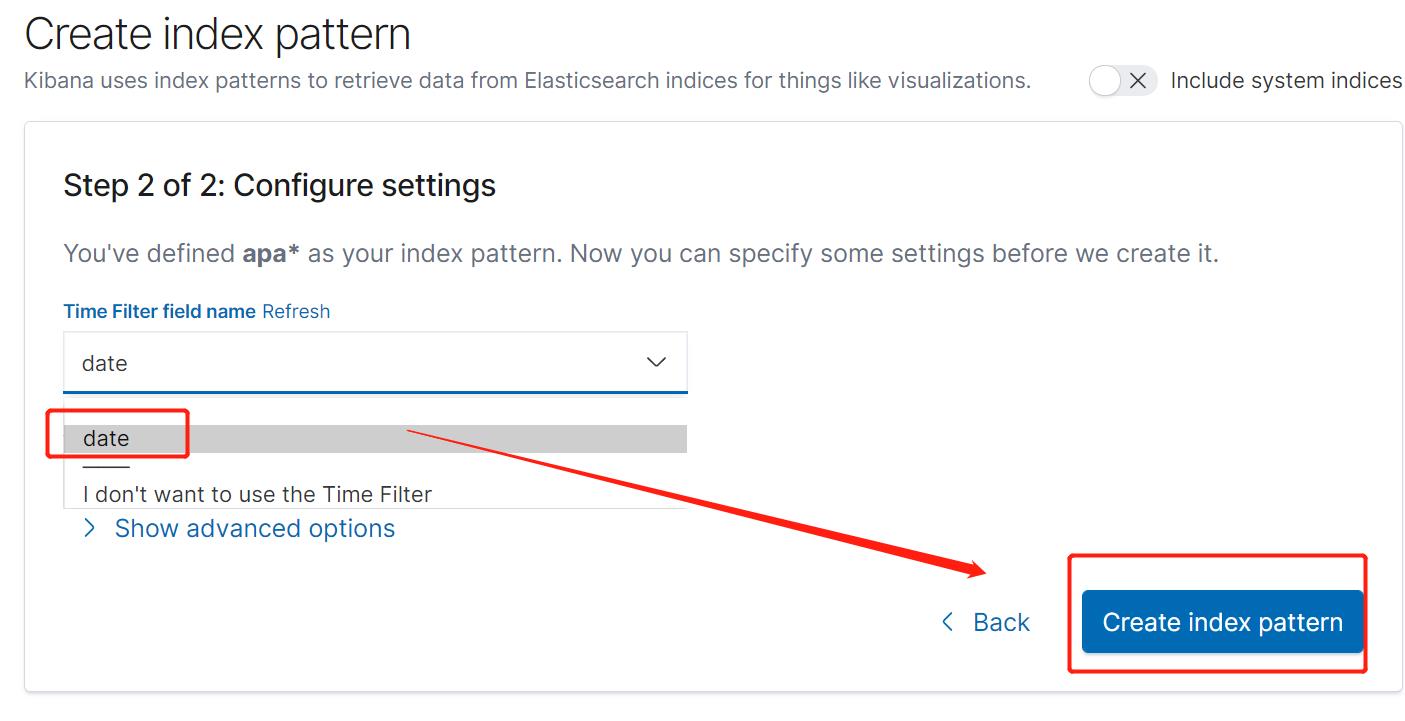
自动识别出自动。。。选date后下一步。。。
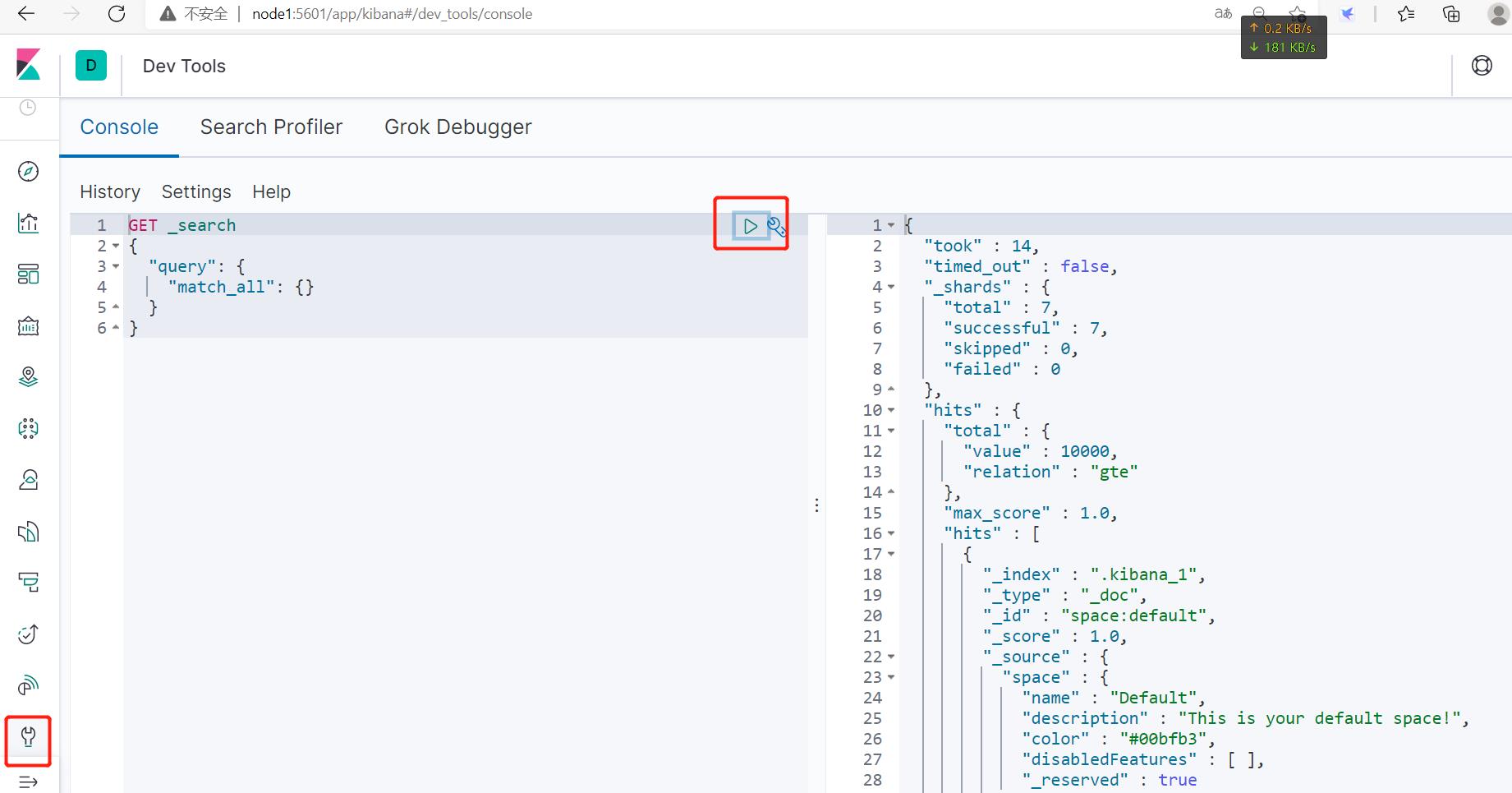
