Redis源码解析-SDS简单动态字符串
Posted pianozcl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis源码解析-SDS简单动态字符串相关的知识,希望对你有一定的参考价值。
前言
SDS是Redis基础数据结构之一,不同于C字符串(以/0结尾,无法保证二进制安全),SDS为Redis定义的一种抽象类型,该类型有诸多优点如
-
获取字符串长度时间复杂度O(1) -
高效的扩容机制,还能杜绝缓冲区溢出 -
惰性释放空间,减少内存重分配次数以提高性能 -
二进制安全 -
兼容部分C字符串函数
正文
1. 获取源码
自行官网获取,SDS字符串源码主要在sds.c中如下图
2. SDS数据结构
以下代码是数据结构的定义,可以看到字符串有五种定义。只有第一种结构不一样,下面四种结构类似
//sds数据结构
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 低三位表示类型,高5位表示字符串长度*/
char buf[]; //用于存放字符串的数组,由malloc函数动态分配
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; //记录buf已使用长度
uint8_t alloc; //记录buf总长度
unsigned char flags; /* 低三位表示类型, 高五位没被使用 */
char buf[]; //用于存放字符串的数组,由malloc函数动态分配
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
以上参数,其中len,alloc,flags都是字符串的描述信息,可以看作是头信息。真正存储字符串的是buf[]数组,这个数组是由malloc函数动态分配的
-
由于结构定义了len,因此可以在常数级时间复杂度获取字符串长度,而且通过len而不是/0来判断字符串是否结束,保证了二进制安全
之所以要定义多种数据结构,是考虑到内存浪费问题,当我们存储字符串时候,无论是key还是value,都会以SDS字符串的形式分配。如果我们分配一个很小的字符串,却占用了很大的头部,就不合适了
那么问题来了,如何区分一个字符串该用哪种数据类型?
答案是flags,它是用来区分不同的数据类型的,flags位char类型占1字节,但是一共有五种数据类型,因此三位能表示8种足够了,所以就用低三位来表示类型。在第一种数据结构中,flags的高五位也用来表示字符串长度
下面之分析第一,二种数据结构的不同之处。三,四,五结构同二
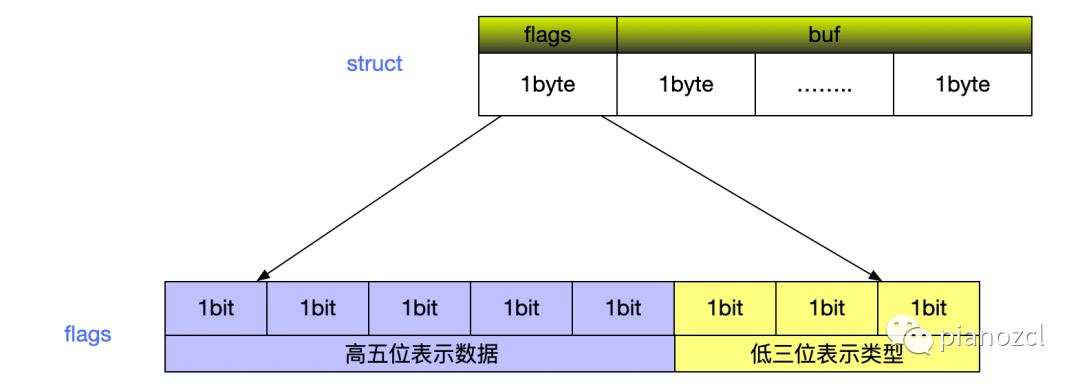
sdshdr5
对于第一种结构如下图,sdshdr5类型的数据结构,直接用flags的高五位来表示数据
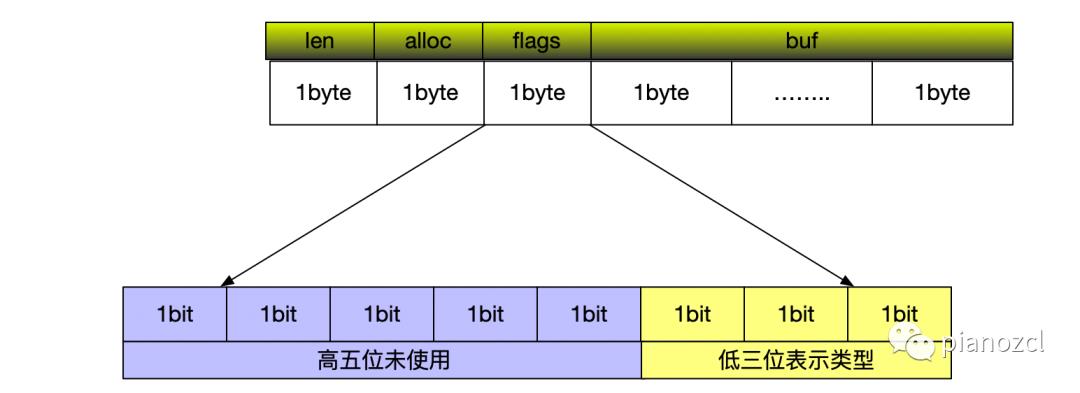
sdshdr8
对于第二种数据结构。首先说明一下uint8_t是SDS封装的抽象数据类型,其中的8代表8位,因此uint8_t len;这么声明代表变量len占8位也就是1字节。sdshdr16,sdshdr32,sdshdr64和8一样,区别就是len和alloc前面的抽象数据类型不同,也就是占用空间不一样
