redis 主从内存数据一致,内存差一倍经典案例
Posted 数据库小兵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis 主从内存数据一致,内存差一倍经典案例相关的知识,希望对你有一定的参考价值。
一、背景:
业务反馈监控显示主从内存不一致,并且从节点之间也不一致,主节点内存大约21GB,大部分从节点内存是12GB左右,个别节点内存是21GB左右,如下图两个slave 节点内存使用监控图
二、分析过程:
1.确认数据是否一致,是否是大量key 过期导致
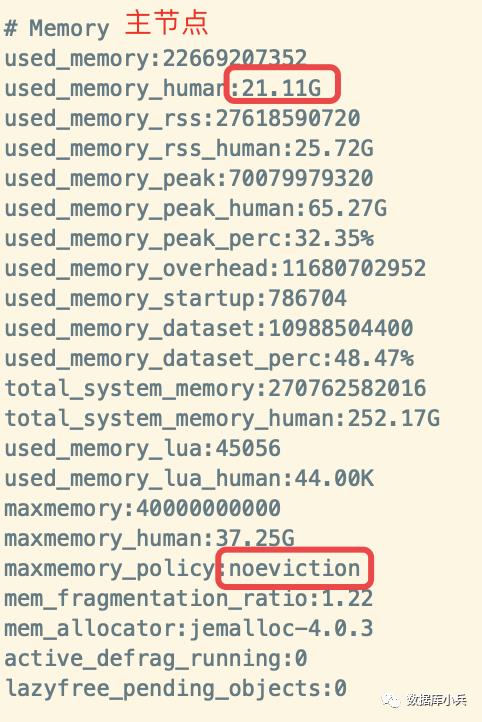
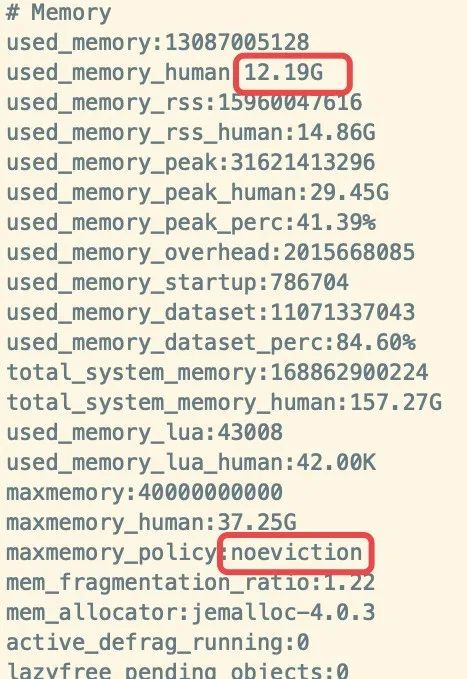
命令行登陆查看主从内存确实差距很大,同时观察主从节点总keys如下:


可以发现主从total keys 基本相同,过期keys大约25w,总keys 950w左右,基本可以确定主从数据是一致的,那是否存在主从大量key过期呢,监控如下:
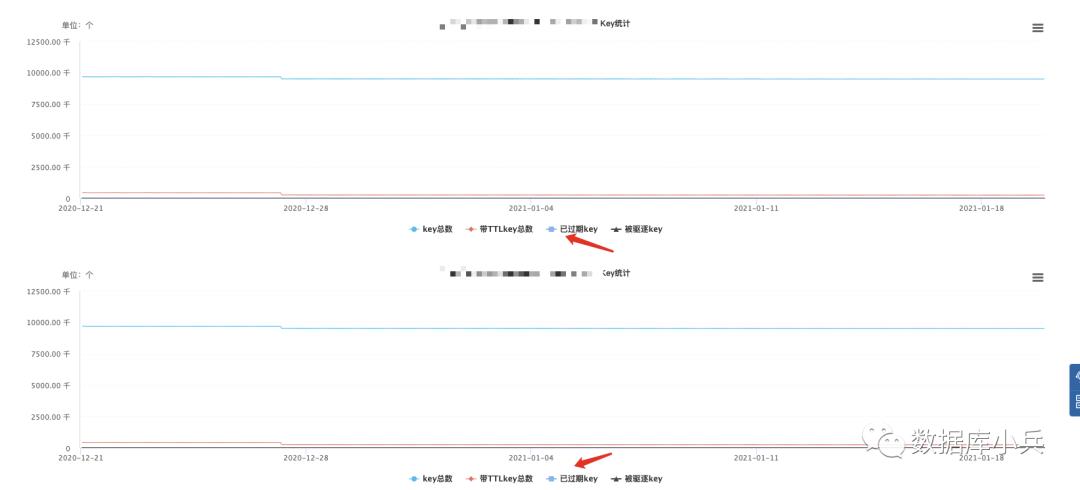
查看最近一个月的主从key 淘汰情况发现并没有出现某段时间大量key 淘汰,并且HZ设置已经足够大,不会因为未及时淘汰过期key而出现内存差异这么大的情况
2.尝试手动主从bgsave rdb 快照恢复到新实例
在主节点bgsave然后找一个内存是12GB的节点bgsave出rdb快照后发现两者实际大小一致,更加确定主从数据是一致的并未存在数据丢失的情况,然后恢复到新实例启动,查看info memory 如下:
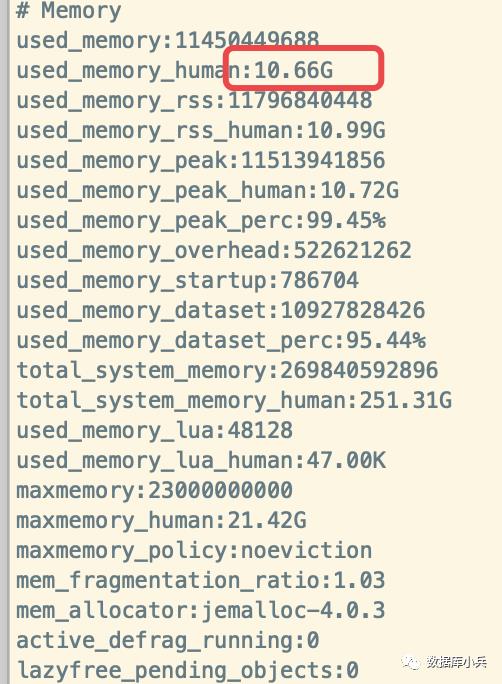
显示内存大约是10G多,说明实际使用内存确实是十几GB
3.尝试给主节点扩容一个新的slave节点
扩容完成后发现内存和主节点一致是21G左右如下:
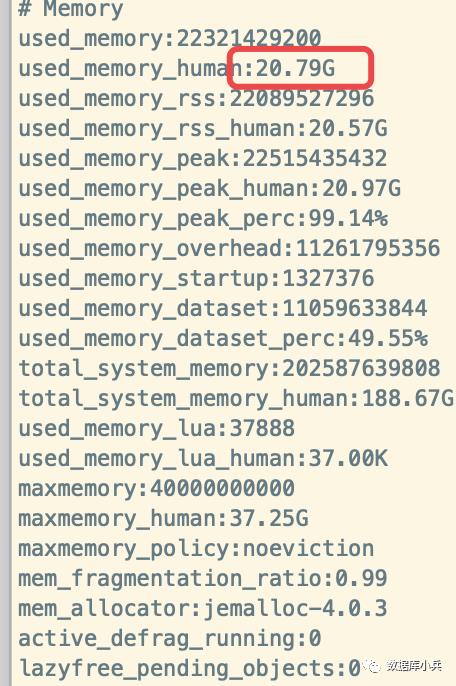
至此,已经懵逼.....why...
