实时计算 Flink 版总体介绍
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时计算 Flink 版总体介绍相关的知识,希望对你有一定的参考价值。
本文整理自直播《实时计算 Flink 版总体介绍 》
视频链接:https://developer.aliyun.com/learning/course/795
Apache Flink技术发展
大数据的高速发展已经超过10年,大数据也正在从计算规模化向更加实时化的趋势演进。
比如阿里巴巴举办的购物狂环节双11,可以通过实时大屏展示整个双11实时的交易额、成交额,并可实现毫秒级的更新;全球华人都会观看的中央电视台春节联欢晚会,可以通过春晚大屏,实时统计全国的收视率与观众画像;现在多个城市都有的城市大脑项目,通过 IoT的摄像头信息,实时捕获各个城市中的交通、车辆、人流等信息去做交通的监察和治理;还有金融行业,在银行、证券交易所等机构的核心业务场景下,也都在通过大数据实时计算能力实时监控交易行为,进行反作弊反洗钱等行为的探测;除此之外,在整个淘宝电商交易的场景下,实时根据用户的行为进行个性化推荐,基于用户在前一分钟或者30秒内浏览商品情况,在后续的浏览中系统就会根据算法测算用户画像,然后实时向用户推荐可能会喜欢的相关商品等。可以说这么多日常生活中涉及的场景,背后都是由实时计算在推动生产力的提升,日夜不息。
实时计算需要后台有一套极其强大的大数据计算能力,Apache Flink作为一款开源大数据实时计算技术应运而生。它从设计之初就由流计算开启,因为传统的Hadoop、Spark等计算引擎,本质上是批计算引擎,通过对有限的数据集进行数据处理,其处理延时性是不能保证的。而Apache Flink作为流式计算引擎,它可以实时订阅实时产生的现实数据,并实时对数据进行分析处理并产生结果,让数据在第一时间发挥价值。
目前Apache Flink也从流计算的引擎逐渐拥有流批一体的计算能力,可以通过日志流,点击流,IoT数据流等进行流式的分析处理,同时也可以对数据库和文件系统中的文件等有限数据集进行批式的数据处理,快速分析结果。Apache Flink 现在是开源社区中非常流行的一个开源大数据技术,并且连续三年成为Apache开源项目中全球活跃度最高的项目之一。它具备强一致性的计算能力、大规模的扩展性,整体性能非常卓越,同时支持SQL、Java、Python等多语言,拥有丰富的API接口方便各种场景业务使用。目前国内外互联网企业中Flink已经成为主流的实时大数据计算技术,是实时计算领域的事实技术标准。
阿里云实时计算 Flink 版产品,在阿里巴巴集团内部历经多年锤炼和验证,积累了丰富的技术和产品,现已经提供到云上,为各行各业中小企业提供云计算服务。早在2016年,Apache Flink刚刚捐献给Apache之后的第三年,阿里已经开始大规模上线使用实时计算产品了。这个产品最早上线于阿里最核心的搜索推荐以及广告业务场景,在这个场景下我们需要大量的数据实时化的处理,比如实时推荐、实时排序、实时广告等,对整个电商的核心业务有非常大的提升。

2017年,基于 Flink 的实时计算平台产品,开始服务于整个阿里巴巴集团,同年双11服务全集团的数据实时化,包括最核心的双11的大屏。在2018年产品正式上云,不仅服务集团内,同时开始服务云上中小企业,这也是第一次将实时计算 Flink 的产品以公共云的形式对外提供服务。
2019年初,阿里巴巴收购了 Flink 的创始公司 - Ververica,阿里的 Flink 技术团队-实时计算技术团队和德国总部的Flink创始团队顺利会师,成为了全球 Flink 技术最强的团队,也共同推进了整个Apache Flink 开源社区的发展和贡献。目前中国Apache Flink社区有超过20w的开发者参与到社区中,Flink成为Apache基金会大数据领域最活跃的项目之一。
去年,在全球主流的云计算公司和大数据公司,都大量采用 Flink 的技术推出了自己的 Flink 产品。比如借Hadoop起家的Cloudera也推出全面集成了 Flink 的CDP/CDH,国内的大数据公司也陆续推出了基于 Flink 的实时计算产品。
实时计算Flink版产品架构
阿里云的实时计算产品架构和开源版本相比较,有很大的提高和增值。现在很多开发者在自建机房或者云上虚拟机作业时都会使用开源的Apache Flink 去搭建自己的实时计算平台。那么阿里云官方推出的实时计算Flink产品,它的特色是什么呢?

