好代码实践:基于Redis的轻量级分布式均衡消费队列
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了好代码实践:基于Redis的轻量级分布式均衡消费队列相关的知识,希望对你有一定的参考价值。
简介: 好代码,给人第一个印象的感觉,就像一篇好文章一样,读起来朗朗上口。不同的文章有不同的风格体裁,不同的代码也有不同的编程风格要求。Python有严格的缩进,像诗歌一样工整对仗;C语言面向过程像散文一样形散神聚,意境深邃;Java语言面向对象又像是写小说一样,能勾勒出一个一个人物形象。但是无论哪一种文章体裁,他的可读性和可理解性都非常重要,只有文章是可读的可理解的,才会吸引更多的读者去读它,让他流传下去,代码也一样,它的可维护性和可读性也非常重要,保证代码可用性,提高代码的简洁程度和可维护程度,才能让我们的代码在计算机上跑的更远,更久。

作者 | 玄翰
来源 | 阿里技术公众号
一 我对好代码的看法
1 什么是好代码
如果你读过《设计模式之美》,你可能会觉得玩转各种设计模式,符合设计模式的6大基本原则的代码就是好代码;如果读过《clean code》,你可能会觉得好代码的一个标准——整洁;如果你经常研读spring源码,你可能会觉得精妙的设计、高度的抽象,灵活的配置才是好代码;就像是一本书,一千个读者一千个哈姆雷特,每个人按照自己的认知都会有自己的判断。
2 我认为的好代码
