ML机器学习|KMeans聚类算法|EM算法
Posted 筝自然语言处理与推荐算法
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ML机器学习|KMeans聚类算法|EM算法相关的知识,希望对你有一定的参考价值。
算法演示和完整代码见文末,下一期将带来ML中经典的C4.5决策树算法。
-
读者闲聊 背景介绍
主要理论
数据清单
分词工具
工程复现
动态演示
-
优化展望
EM算法: 全称Expectation Maximum,指最大期望算法。是通过极大似然估计进行迭代的优化算法。迭代分为E和M两步轮流进行,E步就是求当前的期望,M步是求当前的极大似然估计。
聚类算法:
顾名思义,物以类聚,指由聚类算法生成多组数据的集合 ,每组数据与同一个集合中的数据彼此相似,与其他集合中的数据相异。 KMeans算法:
K均值聚类算法是最著名的划分聚类算法,由于简洁和效率使得它成为最广泛使用的聚类算法,在业务上常用来对用户群体进行划分加强业务算法效率和性能。
Name: Euclidean Distance
Model: KMeans Clustering

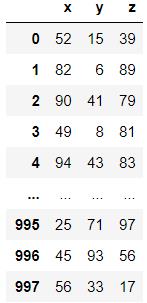
工程复现
""" Import the basic requirements package """import time
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
配置数据集导出函数
""" Dataset export function """
def read_csv():
X = np.random.randint(low=1, high=100, size=(800, 3))
print(X.shape) # Print feature set and label set length
return context""" Euclidean distance function """
def distance(x, y):
y = y.values
x_C_dis = np.sqrt(np.sum(np.power(x - y, 2), axis=1))
return x_C_dis""" K vectors calculation function """
def calc_k_vectors(data, k):
C_set = []
for c in range(k):
C_set.append(data[data['C'] == c][['x', 'y', 'z']].mean().values)
k_vectors = np.vstack(tuple(C_set))
return k_vectors""" KMeans model function """
# create model
def KMeans(k=10):
kmeans_params = {
'k': k, # Set the base of the kmeans logarithm
}
return kmeans_params
# fit model
def fit(kmeans_params, X):
data = pd.DataFrame(X, columns=['x', 'y', 'z'])
k_index = data.sample(n=kmeans_params['k'], random_state=1).index # Initialize K randomly selected points
k_vector = data[['x', 'y', 'z']].iloc[k_index].values
ax = Axes3D(plt.figure(figsize=(9, 7.5)))
plt.ion()
for i in range(100):
data['C'] = data[['x', 'y', 'z']].apply(lambda row: np.argmin(distance(k_vector, row)), axis=1)
k_vector = calc_k_vectors(data, kmeans_params['k'])
# Initialize K randomly selected points
ax.cla()
for c in range(kmeans_params['k']):
tmp = data[data['C'] == c]
ax.scatter(tmp['x'], tmp['y'], tmp['z'], label='C' + str(c))
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')
ax.set_title('KMeans training...' + str(i) + ':')
plt.legend()
plt.pause(0.6)
plt.ioff()
plt.show()
return data""" KMeans model training host process """
if __name__ == '__main__':
sta_time = time.time()
X = read_csv()
model = KMeans(k=4)
KMeans_x= fit(model, X)
print("Time:", time.time() - sta_time)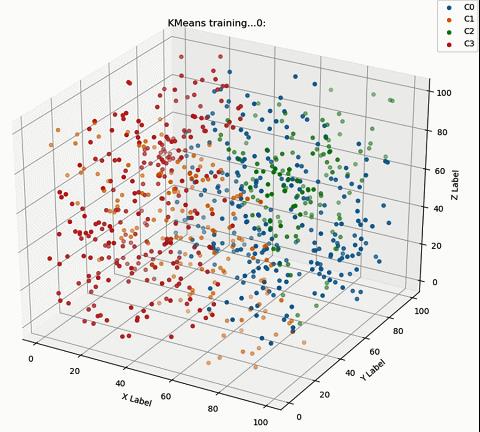
总结展望
KMeans的K值选取同上篇文章PCA降维算法,可以使用累计方差贡献率作为评估指标,也就是手肘法。
KMeans的K点选取初始化对聚类结果影响重大,本文采用随机选择初始化,可以根据正态高斯分布使K点选取初始化。
业务中KMeans算法的使用目的并不是将目标精确区分,而是为了聚类对不同类别进行模型训练,增进模型效率和性能。
KMeans采用的是欧氏距离公式,是一种线性聚类算法,对于现实世界中的非线性数据往往无从下手,可以尝试采用非线性聚类如DBSCAN算法。
Github Code后台回复"KMEANS"获取完整代码
参考链接
Cvcr
https://www.termonline.cn/search?k=cumulative%20variance%20contribution%20rate&r=1623741786660
DBSCAN
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html

扫描二维码获取
更多精彩
筝自然语言处理和推荐算法
Github Code后台回复"KMEANS"获取完整代码
Cvcr
DBSCAN
扫描二维码获取
更多精彩
筝自然语言处理和推荐算法
以上是关于ML机器学习|KMeans聚类算法|EM算法的主要内容,如果未能解决你的问题,请参考以下文章
如何利用kmeans将数据更加准确地聚类---利用隐含变量最佳类别(EM算法思想)实现
转:机器学习sklearn19.0聚类算法——Kmeans算法