Hologres如何支持超高基数UV计算(基于roaringbitmap实现)
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hologres如何支持超高基数UV计算(基于roaringbitmap实现)相关的知识,希望对你有一定的参考价值。
简介: 本文将会介绍Hologres基于roaringbitmap实现超高基数的UV计算
RoaringBitmap是一种压缩位图索引,RoaringBitmap自身的数据压缩和去重特性十分适合对于大数据下uv计算。其主要原理如下:
- 对于32bit数, RoaringBitmap会构造2^16个桶,对应32位数的高16位;32位数的低16位则映射到对应桶的一个bit上。单个桶的容量由桶中的已有的最大数值决定
- bitmap把32位数用1位表示,可以大大地压缩数据大小。
- bitmap位运算为去重提供了手段。
主体思想(T+1):把上一天的所有数据根据最大的查询维度聚合出的uid结果放入RoaringBitmap中,把RoaringBitmap和查询维度存放在聚合结果表(每天百万条)。之后查询时,利用Hologres强大的列存计算直接按照查询维度去查询聚合结果表,对其中关键的RoaringBitmap字段做or运算进行去重后并统计基数,即可得出对应用户数UV,count条数即可计算得出PV,达到亚秒级查询。
只需进行一次最细粒度的预聚合计算,也只生成一份最细粒度的预聚合结果表。得益于Hologres的实时计算能力,该方案下预计算所需的次数和空间都达到较低的开销。
Hologres计算UV、PV方案详情
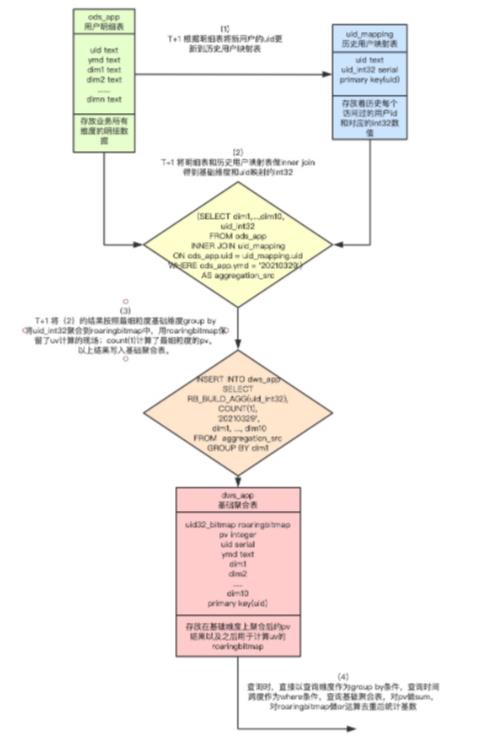
图1 Hologres基于RoaringBitmap计算pv uv流程
1.创建相关基础表
1)使用RoaringBitmap前需要创建RoaringBitmap extention,语法如下,同时该功能需要Hologres 0.10版本。
CREATE EXTENSION IF NOT EXISTS roaringbitmap;
2)创建表ods_app为明细源表,存放用户每天大量的明细数据 (按天分区),其DDL如下:
BEGIN;
CREATE TABLE IF NOT EXISTS public.ods_app (
uid text,
country text,
prov text,
city text,
channel text,
operator text,
brand text,
ip text,
click_time text,
year text,
month text,
day text,