对于数据结构的定义,我们注意到都有一个关键字__attribute__ ((packed)) ,改关键字供GCC使用,作用是使结构按1字节对齐。不加该关键字通常是按照变量的最小公倍数字节对齐。
下面用代码演示packed关键字效果
#include <stdio.h>
#include <string.h>
int main(){
struct __attribute__ ((__packed__)) sdshdr32{
long len;
long alloc;
unsigned char flags;
char buf[];
};
struct sdshdr32 s;
printf("sizeof sds32 is %lu", sizeof(s));
return 1;
}
以上代码模拟SDS32抽象类型,long类型占8字节(我这里是Mac OS,类unix系统long占8字节,如果是windows,long占四字节,这里会四字节对齐),char占1字节。下面看不加packet和加packet关键字的执行结果。可以看到没有加packed,总共占了24位。有packed修饰占了17字节
3. 创建字符串
以下是创建字符串的代码,说明一下参数
-
*init:指向字符串的指针,该参数如果传"SDS_NOINIT",则不进行初始化sh指针指向的空间,如果传NULL,则将sh指针指向的空间初始化为0 -
initlen:字符串长度
sds sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
char type = sdsReqType(initlen); //根据字符串长度选择类型
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
int hdrlen = sdsHdrSize(type); //计算不同头部需要的长度
unsigned char *fp; /* flags pointer. */
//sh指针指向的整个结构,使用malloc分配内存,+1是因为'/0'结束符
sh = s_malloc(hdrlen+initlen+1);
//这段逻辑就是我上面对init的参数说明,其中SDS_NOINIT是宏定义,内容是"SDS_NOINIT"
if (init==SDS_NOINIT)
init = NULL;
else if (!init)
//该函数会将sh指向的空间初始化为0
memset(sh, 0, hdrlen+initlen+1);
if (sh == NULL) return NULL;
//s指针是指向buf的指针,这里通过sh指针进行偏移头部的长度计算指针指向的位置
s = (char*)sh+hdrlen;
//通过s指针偏移1获得flags指针,因为内存单位是字节
fp = ((unsigned char*)s)-1;
//根据类型赋值结构成员
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
...
}
case SDS_TYPE_32: {
...
}
case SDS_TYPE_64: {
...