如前文所述,不同的人对好代码的认知标准是不同的,我认为的好代码,也局限于我的认知水平,也许今天我觉得是好代码,随着认知的提升,改天也会有不同的想法;就目前的认知而言,我认为的好代码的一些特点:
可用性
对,你没看错,好代码,一定是可用的,可以work的,如果一段代码只是看着好看,用了各种花里胡哨的编码技巧、手法,但是不能work,那就失去了它存在的意义了。所以,好代码,最最最重要的一个特点就是可用性。
可读性
我认为好代码的第二个特点就是可读性,我们的写代码的目标用户有两类,第一类是给编译器看的;第二类是给维护它的程序员看的。针对第一类用户,只要你符合它的语法规范,它就认识,它就可以执行;而第二类用户,就是后期不断的维护它、升级它的程序员同学,如果这段代码,维护它的人都读不懂,那他的长期存在的意义也就不大了。
其他优秀的特点
可维护性、可扩展性、可复用性、强鲁棒性、可测试性等。
好代码的其他优秀特点太多了,不一一列举了。
3 让code在计算机上起舞
回到根源,我们写代码的是干嘛?为的是把我们的所思所想通过计算机认识的指令告诉它,让它来替我们做我们想做的事情。好代码,不仅可以简单的完成我们所思所想,更能够快速、高效、完备的执行。让我们的code一起在计算机上起舞吧。
二 我们为什么要做