根据整个产品的架构图,最底层是基于阿里云的完善的云原生的基础设施,通过容器化来构建一套实时计算 Flink 的产品,所有的 Flink 的计算任务都运行在Kubernetes的生态之上,以容器化的方式进行多租户的隔离,保障安全。同时它又是全托管的服务形态,在云上提供高SLA保证的全托管服务,免除用户运维的烦恼。并搭配service架构,用户可以更灵活的判断各类资源的占比,完全配合自己的业务量来选择,无需为机器的规划而烦恼。实时计算 Flink 版产品是一套天然的云原生基础架构。
在核心计算引擎上,相对于开源的Apache Flink 阿里云进行了多处核心功能的优化,这些优化也通过了阿里内部业务的锤炼。目前实时计算 Flink 产品,支持了阿里集团将近100个事业部的实时数据服务。通过大量业务实践,产品在支持存储,调度、网络传输等方面,都调试到最佳效果。
插件方面,产品内置几十种增强型的Connector,可以对接所有主流的开源数据存储包括云上像mysql、 HBase、HDFS、阿里云SLS等,天然集成、开箱即用。开发平台方面,提供企业级的一站式的开发平台,自带开发和运维能力,免除自建烦恼,提高企业用户整体使用感受。
实时计算 Flink版支持SQL、Java、Python 等多语言开发环境,提供开发任务的全生命周期管理,可支持基于OIDC和RBAC的企业级安全机制,并且拥有基于Prometheus协议的全链路监控报警,同时提供自有AutoPilot的智能调优系统,智能地帮助用户去对 Flink 任务进行参数的调优,包括资源的调优和并发度的调优。产品完全可以去自适应业务的流量,不需要人工做任何的调试(智能调优是实时计算Flink版产品的核心优势)。
实时计算Flink版与开源Apache Flink的区别