ymd text NOT NULL
);
CALL set_table_property('public.ods_app', 'bitmap_columns', 'country,prov,city,channel,operator,brand,ip,click_time, year, month, day, ymd');
--distribution_key根据需求设置,根据该表的实时查询需求,从什么维度做分片能够取得较好效果即可
CALL set_table_property('public.ods_app', 'distribution_key', 'uid');
--用于做where过滤条件,包含完整年月日时间字段推荐设为clustering_key和event_time_column
CALL set_table_property('public.ods_app', 'clustering_key', 'ymd');
CALL set_table_property('public.ods_app', 'event_time_column', 'ymd');
CALL set_table_property('public.ods_app', 'orientation', 'column');
COMMIT;
3)创建表uid_mapping为uid映射表,uid映射表用于映射uid到32位int类型。
RoaringBitmap类型要求用户ID必须是32位int类型且越稠密越好(用户ID最好连续),而常见的业务系统或者埋点中的用户ID很多是字符串类型,因此使用uid_mapping类型构建一张映射表。映射表利用Hologres的SERIAL类型(自增的32位int)来实现用户映射的自动管理和稳定映射。
注: 该表在本例每天批量写入场景,可为行存表也可为列存表,没有太大区别。如需要做实时数据(例如和Flink联用),需要是行存表,以提高Flink维表实时JOIN的QPS。
BEGIN;
CREATE TABLE public.uid_mapping (
uid text NOT NULL,
uid_int32 serial,
PRIMARY KEY (uid)
);
--将uid设为clustering_key和distribution_key便于快速查找其对应的int32值
CALL set_table_property('public.uid_mapping', 'clustering_key', 'uid');
CALL set_table_property('public.uid_mapping', 'distribution_key', 'uid');
