Presto 动态过滤(dynamic filtering)原理与应用
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Presto 动态过滤(dynamic filtering)原理与应用相关的知识,希望对你有一定的参考价值。
早在2005年,Oracle 数据库就支持比较丰富的 dynamic filtering 功能,而 Spark 和 Presto 在最近版本才开始支持这个功能。本文将介绍 Presto 动态过滤的原理以及具体使用。
Apache Spark 的动态分区裁减
Apache Spark 3.0 给我们带来了许多的新特性用于加速查询性能,其中一个就是动态分区裁减(Dynamic Partition Pruning,DPP),所谓的动态分区裁剪就是基于运行时(run time)推断出来的信息来进一步进行分区裁剪,从而减少不必要的分区数据读取,以此提升查询性能。比如下面维度表 dim_iteblog 和事实表 fact_iteblog 进行 Join,其中 fact_iteblog.partcol 是一个分区字段。
SELECT * FROM fact_iteblog
JOIN dim_iteblog
ON (dim_iteblog.partcol = fact_iteblog.partcol)
WHERE dim_iteblog.othercol > 10
通过 Spark 的动态分区裁减,可以将执行计划修改成如下形式:
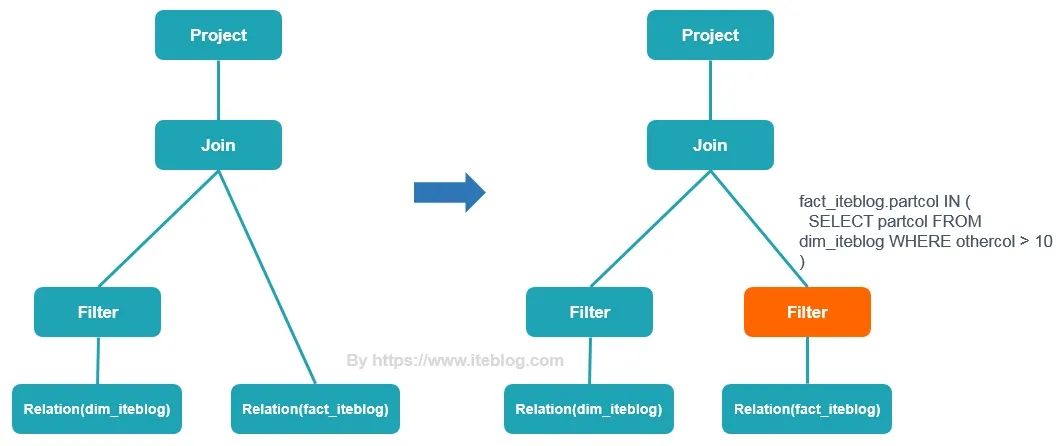