4.求助各种nb的技术群...未响应
5.github redis 用中式英文发issue 得到了回应,but 没解决问题
6.重新思考内存到底去哪里了
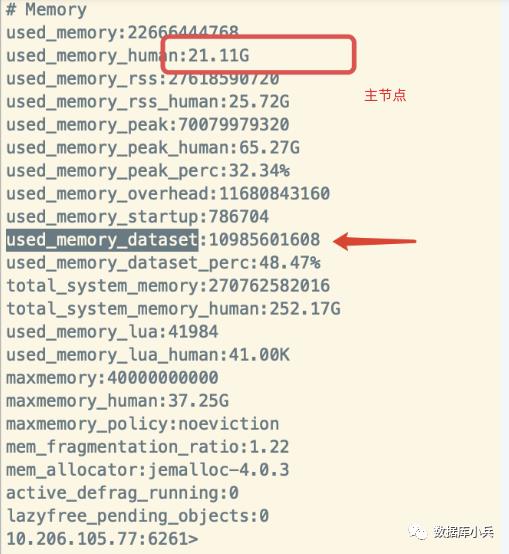
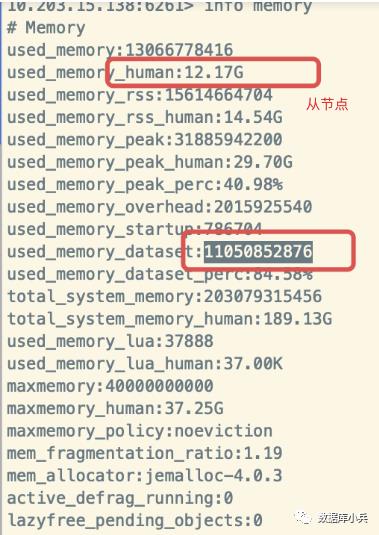
下面先了解下这几个参数的含义:
used_memory_dataset_perc:数据占用的内存大小的百分比,100%*(used _memory_dataset/(used_memory-used_memory_startup))
used_memory_dataset:数据占用的内存大小,即used_memory-used_memory_overhead
used_memory_overhead:Redis为了维护数据集的内部机制所需的内存开销,包括所有客户端输出缓冲区、查询缓冲区、AOF重写缓冲区和主从复制的backlog
从上图可以看出Mster和Slave 内存差距就在 used_memory_overhead ,主节点占用了10G左右,从节点占用1G,下面查看差出的内存是哪块占用的
(1)客户端缓冲区 :
1) "client-query-buffer-limit"2) "1073741824"3) "client-output-buffer-limit"4) "normal 32000000 16000000 5 slave 0 0 0 pubsub 33554432 8388608 60"
(2)查询缓冲区:
client list 查看omem!=0 的连接发现并没有
(3)主从都是关闭aof 的,所以就不存在aof 重写缓冲区
(4)主从复制的backlog:
主节点查看是10G
5) "repl-backlog-size"6) "10737418240"从节点查看是1G5) "repl-backlog-size"6) "1073741824"
显而易见主从差距内存就差距在这了,拨云见雾的感觉
repl-backlog-size 这个值线上默认设置是1G,期间估计有人动态改过,这个值太小的话可能造成从节点一直进行全量同步,所以谨慎设置,默认1G 可以满足大部分场景需求了,此业务存在很高的qps读写请求,至此基本断定是前人遇到过从节点一直全量同步而手动修改了内存导致出现这么诡异的现象了
三、总结
还需要仔细研究redis info 中的一些参数,可能一些不起眼的参数恰恰在出现故障的时候会起大作用,在自己打不开思路的时候多和业务同事沟通交流或许就会打开另一扇窗户
以上是关于redis 主从内存数据一致,内存差一倍经典案例的主要内容,如果未能解决你的问题,请参考以下文章
Redis分片主从哨兵集群,原理详解,集群的配置安装,8大数据类型,springboot整合使用