CALL set_table_property('public.uid_mapping', 'orientation', 'row');
COMMIT;
3)创建表dws_app基础聚合表,用于存放在基础维度上聚合后的结果
基础维度为之后进行查询计算pv和uv的最细维度,这里以country, prov, city为例构建聚合表
begin;
create table dws_app(
country text,
prov text,
city text,
ymd text NOT NULL, --日期字段
uid32_bitmap roaringbitmap, -- UV计算
pv integer, -- PV计算
primary key(country, prov, city, ymd)--查询维度和时间作为主键,防止重复插入数据
);
CALL set_table_property('public.dws_app', 'orientation', 'column');
--clustering_key和event_time_column设为日期字段,便于过滤
CALL set_table_property('public.dws_app', 'clustering_key', 'ymd');
CALL set_table_property('public.dws_app', 'event_time_column', 'ymd');
--distribution_key设为group by字段
CALL set_table_property('public.dws_app', 'distribution_key', 'country,prov,city');
end;
2.更新dws表及id_mapping表
每天从上一天的uid中找出新客户(uid映射表uid_mapping中没有的uid)插入到uid映射表中
WITH
-- 其中ymd = '20210329'表示上一天的数据
user_ids AS ( SELECT uid FROM ods_app WHERE ymd = '20210329' GROUP BY uid )
,new_ids AS ( SELECT user_ids.uid FROM user_ids LEFT JOIN uid_mapping ON (user_ids.uid = uid_mapping.uid) WHERE uid_mapping.uid IS NULL )
INSERT INTO uid_mapping SELECT new_ids.uid
FROM new_ids
;
更新完uid映射表后,将数据做聚合运算后插入聚合结果表,主要步骤如下:
- 首先通过源表inner join uid映射表,得到上一天的聚合条件和对应的uid_int32;
- 然后按照聚合条件做聚合运算后插入RoaringBitmap聚合结果表,作为上一天的聚合结果;
- 每天只需进行一次聚合,存放一份数据,数据条数最坏等于UV的量。以案例说明,明细表每天几亿的增量,在聚合结果表每天只需存放百万级数据。
WITH
aggregation_src AS( SELECT country, prov, city, uid_int32 FROM ods_app INNER JOIN uid_mapping ON ods_app.uid = uid_mapping.uid WHERE ods_app.ymd = '20210329' )
INSERT INTO dws_app SELECT country
,prov
,city
,'20210329'
,RB_BUILD_AGG(uid_int32)
,COUNT(1)
FROM aggregation_src
GROUP BY country
,prov
,city
;
3.UV、PV查询
查询时,从汇总表dws_app 中按照查询维度做聚合计算,查询bitmap基数,得出Group by条件下的用户数
--运行下面RB_AGG运算查询,可先关闭三阶段聚合开关性能更佳(默认关闭)
set hg_experimental_enable_force_three_stage_agg=off
--可以查询基础维度任意组合,任意时间段的uv pv
SELECT country
,prov
,city
,RB_CARDINALITY(RB_OR_AGG(uid32_bitmap)) AS uv
,sum(1) AS pv
FROM dws_app
WHERE ymd = '20210329'
GROUP BY country
,prov
,city;
--查一个月
SELECT country
,prov
,RB_CARDINALITY(RB_OR_AGG(uid32_bitmap)) AS uv
,sum(1) AS pv
FROM dws_app
WHERE ymd >= '20210301' and ymd <= '20210331'
GROUP BY country
,prov;
该查询等价于
SELECT country
,prov
,city
,COUNT(DISTINCT uid) AS uv
,COUNT(1) AS pv
FROM ods_app
WHERE ymd = '20210329'
GROUP BY country
,prov
,city;
SELECT country
,prov
,COUNT(DISTINCT uid) AS uv