实时计算 Flink 版的产品相对于开源产品,具有数10项的性能优势,通过开发、运维、成本、安全等角度进行对比。
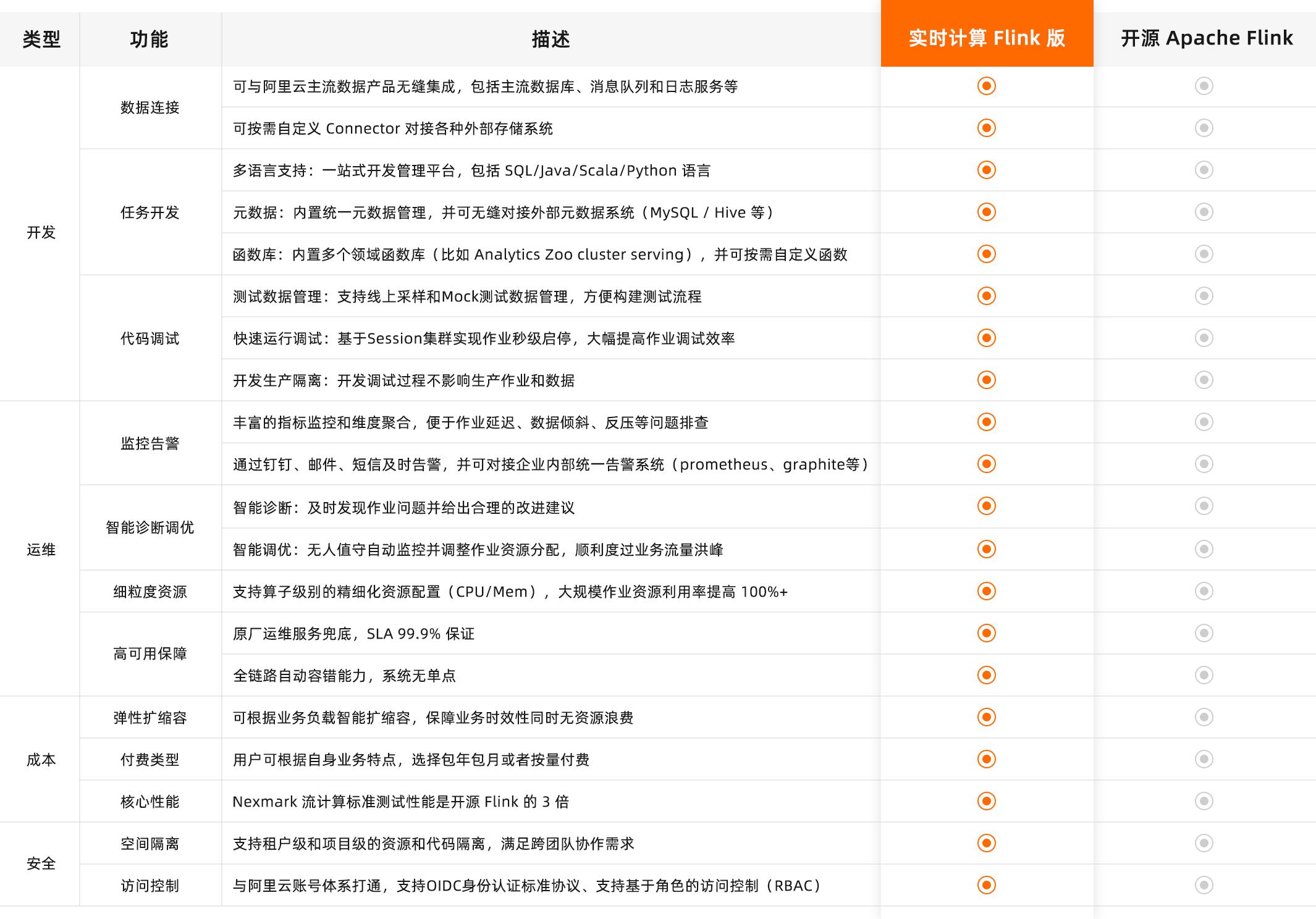
开发方面具备丰富的数据连接能力和一站式的多语言的开发环境,内置多种函数库,方便用户进行代码调试,还可以进行多租户的开发,任务的调试,测试的模拟等等。运维方面支持全链路的监控报警,用户在使用过程中出现的数据延迟、数据异常、服务中断等都可以进行自动报警。
智能运维方面支持自动化的智能诊断和调优,能够根据业务流量自动帮用户进行性能调优、作业调优、参数调优和资源调优等,针对问题可以进行诊断优化。资源层面在开源的基础上,做到了更细粒度和更精细化的资源的调配,使得每个作业每个算子都可以在CPU和内存粒度上进行配置,大幅优化资源的利用率,帮助用户节省成本,提升服务的稳定性,降低OM的概率。搭配原厂的运维兜底服务,SLA 99.9%的保证,以及全链路的容错能力,系统稳定性的保证,充分解决用户后顾之忧。
成本层面,通过云上成本优化,在性能提升的同时降低用户整体的TCO,这也是核心性能的优势。
基于NexMark的流计算的标准测试中,实时计算 Flink 版的产品性能约为开源的3倍,依托阿里集团强大的研发团队在内部核心业务场景下积累的实践优化,使得产品在降低用户的基础成本上,突出核心优势。
实时计算Flink版还具备云原生的弹性扩容能力,可帮助用户合理地节省资源,提高资源利用率。产品付费类型支持包年包月付费,也支持按量付费,更好地适配不同需求。
安全层面通过容器化的任务隔离,提高用户使用感受,并且支持租户隔离、安全隔离、VPC隔离等等多种需求。同时与阿里的账号体系直接打通,用户可以基于阿里云的账号无缝进行产品之间的安全管控,也支持基于角色、OIDC这种开放的身份认证协议,大大提高业务的安全性。