}
}
if (initlen && init)
memcpy(s, init, initlen);
s[initlen] = '�';//这里注意最终返回的是s指针,指向buf的,因此可以兼容部分c函数
return s;
}
以上就是创建一个字符串的过程,需要注意的点主要有:
-
sh指向的是SDS结构,而真正返回的s指针是指向buf的 -
创建字符串会根据字符串长度选用不同的结构 -
计算结构体成员的指针地址往往是通过偏移量
上面还有个有意思的函数,计算头部的函数,源代码如下。了解网络掩码(netmask)原理的同学肯定能很快明白,我们可以通过IP与网络掩码进行逻辑与运算,从而计算出该IP所在的子网。SDS计算头部类型用了通用的方式,其中宏定义SDS掩码为7,也就是二进制111,对应低三位类型。而SDS_TYPE_5-64在宏定义分别是0,1,2,3,4,同样是进行逻辑与运算得出其对应的类型
#define SDS_TYPE_MASK 7
static inline int sdsHdrSize(char type) {
switch(type&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return sizeof(struct sdshdr5);
case SDS_TYPE_8:
return sizeof(struct sdshdr8);
case SDS_TYPE_16:
return sizeof(struct sdshdr16);
case SDS_TYPE_32:
return sizeof(struct sdshdr32);
case SDS_TYPE_64:
return sizeof(struct sdshdr64);
}
return 0;
}
4. 内存释放
内存释放的两个方法
//通过偏移s指针定位到首部,直接调用free释放内存
void sdsfree(sds s) {
if (s == NULL) return;
s_free((char*)s-sdsHdrSize(s[-1]));
}
//将len设置为0,旧值还在内存,但是数据可以覆写,不需要重新分配内存
void sdsclear(sds s) {
sdssetlen(s, 0);
s[0] = '�';
}
5. SDS扩容策略
当字符串长度有改动的时候,如何防止缓冲区溢出?,由如何保证高性能?,这就是SDS扩容策略解决的问题
使用到扩容策略的函数由很多,这里拿一个拼接字符串函数说明
首先该函数s为原有字符串结构。t指针指向第二个字符串,len为其长度。它的作用是
-
计算当前字符串长度 -
通过新字符串长度,调用 sdsMakeRoomFor,来得到扩容后的s指针 -
进行字符串拼接,这里是 二进制安全的,因为这里的curlen长度是不包含"/0"的 -
最后返回s指针
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);
sdssetlen(s, curlen+len);
s[curlen+len] = '�';
return s;
}
其中扩容策略是sdsMakeRoomFor函数实现的,源码如下
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s); //计算剩余空间
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
//如果剩余空间足够不需要扩容直接返回
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen); //原有字符串长度加新字符串长度
if (newlen < SDS_MAX_PREALLOC) //SDS_MAX_PREALLOC为宏定义为1M大小
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen); //根据长度计算需要的类型
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) { //如果类型不变直接s_realloc扩容即可
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
//如果类型变了,需要malloc重新分配内存
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1); //将buf内容移动到新的位置
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;//为flags赋值
sdssetlen(s, len); //为len赋值
}
sdssetalloc(s, newlen);//为alloc赋值
return s;
}
以上代码表明了扩容机制的几种情况
-
当剩余空间足够,无需扩容 -
当新的长度大于剩余空间,如果新的长度小于1M则容量翻倍,大于1M则加1M -
根据新的长度计算类型,类型不变则通过recalloc扩容即可,类型变的话需要malloc重新分配内存
这种扩容机制明显的优点是,减少修改字符串时内存的重分配次数,这对提高性能由很大帮助
总结
分析了SDS源码,就能明白Redis为何如此高效。总的来说,SDS动态字符串对细节把控的很好。例如数据结构的定义,以及编译器层面的优化,选择数据结构策略,都极大的节省了内存空间。而内存的分配,释放,以及扩容,考虑了各种情况
以上是关于Redis源码解析-SDS简单动态字符串的主要内容,如果未能解决你的问题,请参考以下文章