2020年五一期间,当大家都在享受五一假期的快乐时光时,我们突然收到hbase报警,整个hbase的IO压力已经接近瓶颈,直接影响数据读写,临时扩容hbase才勉强支撑过去。按照这个发展趋势,一旦遇到业务高峰时,hbase的读写直接会给整个业务链路带来瓶颈问题。为了能够解决海量巴枪数据实时写入hbase+solr时产生的高IO压力,我们设计出一款基于redis实现的轻量级分布式均衡消费队列,实现巴枪数据按照一定规则进行sharding到不同的队列中,实现批量数据攒批去重,然后按批写入hbase+solr,从而降低hbase+solr的IO压力。
三 我们怎么做的
组件整体设计思路:
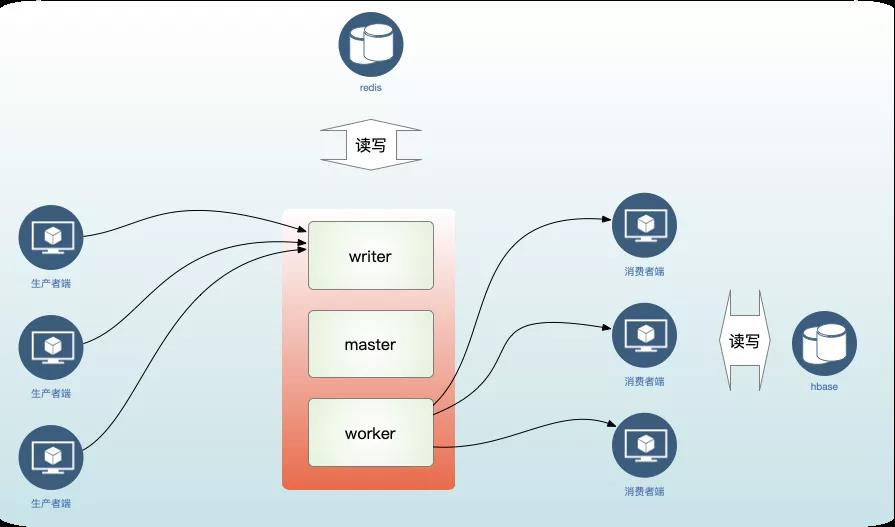
整个组件主要分为三大核心模块,master(主节点)、writer(数据写入节点)、worker(工作节点)。
设计机制:弱中心机制,任何一个配置好的节点都可能成为master(主节点)、writer(数据写入节点)、worker(工作节点),具备高可用能力,不存在单机单点瓶颈问题。
master(主节点)职责:
- 负责实时探活worker(工作节点)是否有变化,掉线情况;
- 负责分配任务队列到存活的worker(工作节点);
- 负责实时检测整个redis队列的负载情况。
writer(数据写入节点)职责:
- 负责分配实时写入任务sharding到不同的队列;
- 负责检测当前写入队列的负载情况。
worker(工作节点)职责:
- 负责实时汇报当前worker(工作节点)的状态,保持心跳;
- 负责定时消费该worker(工作节点)负责的数据。