可见,在扫描 fact_iteblog 表时,Spark 自动加上了类似于 select partcol from dim_iteblog WHERE dim_iteblog.othercol > 10 的过滤条件,如果 fact_iteblog 表有大量的分区,而 select partcol from dim_iteblog WHERE dim_iteblog.othercol > 10 查询语句只返回少量的分区,这样可以大大提升查询性能。
关于 Spark 的动态分区过滤可以参见过往记忆大数据公众号的 《一文了解 Apache Spark 3.0 动态分区裁剪(Dynamic Partition Pruning)》、《一文了解 Apache Spark 3.0 动态分区裁剪(Dynamic Partition Pruning)的使用》、《图文理解 Spark 3.0 的动态分区裁剪优化》。
Presto 动态过滤
Presto 也支持上面的功能,这个功能称为动态过滤(Dynamic Filtering)。事实上,Presto 的动态过滤比 Spark 的动态分区裁减要丰富。因为 Spark 动态分区裁减只能用于分区表,而 Presto 的动态过滤支持分区表和非分区表,Presto 的动态分区包含 Partition Pruning(分区表) 以及 Row filtering(非分区表)。Presto 的动态分区功能最早出现在 Qubole 的一篇名为《SQL Join Optimizations in Qubole Presto》[1]文章上,其在 Qubole 内部的 Presto 分支上实现了动态分区功能,并且在2017年12月把这个功能反馈给社区 #9453[2]。遗憾的是,那个 Patch 并没有合并进社区,直到 Presto 0.241,这个功能正式加入到 master 分支。另外,Trino 是从 317 版本开始支持动态过滤的,要比 PrestoDB 早。
非分区表动态过滤
假设我们有以下的查询语句:
select a.* from lineitem_orc a join orders_orc b
on a.l_orderkey = b.o_orderkey and b.o_custkey=66007;
其中 lineitem_orc 和 orders_orc 表均为非分区表,在未启用动态过滤的时候,查询计划如下:
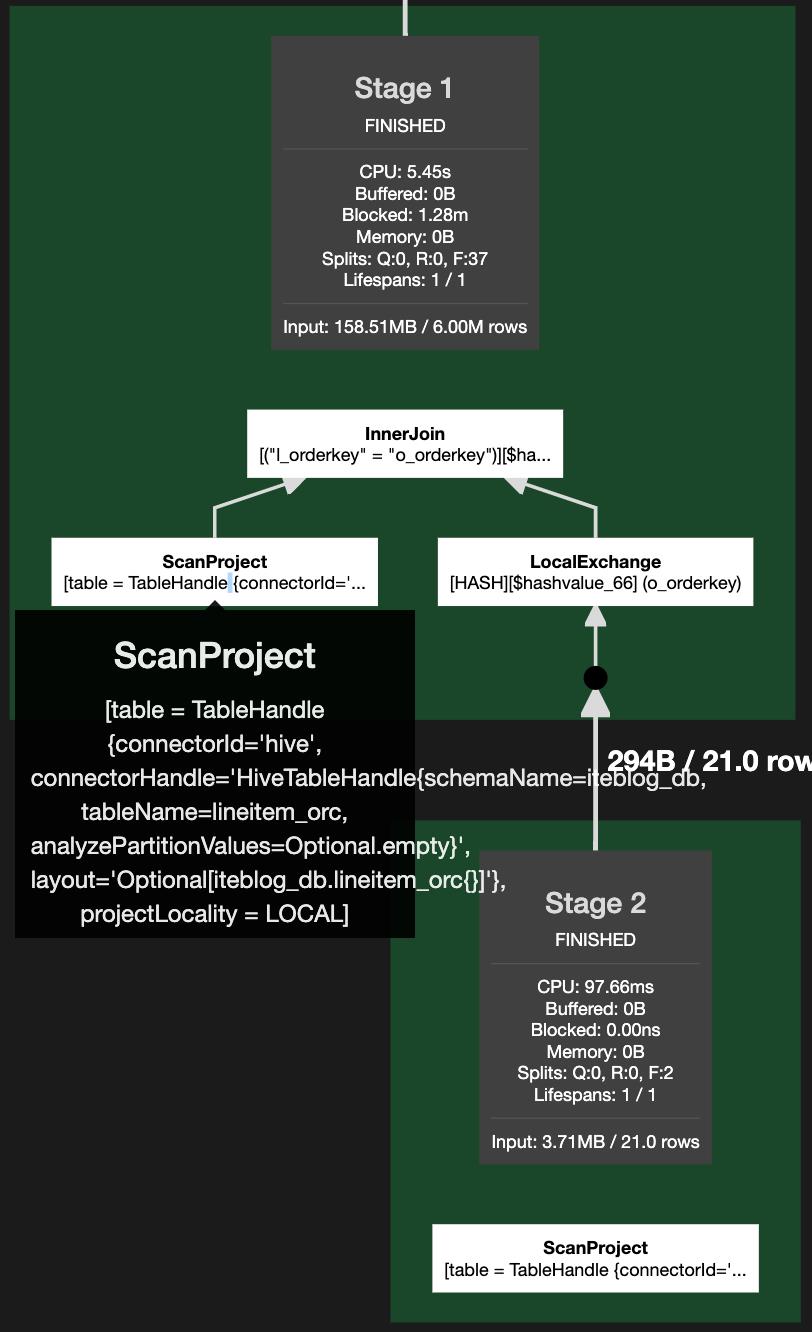
可见,查询 lineitem_orc 表的时候是全表扫描(ScanProject)。如果我们启动动态过滤,执行计划如下:
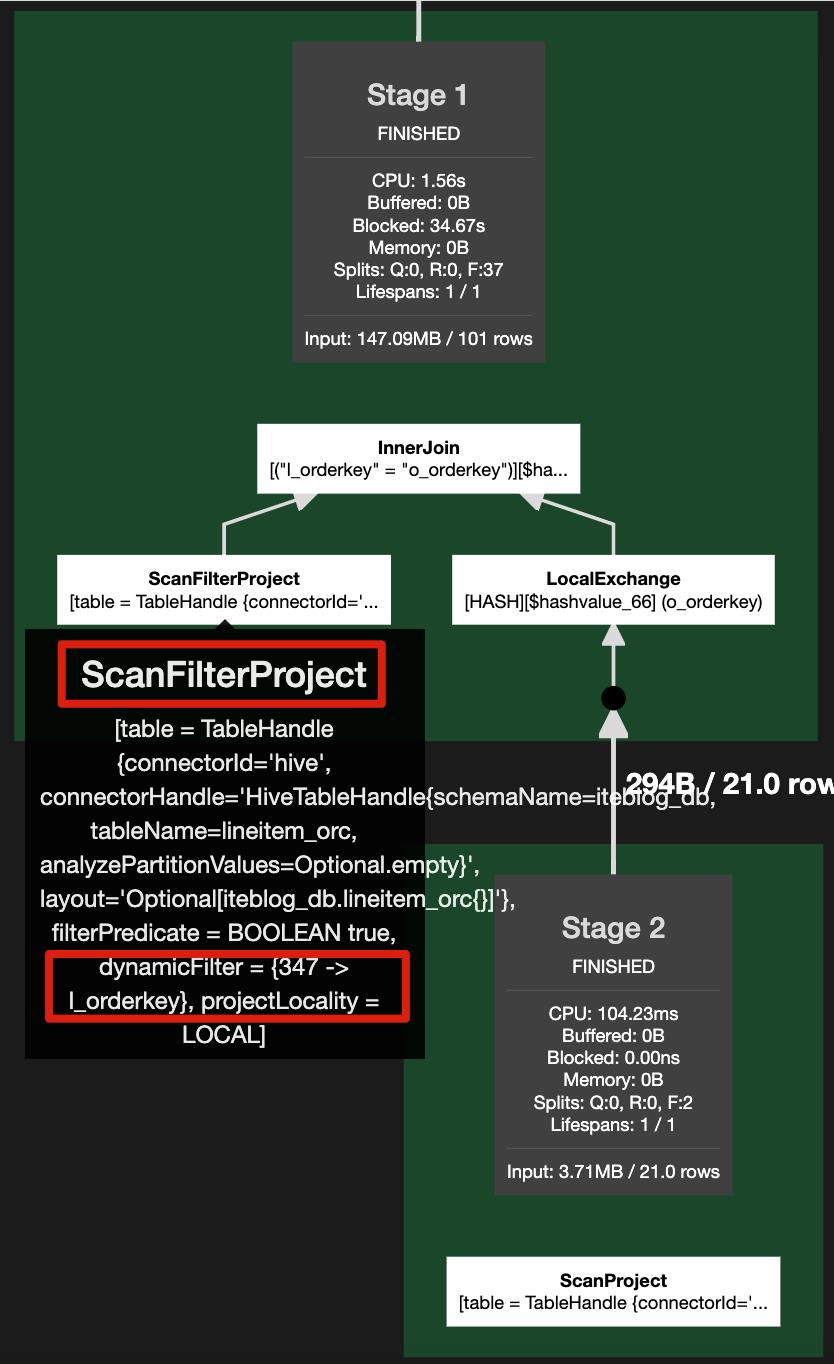
在扫描 lineitem_orc 表的时候,多了一个 dynamicFilter = {347 -> l_orderkey},这个就是 Presto 运行过程中自动加的过滤条件,相当于在查询 lineitem_orc 表的时候加了一个 l_orderkey in (select o_orderkey from orders_orc where o_custkey=66007)。
注意,目前 PrestoDB 的实现中只有 Hive 数据源支持动态过滤,而且非分区表动态过滤只支持 ORC 数据格式,其他不行。Trino 好像还支持 Memory 数据源;而且我们需要将 enable_dynamic_filtering Session 属性设置成 true,默认为 false,同时需要把 pushdown_filter_enabled 也设置成 true。
分区表动态过滤
分区表动态过滤和 Spark 的 DPP 效果类似。假设我们有以下的查询语句:
select a.* from lineitem_orc_p a join orders_orc_p b
