Caffeine缓存性能算法&布隆过滤器
Posted hanruikai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Caffeine缓存性能算法&布隆过滤器相关的知识,希望对你有一定的参考价值。
算法优化
缓存最重要的是命中率,我们知道,普通的缓存主要基于以下三种算法淘汰旧数据:
- FIFO 先进先出
- LRU 最久未使用
- LFU 最少使用频率
以上三种算法都有缺点,比如先进先出算法没有考虑使用频率;LRU也没有正确考虑使用频率;LFU的频率计算不平均,比如一个热点影片刚上映几天,点击量很高,后来持续走低,但是
以为头几天的点击量,导致频率很高,根据策略无法淘汰,也不完全科学。
主要问题:
- 算法优化,新的热点数据可能无法缓存,热点数据计算有瑕疵
- 频率标记占用空间优化
如何优化呢?
w-tinylfu 算法
该算法主要完成以下两个任务:
- Count-Min Sketch频率估计算法,减少内存消耗
- 维护PK机制,保证新的热点数据能被缓存
Count-Min Sketch算法(不存储key值却能够估算频率)
此算法是个频率估计算法。对于频率估计,我们有以下几个思路:
- HashMap统计频率,简单可行,但是如果大数量量,需要巨大的内存存储
- 分片+HashMap存储,基于第一个方法改进,引入分片机制,
假设有8台机器,每台机器都有一个HashMap,第1台机器只处理
hash(elem)%8==0的元素,第2台机器只处理hash(elem)%8==1的元素,以此类推。查询的时候,先计算这个元素在哪台机器上,然后去那台机器上的HashMap里取出计数器。方案2能够scale, 但是依旧是把所有元素都存了下来,代价比较高。如果允许近似计算,那么有很多高效的近似算法,单机就可以处理海量的数据。 -
采用近似算法Count-min sketch
Count-Min Sketch 算法流程:
- 选定d个hash函数,开一个 dxm 的二维整数数组作为哈希表
- 对于每个元素,分别使用d个hash函数计算相应的哈希值,并对m取余,然后在对应的位置上增1,二维数组中的每个整数称为sketch
- 要查询某个元素的频率时,只需要取出d个sketch, 返回最小的那一个(其实d个sketch都是该元素的近似频率,返回任意一个都可以,该算法选择最小的那个)
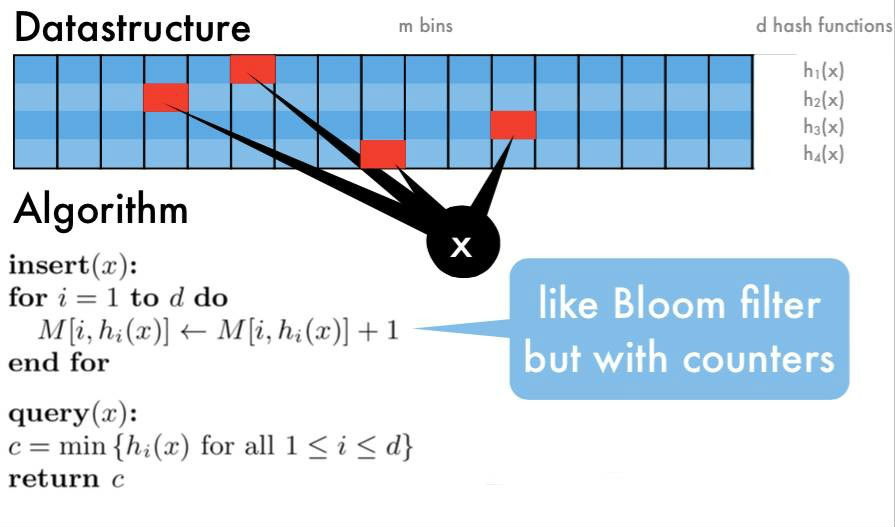
这个方法的思路和 Bloom Filter 比较类似,都是用多个hash函数来降低冲突。
- 空间复杂度
O(dm)。Count-Min Sketch 需要开一个dxm大小的二位数组,所以空间复杂度是O(dm) - 时间复杂度
O(n)。Count-Min Sketch 只需要一遍扫描,所以时间复杂度是O(n)
Count-Min Sketch算法的优点是省内存,缺点是对于出现次数比较少的元素,准确性很差,因为二维数组相比于原始数据来说还是太小,hash冲突比较严重,导致结果偏差比较大。
当需要查询某个元素的频率估计值时,也是先根据hash函数得到mapped counters,然后取其中的最小值即可,因为最小代表了冲突次数最少,相对最精确
很明显CM sketch对元素的频率只会高估而不会低估,且对于重复次数较多的元素的准确率比较高,但是对于出现次数较少的元素的准确率较低
因为使用矩阵,跟数据量大小没关系,很好地解决了LFU的内存开销问题。对于数据年龄,可以添加一个计数上限,一旦到达上限,所有记录的Sketch数据都除2,从而实现衰减效果,对于短暂热点数据,如果之后一直没有访问,count/2不断衰减,直至淘汰
布隆过滤器
布隆过滤器采用同样的思路,原理如下:
bloom算法类似一个hash set,用来判断某个元素(key)是否在某个集合中。
和一般的hash set不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一个标志,用来判断key是否在集合中。
算法:
1. 首先需要k个hash函数,每个函数可以把key散列成为1个整数。(sketch算法也是n个hash函数)
2. 初始化时,需要一个长度为n比特的数组,每个比特位初始化为0(一维数组也可以,或者二维矩阵)
3. 某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位置为1(用k个hash函数对k计算,得到k个值,把数组中的对应比特位设置为1)
4. 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。(查询key是,根据k个hash之后的结果,查询所有对应的比特位都是1,则存在,误判率关键点是hash函数的碰撞)
优点:不需要存储key,节省空间
缺点:
1. 算法判断key在集合中时,有一定的概率key其实不在集合中
2. 无法删除
以上是关于Caffeine缓存性能算法&布隆过滤器的主要内容,如果未能解决你的问题,请参考以下文章