,COUNT(1) AS pv
FROM ods_app
WHERE ymd >= '20210301' and ymd <= '20210331'
GROUP BY country
,prov;
4.可视化展示
计算出UV、PV和,大多数情况需要用BI工具以更直观的方式可视化展示,由于需要使用RB_CARDINALITY 和 RB_OR_AGG 进行聚合计算,需要使用BI的自定义聚合函数的能力,常见的具备该能力的BI包括Apache Superset和Tableau,下面将会讲述这两个BI工具的最佳实践。
4.1 使用 Apache Superset
Apache Superset 对接 Hologres 的方式,请参考产品手册。在Superset中可以直接使用dws_app表作为Dataset使用
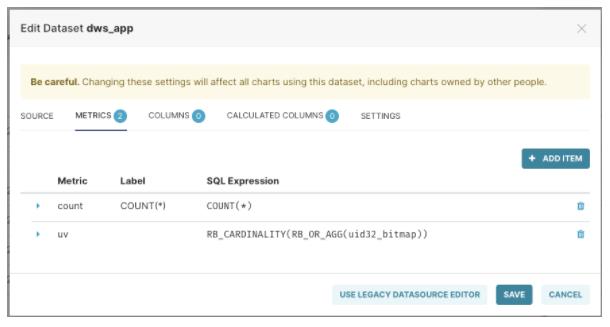
并且在数据集中,创建一个单独Metrics,名为UV,表达式如下:
RB_CARDINALITY(RB_OR_AGG(uid32_bitmap))
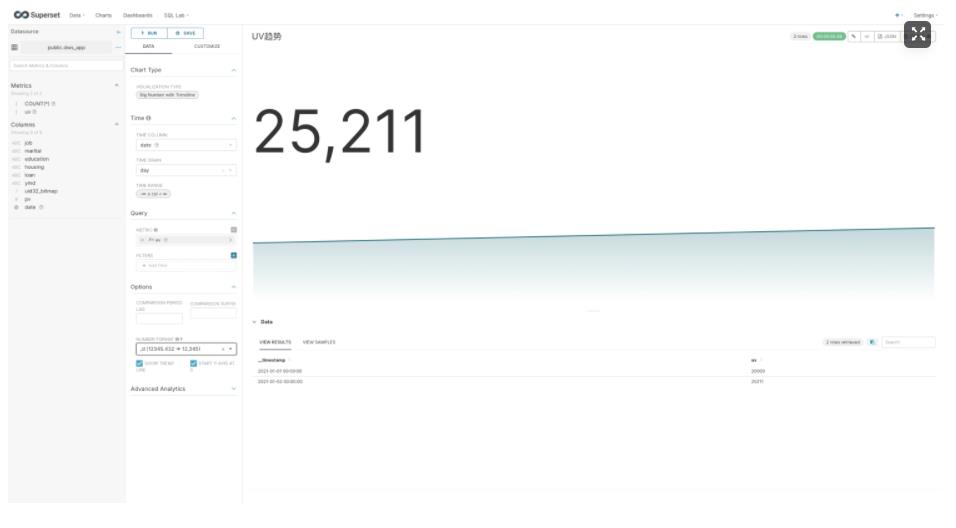
然后您就可以开始探索数据了
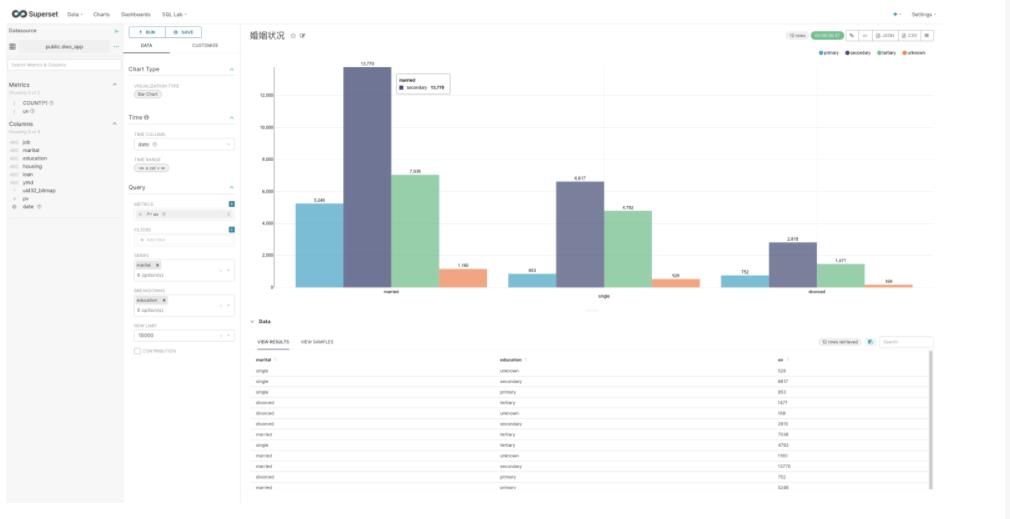
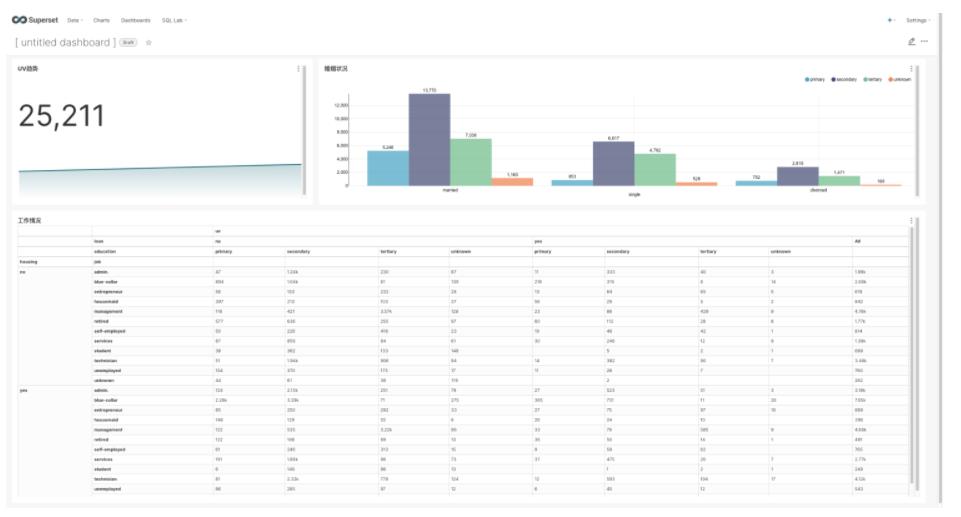
当然也可以创建Dashborad:
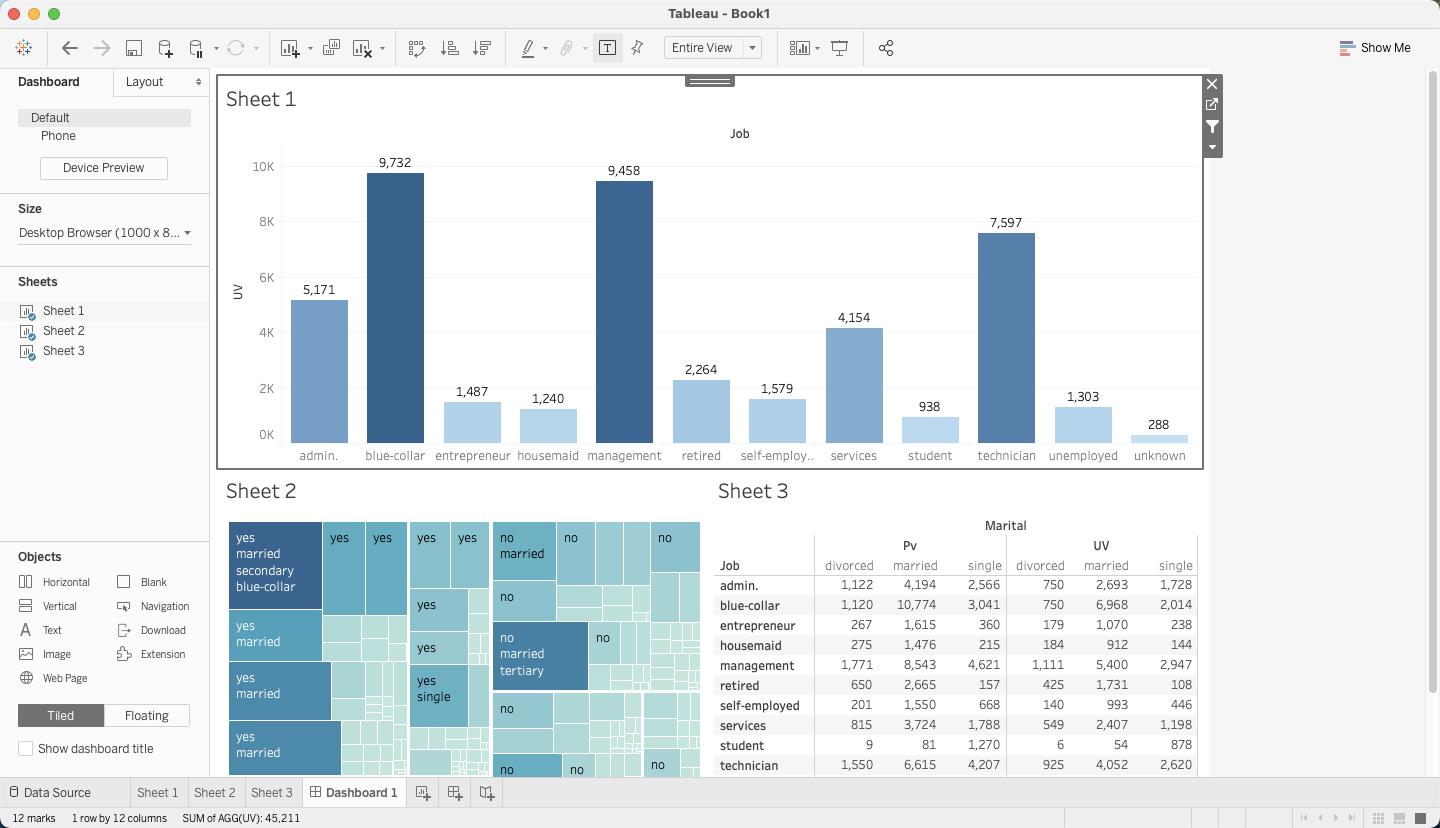
4.2 使用 Tableau
Tableau 对接 Hologres 的方式,请参考产品手册。可以使用Tableau的直通函数直接实现自定义函数的能力,详细介绍请参照Tableau的手册。在Tableau对接Hologres后,可以创建一个计算字段,表达式如下
RAWSQLAGG_INT("RB_CARDINALITY(RB_OR_AGG(%1))", [Uid32 Bitmap])
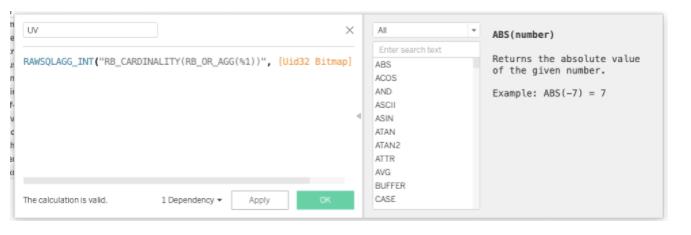
然后您就可以开始探索数据了
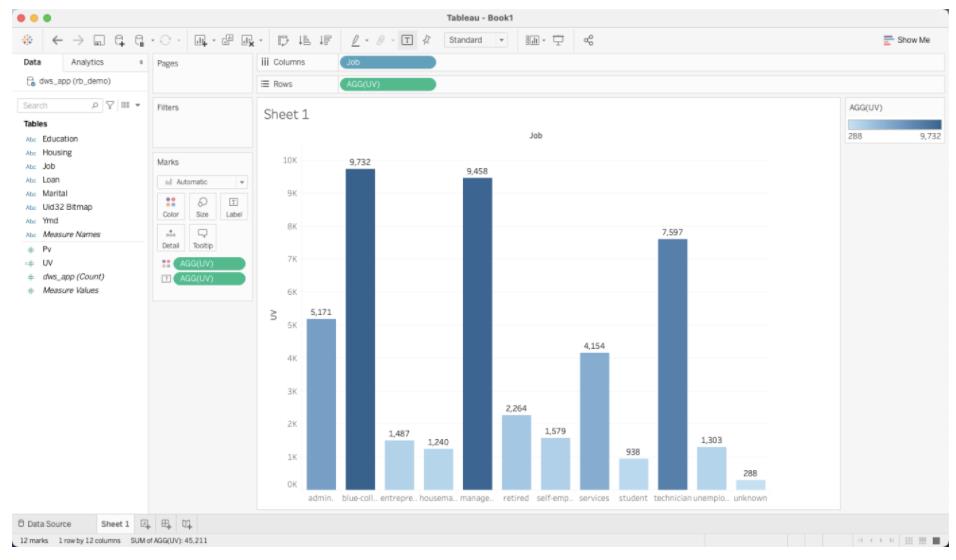
当然也可以创建Dashborad
本文为阿里云原创内容,未经允许不得转载。
以上是关于Hologres如何支持超高基数UV计算(基于roaringbitmap实现)的主要内容,如果未能解决你的问题,请参考以下文章
Flink+Hologres亿级用户实时UV精确去重最佳实践
Hologres揭秘:如何支持超高QPS在线服务(点查)场景
Hologres揭秘:如何支持超高QPS在线服务(点查)场景