on a.dt = b.dt and b.o_orderdate = DATE '1992-11-19';
其中,lineitem_orc_p 和 orders_orc_p 均为分区表。如果没有启用动态过滤,Presto 需要扫描 lineitem_orc_p 表所有分区里面的数据。事实上,o_orderdate = DATE '1992-11-19' 只在 orders_orc_p 的 dt=1992 这个分区里面有数据。如果开启动态过滤,我们只需要扫描 lineitem_orc_p 表 dt=1992 分区里面的数据,而直接忽略掉其他分区。开启动态过滤的执行计划如下:
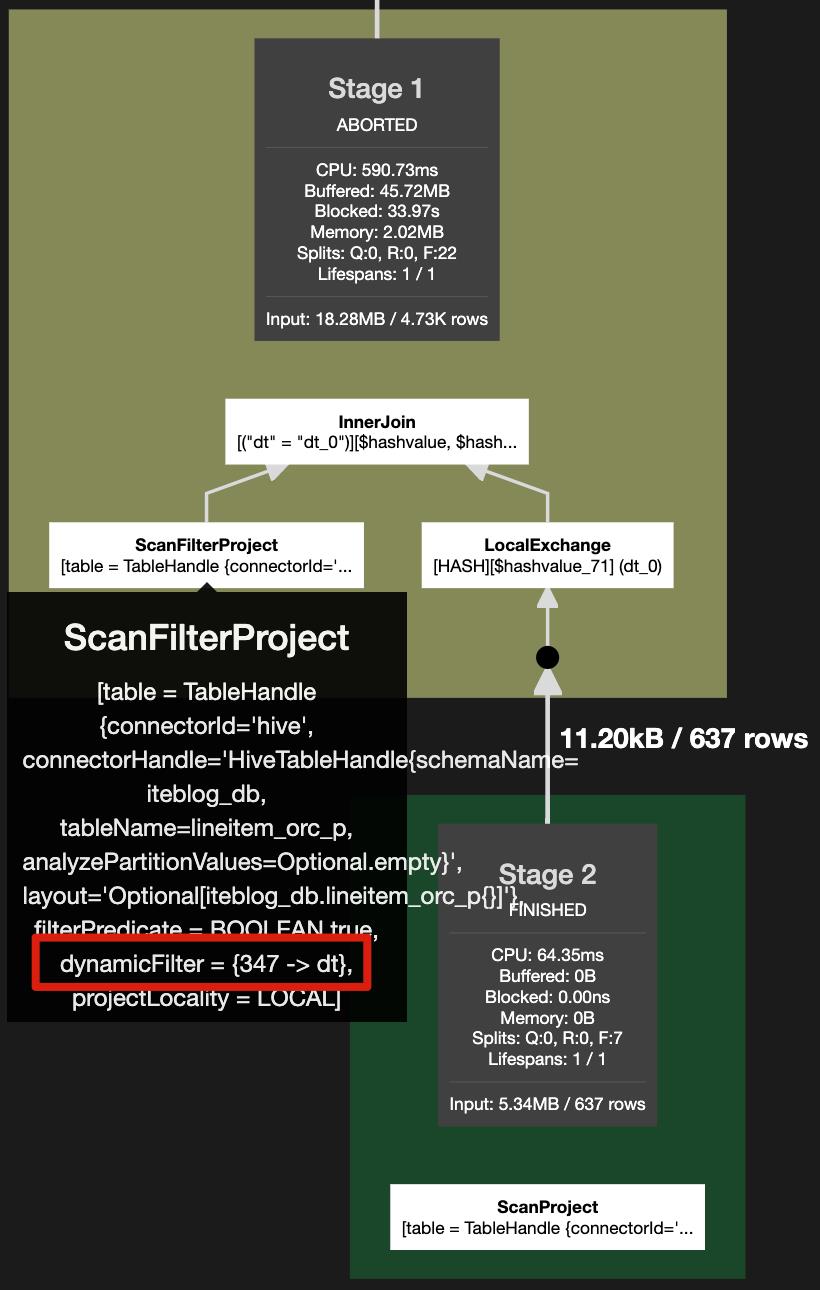
可见,lineitem_orc_p 表的读取多了一个 dynamicFilter = {347 -> dt} 动态过滤条件,其等价于 lineitem_orc_p.dt in (select dt from orders_orc_p where o_orderdate = DATE '1992-11-19')。
在这个例子里面,Presto 并不是在从元数据里面读取 lineitem_orc_p 分区的时候就把 dynamicFilter 加进去,而是会把 lineitem_orc_p 所有的分区都读出来。动态过滤实际上是在 com.facebook.presto.hive.HivePageSourceProvider#createPageSource 方法里面处理的,如下:
....
if (shouldSkipPartition(typeManager, hiveLayout, hiveStorageTimeZone, hiveSplit, splitContext)) {
return new HiveEmptySplitPageSource();
}
...