伟大的linux大神曾说过,"Talk is cheap,让我看看代码"。
四 我们做了什么
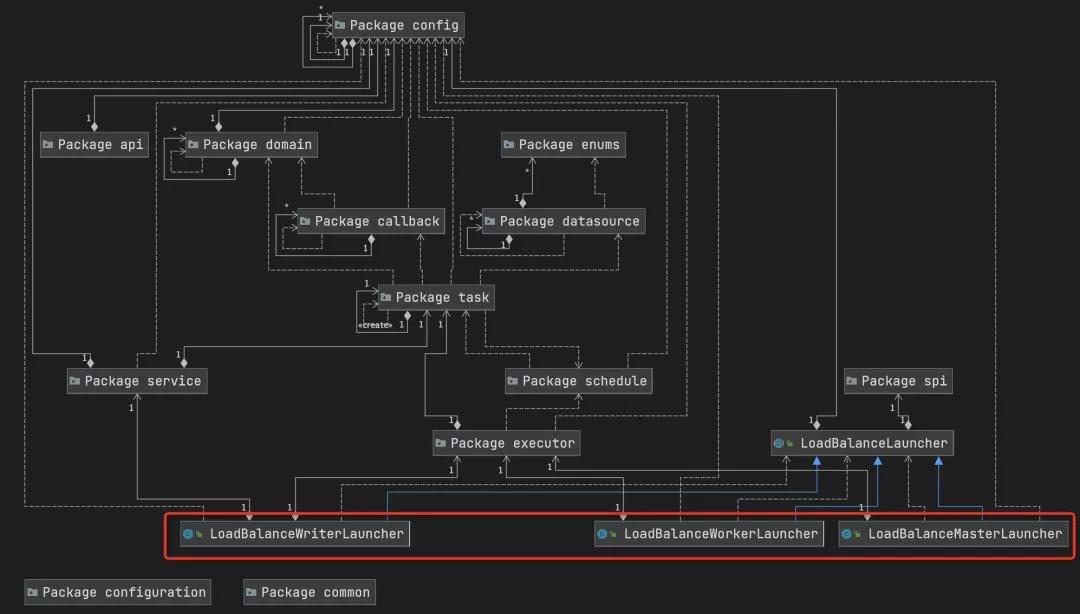
1 整个组件的包结构图
2 简洁的代码结构
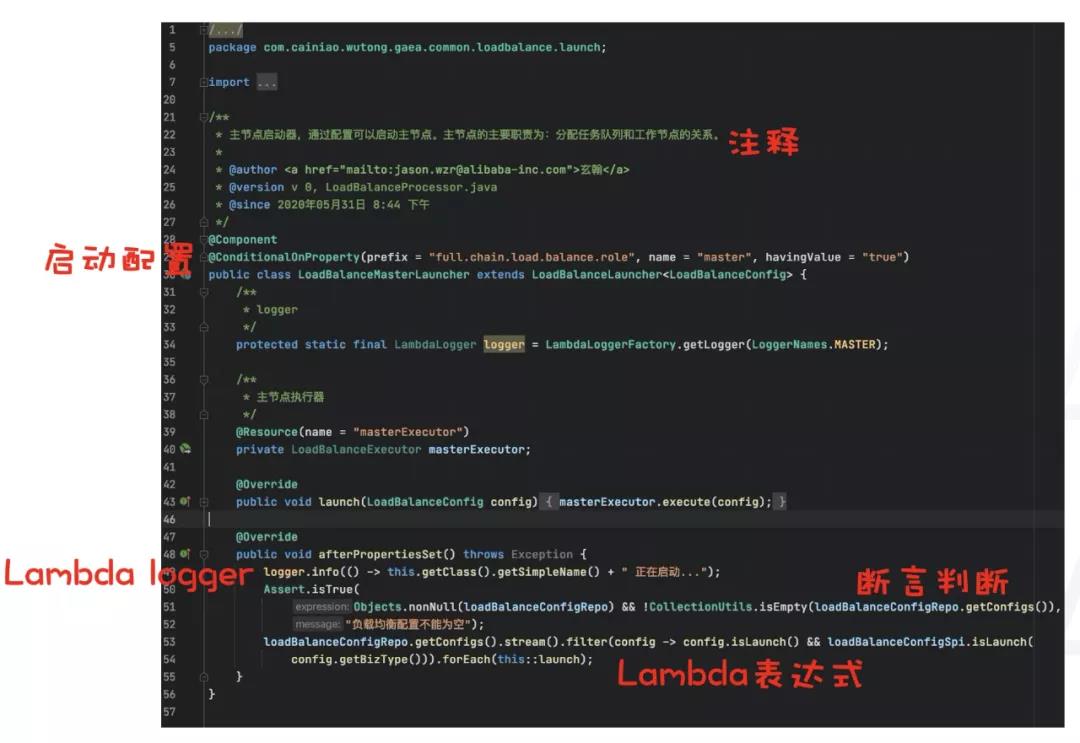
- 清晰的注释,介绍类的作用和职责
- 启动项配置,灵活的配置,控制模块是否启动。
- lambda-logger/lambda表达式,通过简洁语法结构,轻量化代码冗余,提高代码简洁度。
- 断言判断,替换传统的if-else判断,提高代码的可读性。
整个工程一共60个类,核心代码共1623行, 平均每个类的代码行数为27.05行,最大的一个类代码行数不超过200行。
3 强大的扩展性

通过钩子回调方式的设计,方便接入的用户能够快速的注入自己的回调实现方法,进行快速扩展业务能力。
4 线上日志展示截图
日志文件

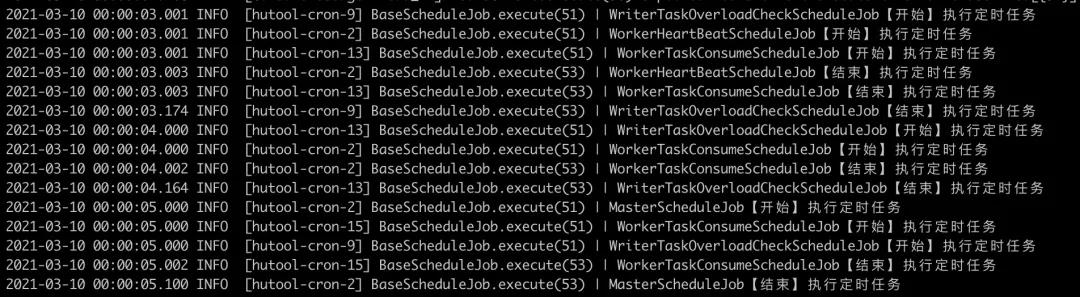
master队列分配日志
worker数据消费日志
writer队列负载检测日志

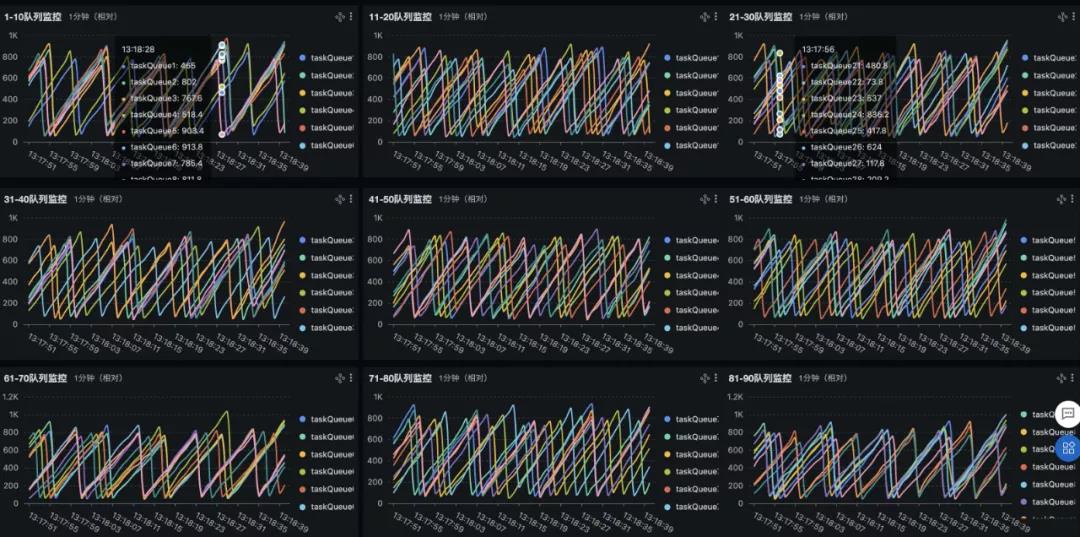
redis消费队列监控大盘
五 我们的收益
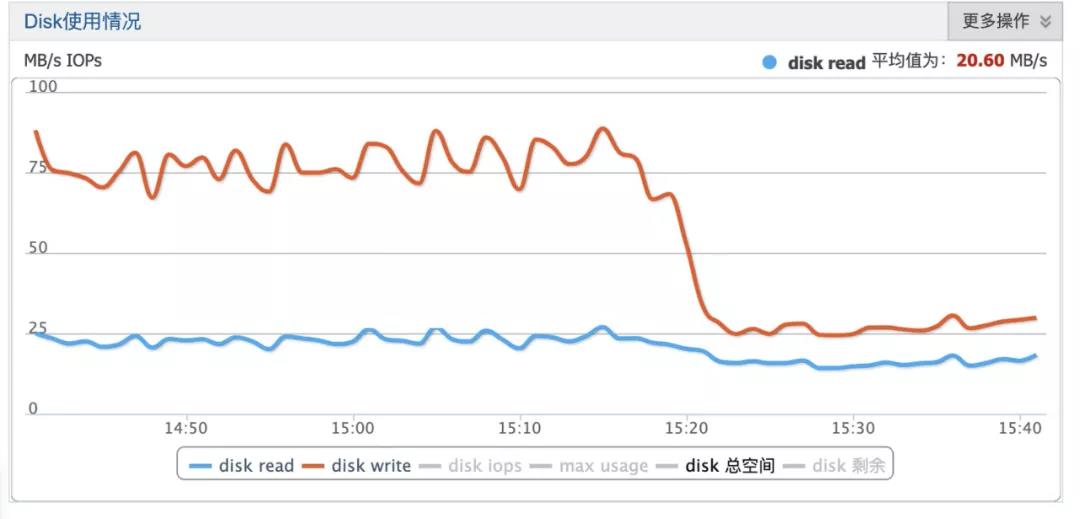
组件部署上线之时,hbase服务端监控指标变化,实现hbase整体使用水位接近50%的优化。