Dev tool处可以开发脚本及执行。。。
筛选

可以筛选。。。
左上角也可以筛选。。。右上角点击后更新。。。也可以使用∩∪运算:
status: 200 and method: post
图表及看板
可以绘制饼图等各种图。。。
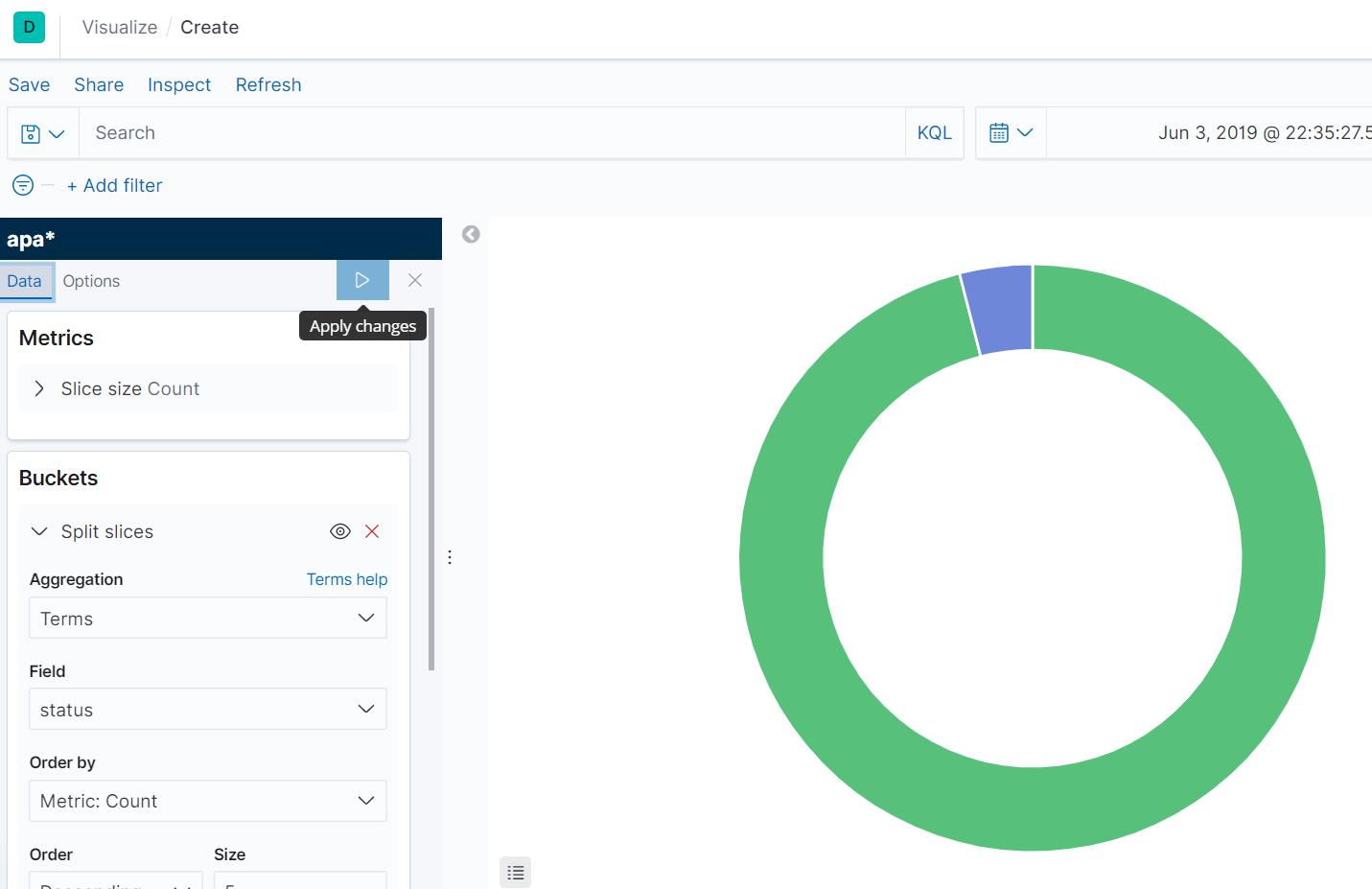
用起来和Tableau、Fine BI这些可视化工具差不多。。。
以上是关于Elasticsearch入门 组件部署及体验的主要内容,如果未能解决你的问题,请参考以下文章