shouldSkipPartition 的实现如下:
private static boolean shouldSkipPartition(TypeManager typeManager, HiveTableLayoutHandle hiveLayout, DateTimeZone hiveStorageTimeZone, HiveSplit hiveSplit, SplitContext splitContext)
{
List<HiveColumnHandle> partitionColumns = hiveLayout.getPartitionColumns();
List<Type> partitionTypes = partitionColumns.stream()
.map(column -> typeManager.getType(column.getTypeSignature()))
.collect(toList());
List<HivePartitionKey> partitionKeys = hiveSplit.getPartitionKeys();
if (!splitContext.getDynamicFilterPredicate().isPresent()
|| hiveSplit.getPartitionKeys().isEmpty()
|| partitionColumns.isEmpty()
|| partitionColumns.size() != partitionKeys.size()) {
return false;
}
TupleDomain<ColumnHandle> dynamicFilter = splitContext.getDynamicFilterPredicate().get();
Map<ColumnHandle, Domain> domains = dynamicFilter.getDomains().get();
for (int i = 0; i < partitionKeys.size(); i++) {
Type type = partitionTypes.get(i);
HivePartitionKey hivePartitionKey = partitionKeys.get(i);
HiveColumnHandle hiveColumnHandle = partitionColumns.get(i);
Domain allowedDomain = domains.get(hiveColumnHandle);
NullableValue value = parsePartitionValue(hivePartitionKey.getName(), hivePartitionKey.getValue(), type, hiveStorageTimeZone);
if (allowedDomain != null && !allowedDomain.includesNullableValue(value.getValue())) {
return true;