整体来说,企业版相对于开源版具有更优势的功能性和稳定性,除了运维方面的优势,开箱即用也让用户更加方便。
产品解决方案
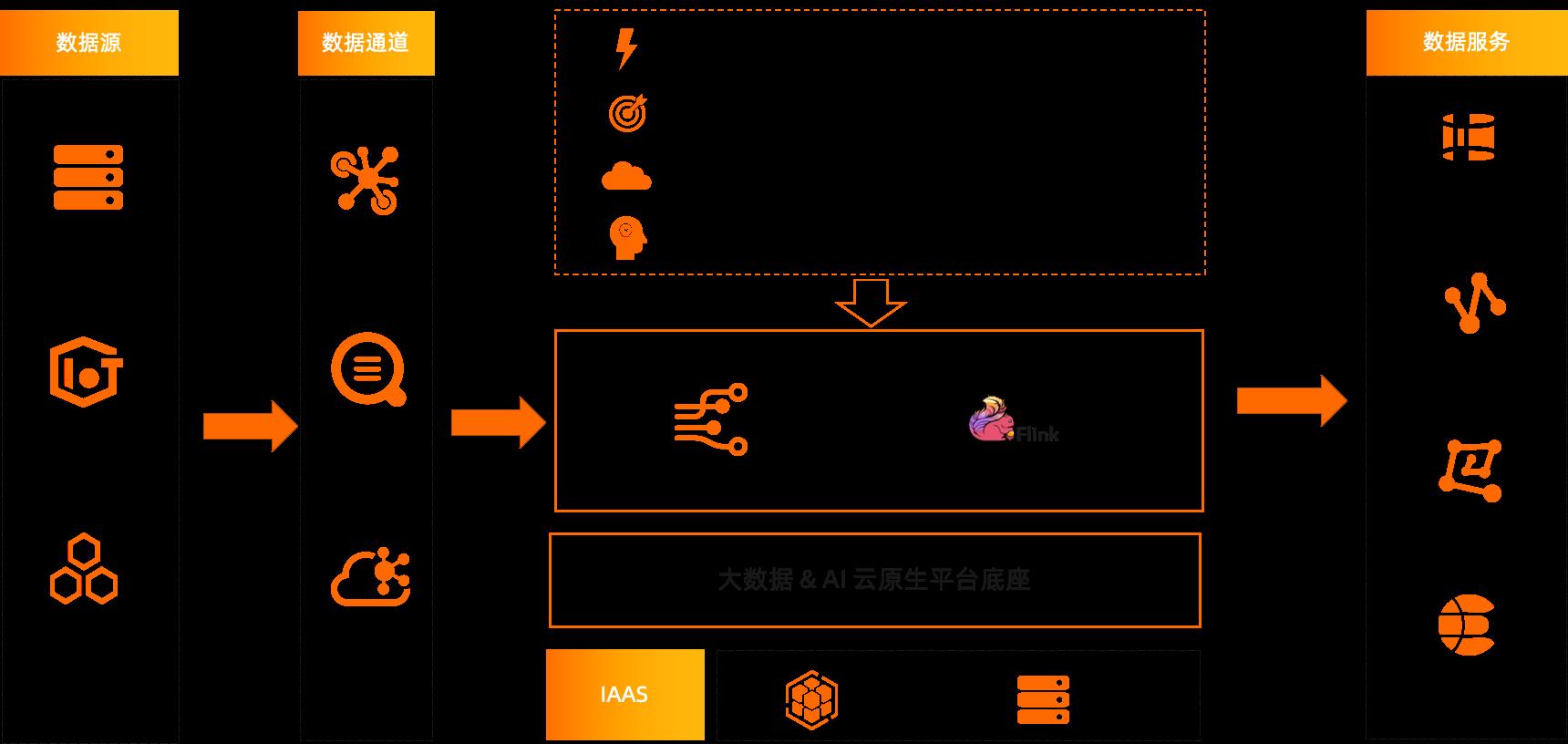
Flink 作为实时计算的一个流式计算引擎,可以处理多种实时数据,包括ECS在线服务日志,IoT场景下传感器数据等各类实时数据。同时可以订阅云上数据库RDS、PolarDB等这种关系型数据库中 binlog的更新。再通过DataHub数据总线产品、SLS日志服务、开源的Kafka消息队列产品等将实时数据进行订阅,收录进实时计算产品中,进行实时的数据分析和处理。最终将分析结果写入不同的数据服务中,比如MaxCompute、MaxCompute-Hologres交互式分析、PAI机器学习、Elasticsearch等产品中,根据业务需求选择最佳数据服务产品,提高数据利用率。
Flink主要的应用场景就是将各种不同的实时数据源中的数据进行实时的订阅、处理、分析,并把得到的结果写入到其他的在线存储之中,让用户直接生产使用。整个系统具有速度快,数据准,云原生架构以及智能化等特点,是一款非常具有竞争力的企业级的产品。产品运行在阿里云的容器服务ECS等IaaS系统上,跟阿里云的各项系统天然打通,方便客户适用更多场景。
产品应用场景
基于实时计算 Flink 版产品总结出4大应用场景,方便用户根据需求轻松构建自己的业务实时计算解决方案。

1、实时数仓
实时数仓主要应用在网站pv/uv统计、商品销量统计、交易数据统计等各类交易型数据场景中。通过订阅业务实时数据源,将信息实时秒级分析,最终呈现在大屏幕中给决策者使用,方便判断企业经营状况和活动促销的情况。根据实时的商业运营数据作出决策,做到真正数据智能。因场景的特殊性,实时数据尤为重要,在瞬息万变的业务互动中需要对上一分钟甚至上一秒钟发生的数据进行分析决策,实时计算是这种场景下最好的选择。