hbase IOPS使用监控
hbase CPU使用监控
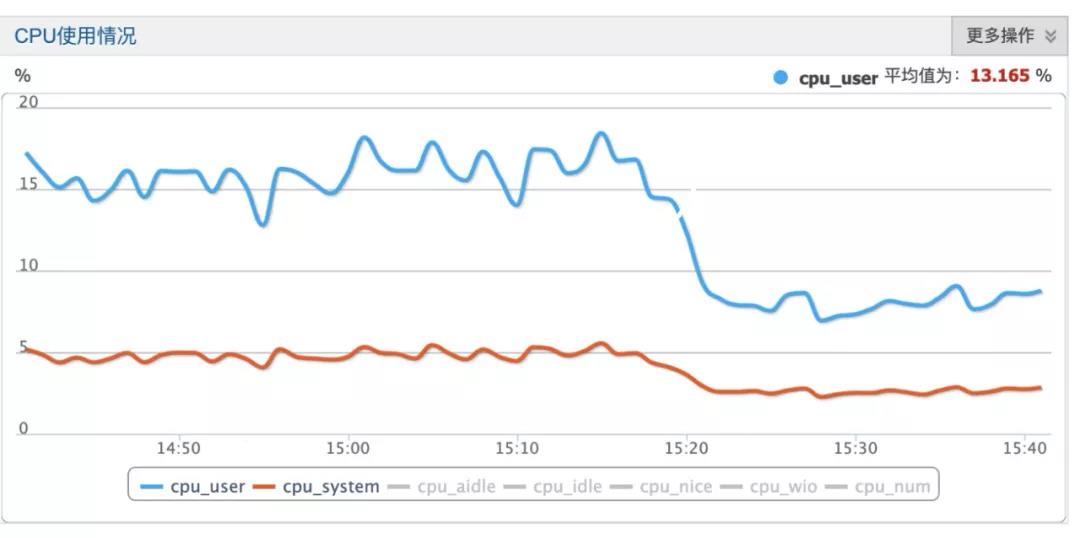
六 我们的展望
- 独立抽象组件,基于Redis的轻量级分布式均衡消费队列,是一个全自主创新研发出来的,高可用,可扩展的基础组件,目前已经封装成为一个独立的spring-boot-starter,具备高复用性和高扩展性能力。
- 广阔的使用场景,基于组件灵活的配置,在涉及的分布式任务队列场景时,都可以使用到它,例如任务中心分发等可以做到天然的均衡负载。
- 拥抱开源,未来希望将组件开源出去。
七 我的一些理解
好代码,给人第一个印象的感觉,就像一篇好文章一样,读起来朗朗上口。不同的文章有不同的风格体裁,不同的代码也有不同的编程风格要求。Python有严格的缩进,像诗歌一样工整对仗;C语言面向过程像散文一样形散神聚,意境深邃;Java语言面向对象又像是写小说一样,能勾勒出一个一个人物形象。但是无论哪一种文章体裁,他的可读性和可理解性都非常重要,只有文章是可读的可理解的,才会吸引更多的读者去读它,让他流传下去,代码也一样,它的可维护性和可读性也非常重要,保证代码可用性,提高代码的简洁程度和可维护程度,才能让我们的代码在计算机上跑的更远,更久。
本文为阿里云原创内容,未经允许不得转载。
以上是关于好代码实践:基于Redis的轻量级分布式均衡消费队列的主要内容,如果未能解决你的问题,请参考以下文章