}
}
return false;
}
在我们上面的例子中,allowedDomain 其实就是 dt = 1992,而 value 实际上是 lineitem_orc_p 各个分区的值,比如 dt = 1993、dt = 1992、dt = 1994 等。如果 value 中的值是 dt = 1993,那么 allowedDomain 肯定是不包含的,所以 lineitem_orc_p 中 dt = 1993 的分区直接忽略,也就是返回 HiveEmptySplitPageSource。如果 value 中的值是 dt = 1992,那么 allowedDomain 肯定是包含它的,这时候就不能忽略这个分区,需要读取。通过这个 Presto 实现了分区表的动态过滤。
注意,Presto 中分区表的动态过滤只支持 Hive 数据源。
Benchmarks
下面进行了 TPC-DS 查询测试,准备了五台 Worker node,配置为 r4.8xlarge,数据源为 ORC,其中下面的表是分区表:
catalog_returnsoncr_returned_date_skcatalog_salesoncs_sold_date_skstore_returnsonsr_returned_date_skstore_salesonss_sold_date_skweb_returnsonwr_returned_date_skweb_salesonws_sold_date_sk
下面查询在开启动态过滤时性能提升 20%。
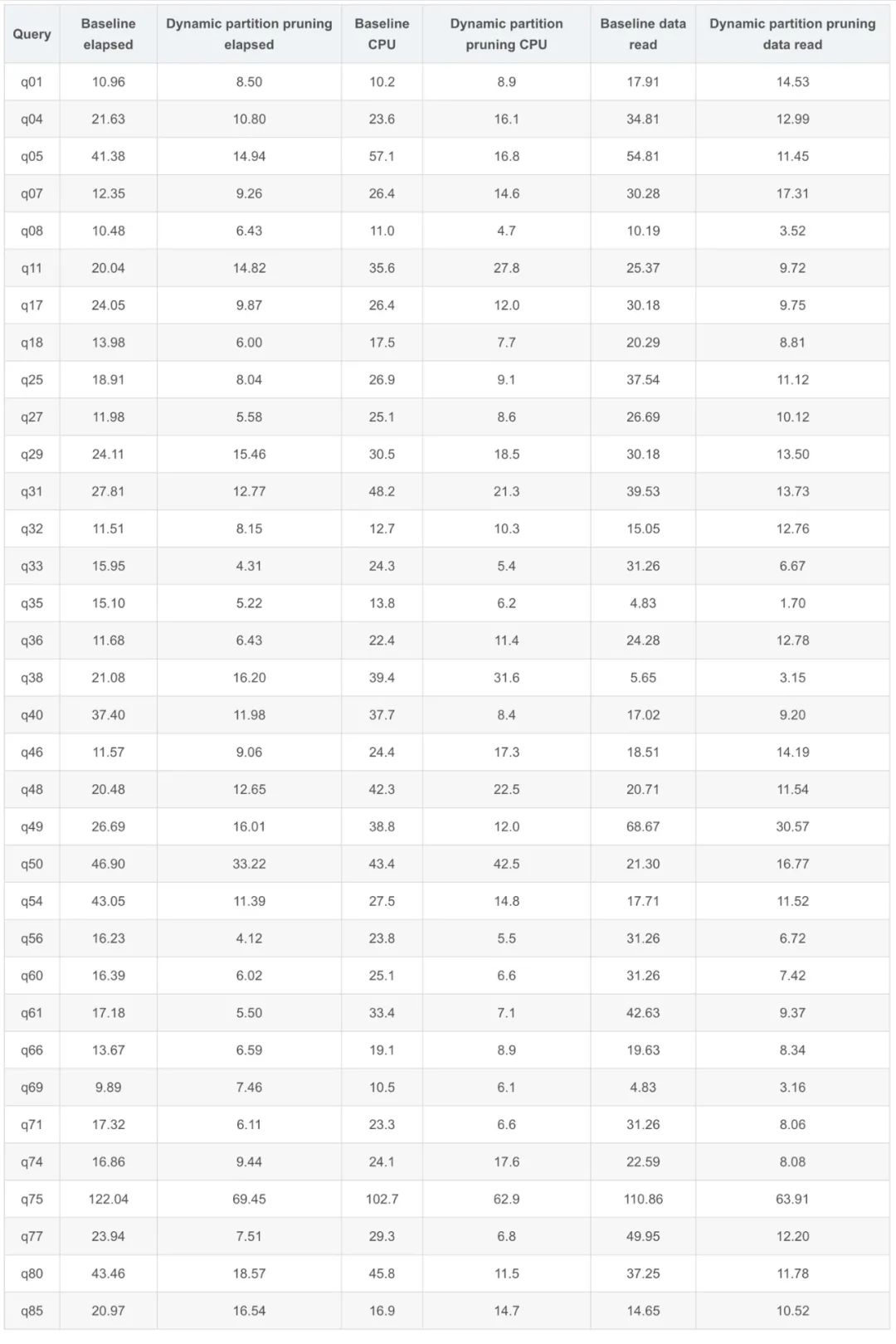
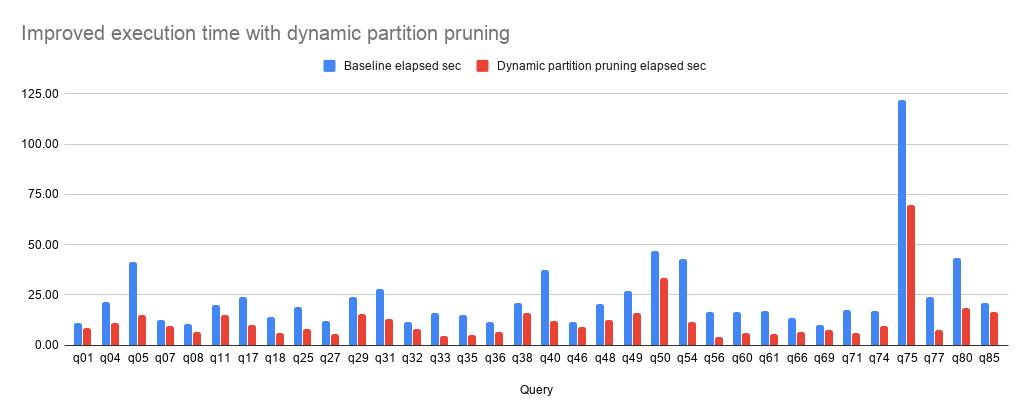
Q18 查询提高了50%以上的运行时间,同时平均减少了64%的 CPU 使用,数据读取减少66%。
Q7 查询性能提升了30%到50%,而 CPU 使用率平均降低了47%,数据读取减少54%。
Q29 查询性能提升了10%到30%,平均减少了20%的 CPU,数据读取减少27%。
总结
Presto 中的动态分区功能在一些场景下能够减少数据的扫描,提升查询性能。PrestoDB 和 Trino 都在最近的分支引入了这个功能,Trino 中的动态过滤目前应该是处于稳定状态;而 PrestoDB 中这个功能还处于实验状态(experimental)。而且目前来看覆盖的数据源有限,Trino 支持 Hive 和 Monery 数据源;而 PrestoDB 支持 Hive 数据源,而且对文件格式有一定的要求。
引用链接
[1] 《SQL Join Optimizations in Qubole Presto》: https://www.qubole.com/blog/sql-join-optimizations-qubole-presto/[2] #9453: https://github.com/prestodb/presto/pull/9453
以上是关于Presto 动态过滤(dynamic filtering)原理与应用的主要内容,如果未能解决你的问题,请参考以下文章