2、实时推荐
实时推荐主要是根据用户喜好进行个性化推荐或者基于AI技术进行推荐,是一个主流的产品形态。常见于短视频场景,电商购物场景,内容资讯场景等,通过之前的用户点击情况实时判断用户喜好,从而进行针对性推荐,增加用户粘性。这种是实时性非常强的场景,可以通过Flink 技术结合AI技术进行实时推荐场景的运作。
3、ETL场景
实时的ETL场景常见于数据同步作业中,在数据同步的过程中还要做数据计算处理。比如数据库中不同表的同步、转化、不同数据库的同步,或者是进行数据聚合预处理等操作。最终将结果写入数仓/数据湖进行归档沉淀,为后续深度分析进行前期准备工作,方便用户进行后续的日志类分析等操作。在整个的数据同步和处理链路上,基于 Flink 做这种实时化数据的同步和预处理是非常高效的。
4、实时监控
实时监控常见于金融类或者是交易类业务场景下,针对行业的独特性,需要有商业化的反作弊监管,根据实时短时间之内的行为,判定用户是否为作弊用户,做到及时止损。该场景对时效性要求极高,通过对异常数据检测,可以实时发现异常情况而做出一个止损的行为。收集 指标或者日志等统计各个系统的指标,对指标进行实时的观察和监控等等需求场景,都是可以通过实时计算 Flink 产品解决的。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于实时计算 Flink 版总体介绍的主要内容,如果未能解决你的问题,请参考以下文章
袋鼠云:基于Flink构建实时计算平台的总体架构和关键技术点
如何迁移开源 Flink 任务到实时计算Flink版?实战手册来帮忙!